什么是作用域?
作用域是一种规则,在代码编译阶段就确定了,规定了变量与函数的可被访问的范围。全局变量拥有全局作用域,局部变量则拥有局部作用域。 js是一种没有块级作用域的语言(包括if、for等语句的花括号代码块或者单独的花括号代码块都不能形成一个局部作用域),所以js的局部作用域的形成有且只有函数的花括号内定义的代码块形成的,既函数作用域。
什么是作用域链?
作用域链是作用域规则的实现,通过作用域链的实现,变量在它的作用域内可被访问,函数在它的作用域内可被调用。
作用域链是一个只能单向访问的链表,这个链表上的每个节点就是执行上下文的变量对象(代码执行时就是活动对象),单向链表的头部(可被第一个访问的节点)始终都是当前正在被调用执行的函数的变量对象(活动对象),尾部始终是全局活动对象。
作用域链的形成?
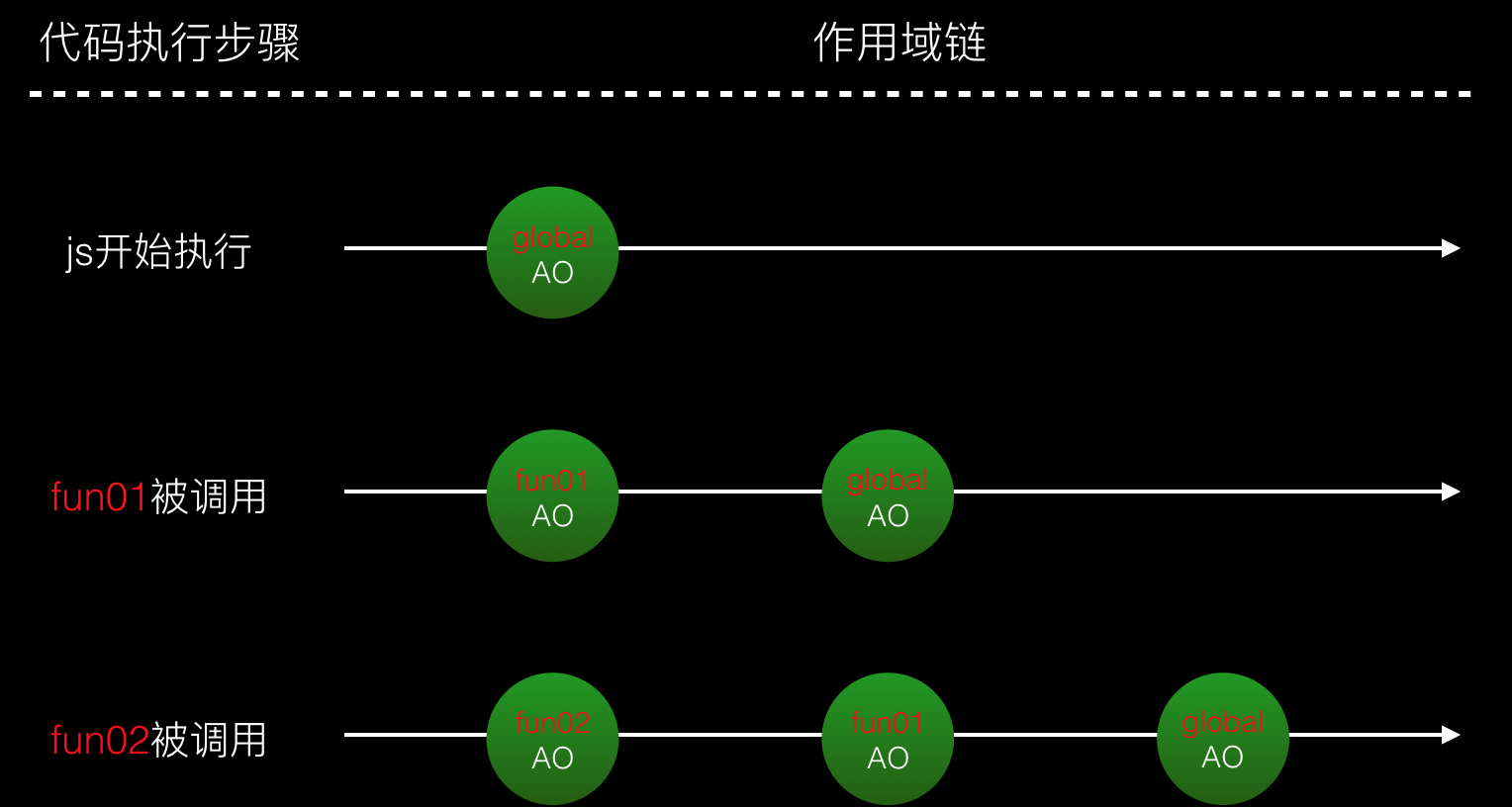
我们从一段代码的执行来看作用域链的形成过程。

1 function fun01 () {
2 console.log('i am fun01...');
3 fun02();
4 }
5
6 function fun02 () {
7 console.log('i am fun02...');
8 }
9
10 fun01();
数据访问流程
如上图,当程序访问一个变量时,按照作用域链的单向访问特性,首先在头节点的AO中查找,没有则到下一节点的AO查找,最多查找到尾节点(global AO)。在这个过程中找到了就找到了,没找到就报错undefined。
延长作用域链
从上面作用域链的形成可以看出链上的每个节点是在函数被调用执行是向链头unshift进当前函数的AO,而节点的形成还有一种方式就是“延长作用域链”,既在作用域链的头部插入一个我们想要的对象作用域。延长作用域链有两种方式:
1.with语句
1 function fun01 () {
2 with (document) {
3 console.log('I am fun01 and I am in document scope...')
4 }
5 }
6
7 fun01();

2.try-catch语句的catch块
1 function fun01 () {
2 try {
3 console.log('Some exceptions will happen...')
4 } catch (e) {
5 console.log(e)
6 }
7 }
8
9 fun01();

ps:个人感觉with语句使用需求不多,try-catch的使用也是看需求的。个人对这两种使用不多,但是在进行这部分整理过程中萌发了一点点在作用域链层面的不成熟的性能优化小建议。
由作用域链引发的关于性能优化的一点不成熟的小建议
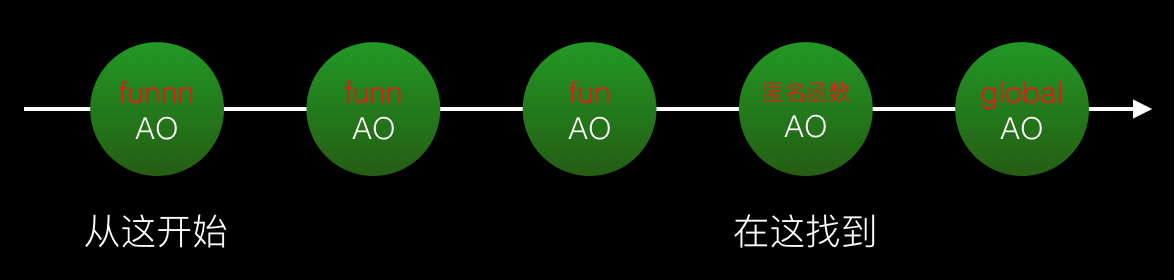
1.减少变量的作用域链的访问节点
这里我们自定义一个名次叫做“查找距离”,表示程序访问到一个非undefined变量在作用域链中经过的节点数。因为如果在当前节点没有找到变量,就跳到下一个节点查找,还要进行判断下一个节点中是否存在被查找变量。“查找距离”越长,要做的“跳”动作和“判断”动作也就越多,资源开销就越大,从而影响性能。这种性能带来的差距可能少数的几次变量查找操作不会带来太多性能问题,但如果是多次进行变量查找,性能对比则比较明显了。
1 (function(){
2 console.time()
3 var find = 1 //这个find变量需要在4个作用域链节点进行查找
4 function fun () {
5 function funn () {
6 var funnv = 1;
7 var funnvv = 2;
8 function funnn () {
9 var i = 0
10 while(i <= 100000000){
11 if(find){
12 i++
13 }
14 }
15 }
16 funnn()
17 }
18 funn()
19 }
20 fun()
21 console.timeEnd()
22 })()
1 (function(){
2 console.time()
3 function fun () {
4 function funn () {
5 var funnv = 1;
6 var funnvv = 2;
7 function funnn () {
8 var i = 0
9 var find = 1 //这个find变量只在当前节点进行查找
10 while(i <= 100000000){
11 if(find){
12 i++
13 }
14 }
15 }
16 funnn()
17 }
18 funn()
19 }
20 fun()
21 console.timeEnd()
22 })()
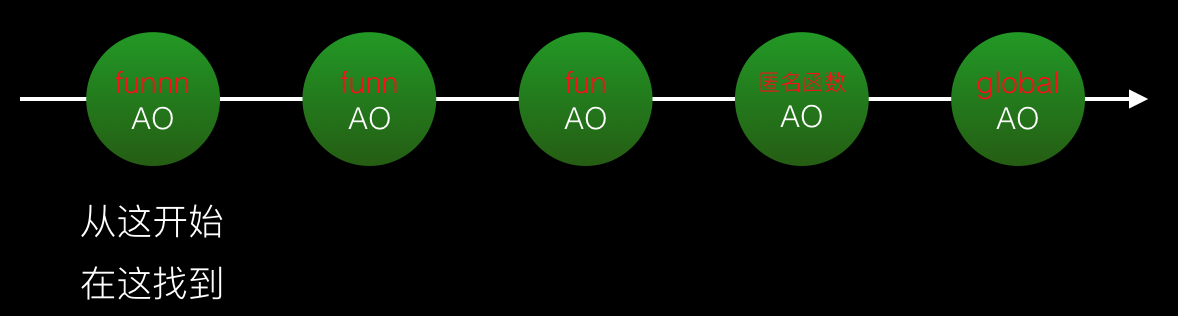
在mac pro的chrome浏览器下做实验,进行1亿次查找运算。
实验结果:前者运行5次平均耗时85.599ms,后者运行5次平均耗时63.127ms。
2.避免作用域链内节点AO上过多的变量定义
过多的变量定义造成性能问题的原因主要是查找变量过程中的“判断”操作开销较大。我们使用with来进行性能对比。
1 (function(){
2 console.time()
3 function fun () {
4 function funn () {
5 var funnv = 1;
6 var funnvv = 2;
7 function funnn () {
8 var i = 0
9 var find = 10
10 with (document) {
11 while(i <= 1000000){
12 if(find){
13 i++
14 }
15 }
16 }
17 }
18 funnn()
19 }
20 funn()
21 }
22 fun()
23 console.timeEnd()
24 })()
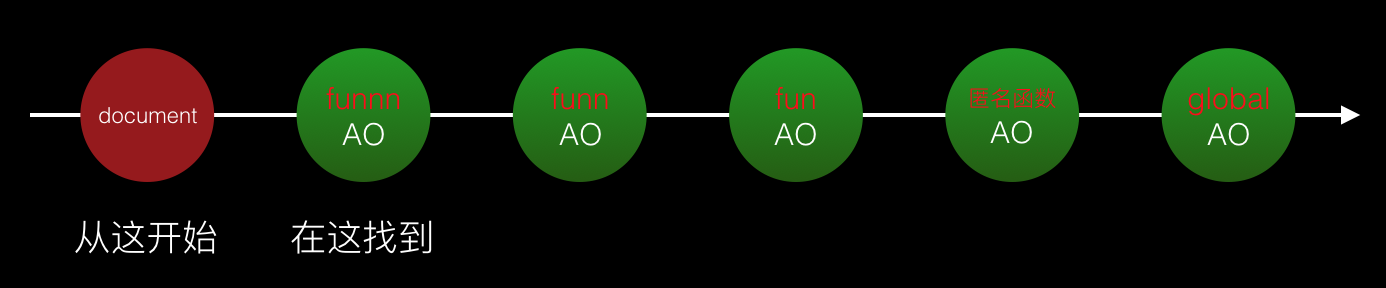
在mac pro的chrome浏览器下做实验,进行100万次查找运算,借助with使用document进行的延长作用域链,因为document下的变量属性比较多,可以测试在多变量作用域链节点下进行查找的性能差异。
实验结果:5次平均耗时558.802ms,而如果删掉with和document,5次平均耗时0.956ms。
当然,这两个实验是在我们假设的极端环境下进行的,结果仅供参考!
关于闭包
1.什么是闭包?
函数对象可以通过作用域链相互关联起来,函数体内的数据(变量和函数声明)都可以保存在函数作用域内,这种特性在计算机科学文献中被称为“闭包”。既函数体内的数据被隐藏于作用于链内,看起来像是函数将数据“包裹”了起来。从技术角度来说,js的函数都是闭包:函数都是对象,都关联到作用域链,函数内数据都被保存在函数作用域内。
2.闭包的几种实现方式
实现方式就是函数A在函数B的内部进行定义了,并且当函数A在执行时,访问了函数B内部的变量对象,那么B就是一个闭包。如下:


如上两图所示,是在chrome浏览器下查看闭包的方法。两种方式的共同点是都有一个外部函数outerFun(),都在外部函数内定义了内部函数innerFun(),内部函数都访问了外部函数的数据。不同的是,第一种方式的innerFun()是在outerFun()内被调用的,既声明和被调用均在同一个执行上下文内。而第二种方式的innerFun()则是在outerFun()外被调用的,既声明和被调用不在同一个执行上下文。第二种方式恰好是js使用闭包常用的特性所在:通过闭包的这种特性,可以在其他执行上下文内访问函数内部数据。
我们更常用的一种方式则是这样的:
1 //闭包实例
2 function outerFun () {
3 var outerV1 = 10
4 function outerF1 () {
5 console.log('I am outerF1...')
6 }
7
8 function innerFun () {
9 var innerV1 = outerV1
10 outerF1()
11 }
12 return innerFun //return回innerFun()内部函数
13 }
14 var fn = outerFun() //接到return回的innerFun()函数
15 fn() //执行接到的内部函数innerFun()
此时它的作用域链是这样的:
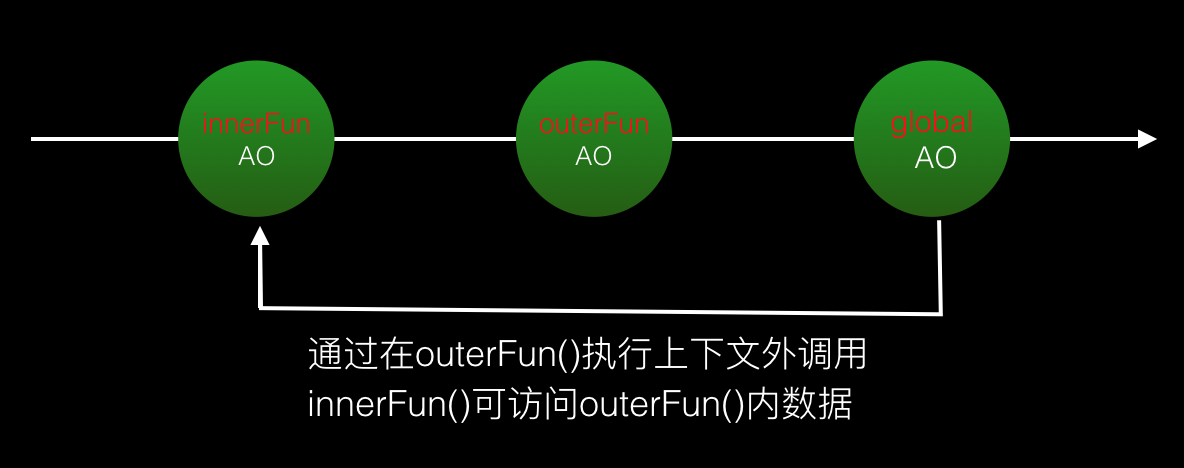
3.闭包的好处及使用场景
js的垃圾回收机制可以粗略的概括为:如果当前执行上下文执行完毕,且上下文内的数据没有其他引用,则执行上下文pop出call stack,其内数据等待被垃圾回收。而当我们在其他执行上下文通过闭包对执行完的上下文内数据仍然进行引用时,那么被引用的数据则不会被垃圾回收。就像上面代码中的outerV1,放我们在全局上下文通过调用innerFun()仍然访问引用outerV1时,那么outerFun执行完毕后,outerV1也不会被垃圾回收,而是保存在内存中。另外,outerV1看起来像不像一个outerFun的私有内部变量呢?除了innerFun()外,我们无法随意访问outerV1。所以,综上所述,这样闭包的使用情景可以总结为:
(1)进行变量持久化。
(2)使函数对象内有更好的封装性,内部数据私有化。
进行变量持久化方面举个栗子:
我们假设一个需求时写一个函数进行类似id自增或者计算函数被调用的功能,普通青年这样写:
1 var count = 0
2 function countFun () {
3 return count++
4 }
这样写固然实现了功能,但是count被暴露在外,可能被其他代码篡改。这个时候闭包青年就会这样写:
1 function countFun () {
2 var count = 0
3 return function(){
4 return count++
5 }
6 }
7
8 var a = countFun()
9 a()
这样count就不会被不小心篡改了,函数调用一次就count加一次1。而如果结合“函数每次被调用都会创建一个新的执行上下文”,这种count的安全性还有如下体现:
1 function countFun () {
2 var count = 0
3 return {
4 count: function () {
5 count++
6 },
7 reset: function () {
8 count = 0
9 },
10 printCount: function () {
11 console.log(count)
12 }
13 }
14 }
15
16 var a = countFun()
17 var b = countFun()
18 a.count()
19 a.count()
20
21 b.count()
22 b.reset()
23
24 a.printCount() //打印:2 因为a.count()被调用了两次
25 b.printCount() //打印出:0 因为调用了b.reset()
以上便是闭包提供的变量持久化和封装性的体现。
4.闭包的注意事项
由于闭包中的变量不会像其他正常变量那种被垃圾回收,而是一直存在内存中,所以大量使用闭包可能会造成性能问题。