前言:
规则引擎中, 往往涉及到多个条件构成了复杂布尔表达式的计算. 对于这类布尔表达式, 一是动态可变的(取决于运营人员的设定), 二是其表达式往往很复杂. 如何快速的计算其表达式的值, 该系列文章将以两种方式, Antlr4动态生成AST(抽象语法树), 以及Groovy动态编译的方式来对比评估, 看看哪种方式性能更优, 以及各自的优缺点. 本篇文章将侧重于介绍Antlr4的实现思路.
模型简化:
每个规则可以理解为多个条件构建的复杂布尔表达式, 而条件本身涉及不同的变量和阈值(常量), 以及中间的操作符(>=, >, <, <=, !=, =).
比如某个具体的规则:
rule = expr1 && (expr2 || expr3) || expr4
而其具体条件expr1/expr2/expr3/expr4如下:
expr1 => var1 >= 20 expr2 => var2 != 10 expr3 => var3 < 3.0 expr4 => var4 = true
为了简化评估, 我们简单设定每个条件就是一个布尔变量(bool). 这样每个规则rule就可以理解为多个布尔变量, 通过&&和||组合的表达式了, 简单描述为:
rule = 1 && (2 || 3) || 4
数字N(1,2,...)为具体的布尔变量, 类似这样的简化模型, 方便性能评估.
Antlr4构建:
Anltr4是基于LL(K), 以递归下降的方式进行工作. 它能自动完成语法分析和词法分析过程,并生产框架代码.
具体可参阅文章: 利用ANTLR4实现一个简单的四则运算计算器, 作为案列参考.
其实表达式解析比四则混合运算的语法gammar还要简单.
编写EasyDSL.g4文件:
grammar EasyDSL;
/** PARSER */
line : expr EOF ;
expr
: '(' expr ')' # parenExpr
| expr '&&' expr # andEpr
| expr '||' expr # orEpr
| ID # identifier
;
/** LEXER */
WS : [
]+ -> skip ;
ID : DIGIT+ ;
fragment DIGIT : '0'..'9';
其在idea工程中, 如下所示:
配置pom.xml, 添加dependency和plugin.
<dependencies>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.3</version>
</dependency>
</dependencies>
<plugins>
<build>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.3</version>
<executions>
<execution>
<id>antlr</id>
<goals>
<goal>antlr4</goal>
</goals>
<!--<phase>none</phase>-->
</execution>
</executions>
<configuration>
<outputDirectory>src/main/java</outputDirectory>
<listener>true</listener>
<treatWarningsAsErrors>true</treatWarningsAsErrors>
</configuration>
</plugin>
</plugins>
</build>
具体执行命令
mvn antlr4:antlr4
则生成对应的代码
代码扩展:
Antlr4帮我们构建了基础的词法和语法解析后, 后续工作需要我们自己做些功能扩展.
首先我们定义操作枚举类:
package com.dsl.perfs;
public enum ExprType {
AND,
OR,
ID;
}
然后是具体的节点类:
package com.dsl.perfs;
public class ExprNode {
public ExprType type;
public String id;
public ExprNode left;
public ExprNode right;
public ExprNode(ExprType type, String id, ExprNode left, ExprNode right) {
this.type = type;
this.id = id;
this.left = left;
this.right = right;
}
}
最后重载Listener类, 对这可抽象语法树进行构建.
package com.dsl.perfs;
import com.dsl.ast.EasyDSLBaseListener;
import com.dsl.ast.EasyDSLParser;
import org.antlr.v4.runtime.misc.NotNull;
import java.util.Stack;
public class EasyDSLListener extends EasyDSLBaseListener {
private Stack<ExprNode> stacks = new Stack<>();
@Override
public void exitIdentifier(@NotNull EasyDSLParser.IdentifierContext ctx) {
stacks.push(new ExprNode(ExprType.ID, ctx.getText(), null, null));
}
@Override
public void exitAndEpr(@NotNull EasyDSLParser.AndEprContext ctx) {
ExprNode right = stacks.pop();
ExprNode left = stacks.pop();
stacks.push(new ExprNode(ExprType.AND, null, left, right));
}
@Override
public void exitOrEpr(@NotNull EasyDSLParser.OrEprContext ctx) {
ExprNode right = stacks.pop();
ExprNode left = stacks.pop();
stacks.push(new ExprNode(ExprType.OR, null, left, right));
}
@Override
public void exitLine(@NotNull EasyDSLParser.LineContext ctx) {
super.exitLine(ctx);
}
@Override
public void exitParenExpr(@NotNull EasyDSLParser.ParenExprContext ctx) {
// DO NOTHING
}
public ExprNode getResult() {
return stacks.peek();
}
}
以下是工具类, 其具体构建AST, 并进行具体的值评估.
package com.dsl.perfs;
import com.dsl.ast.EasyDSLLexer;
import com.dsl.ast.EasyDSLParser;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ExprEvalutorHelper {
private static ConcurrentHashMap<String, ExprNode> exprAstClassMap = new ConcurrentHashMap();
public static boolean exec(String expr, Map<String, Boolean> params) {
ExprNode root = exprAstClassMap.get(expr);
if ( root == null ) {
synchronized (expr.intern()) {
if ( root == null ) {
EasyDSLLexer lexer = new EasyDSLLexer(new ANTLRInputStream(expr));
/* 根据lexer 创建token stream */
CommonTokenStream tokens = new CommonTokenStream(lexer);
/* 根据token stream 创建 parser */
EasyDSLParser paser = new EasyDSLParser(tokens);
/* 为parser添加一个监听器 */
EasyDSLListener listener = new EasyDSLListener();
paser.addParseListener(listener);
/* 匹配 line, 监听器会记录结果 */
paser.line();
root = listener.getResult();
exprAstClassMap.put(expr, root);
}
}
}
return ExprEvalutorHelper.evalute(root, params);
}
public static boolean evalute(ExprNode cur, Map<String, Boolean> params) {
if ( cur.type == ExprType.ID ) {
return params.get(cur.id);
} else {
if ( cur.type == ExprType.AND ) {
boolean leftRes = evalute(cur.left, params);
// *) 剪枝优化
if ( leftRes == false ) return false;
boolean rightRes = evalute(cur.right, params);
return leftRes && rightRes;
} else {
// *) 如果为 OR
boolean leftRes = evalute(cur.left, params);
// *) 剪枝优化
if ( leftRes == true ) return true;
boolean rightRes = evalute(cur.right, params);
return leftRes || rightRes;
}
}
}
}
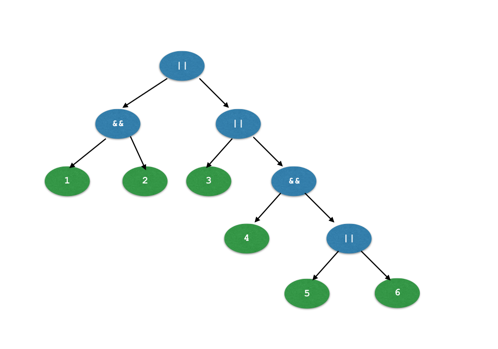
以表达式
1 && 2 || 3 || 4 && (5 || 6)
为例, 其最后最后的AST树如下所示:
测试评估:
编写如下测试代码, 来进行性能评估:
package com.dsl.comp;
import com.dsl.perfs.ExprEvalutorHelper;
import java.util.Map;
import java.util.Random;
import java.util.TreeMap;
public class AntlrPerf {
public static void main(String[] args) {
String boolExpr = "1 && 2 || 3 || 4 && (5 || 6)";
int iterNums = 1000000;
long randomSeed = 10001L;
Random random = new Random(randomSeed);
Long beg = System.currentTimeMillis();
for ( int i = 0; i<=iterNums; i++ ) {
Map<String, Boolean> params = new TreeMap<>();
params.put("1", random.nextBoolean());
params.put("2", random.nextBoolean());
params.put("3", random.nextBoolean());
params.put("4", random.nextBoolean());
params.put("5", random.nextBoolean());
params.put("6", random.nextBoolean());
ExprEvalutorHelper.exec(boolExpr, params);
}
long end = System.currentTimeMillis();
System.out.println(String.format("total consume: %dms", end - beg));
}
}
测试结果如下:
total consume: 755ms
100万次计算, 累计消耗755ms, 似乎不错. 但是具体的性能好坏, 需要对比, 下篇将使用Groovy方式去实现, 并进行对比.
总结:
文章介绍了Antlr去解析评估复杂布尔表达式的思路, 其性能也相当的客观, 下文将介绍Groovy的方式去评估, 看看两者性能差异, 以及优缺点.