视频学习
之前已经看过了相关的视频,这次再看一遍,把一些重要的知识点再回顾一下。
-
机器学习是从数据中自动提取知识,有数据,有意义,没有解析解。机器学习三要素:
-
模型:对要学习问题的映射。
-
数据标记(监督学习、无监督学习、半监督学习、强化学习)
-
数据分布(参数模型,非参数模型)
-
建模对象(判别模型、生成模型)
-
-
策略:从假设空间中学习、选择最优模型的准则(确定目标函数)
-
算法:根据目标函数求解最优模型的具体计算方法(求解模型参数)
-
-
深度学习三个助推剂:数据、算法、计算力
-
深度学习的不能:
-
算法输出不稳定,容易被攻击;
-
模型复杂度高,难以纠错和调试;
-
模型层级复合程度高,参数不透明;(卷积)
-
端到端训练方式对数据依赖性强,模型增量性差;(拟合能力依赖于数据量)
-
专注直观感知类问题,对开放性推理问题无能为力;
-
人类知识无法有效引入进行监督,机器偏见难以避免。(数据不一定正确)
-
-
生物神经元到单层感知器,多层感知器
-
生物神经元 多输入单输出的信息处理单元;具有阈值特性;分为兴奋性和抑制性;具有空间整合和时间整合特性。
-
M-P神经元 具有多个输入,每个输入对应一个权值,这个权值需要预先设定,所以M-P神经元没有学习能力。每个神经元还有一个阈值和一个激活函数。
-
单层感知器 单层感知器的结构与M-P神经元一致,但是单层感知器中的权值是可以通过学习来改变的,所以单层感知器是首个可以学习的人工神经网络。
-
多层感知器 由于单层感知器并不能解决非线性问题,多层感知器由此而生。多层感知器是在一层单层感知器的基础,叠加一层单层感知器,从而解决非线性问题(例如异或问题)。
-
-
误差的反向传播:对参数进行更新,实现对神经网络的学习过程。网络建立之后,数据从输入层进入,经过隐含层的调整,最后得到一个输出,与实际的输出相比较,就会产生一个误差。
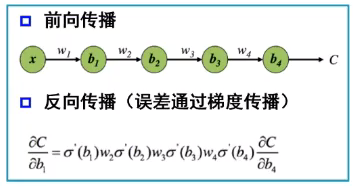
-
激活函数:用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。假设一个示例神经网络中仅包含线性卷积和全连接运算,那么该网络仅能够表达线性映射,即便增加网络的深度也依旧还是线性映射,难以有效建模实际环境中非线性分布的数据。
-
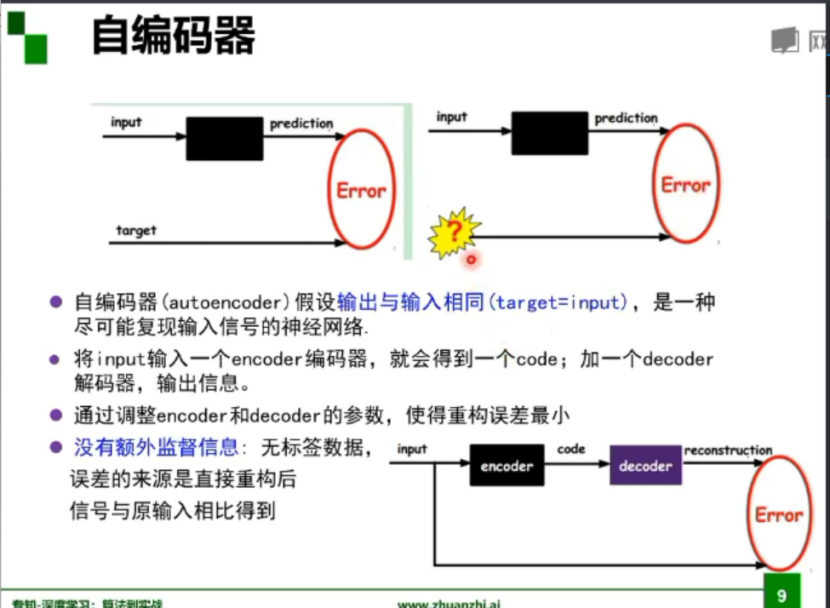
代码练习
图像处理基本练习
有个小问题:

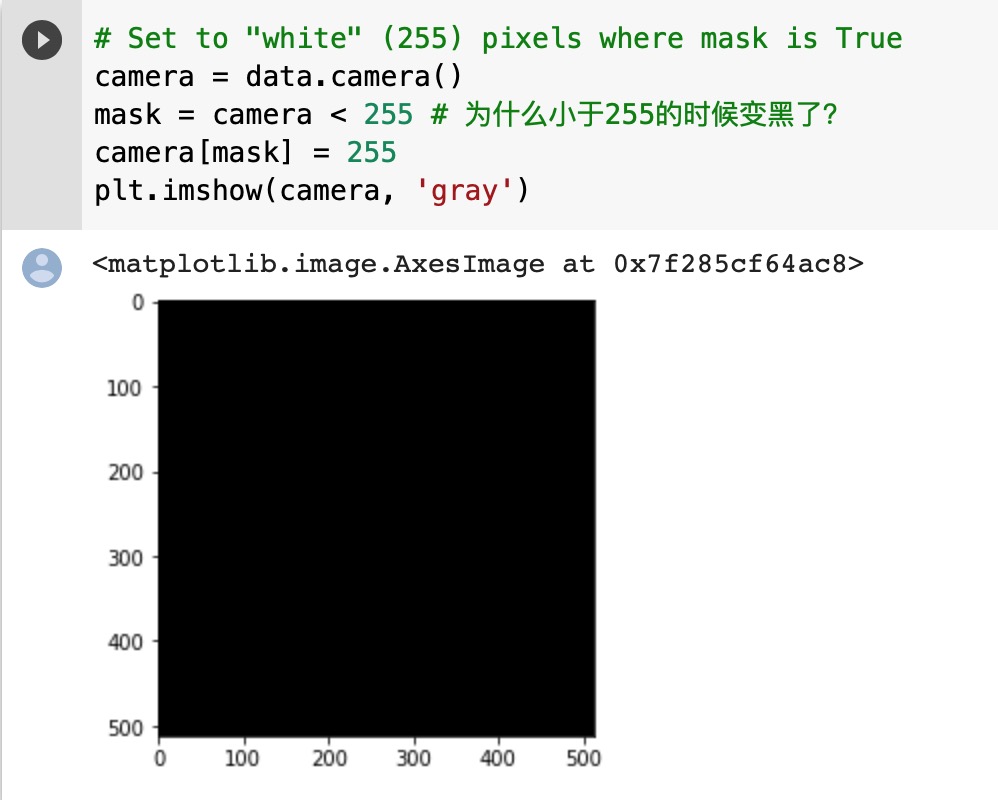
这个问题我还在查。。

Image读出来的是PIL的类型,而skimage.io读出来的数据是numpy格式的

我在网上找到一个图像切割的
分类问题线性模型
1 learning_rate = 1e-3 2 lambda_l2 = 1e-5 3 4 # nn 包用来创建线性模型 5 # 每一个线性模型都包含 weight 和 bias 6 model = nn.Sequential( 7 nn.Linear(D, H), 8 nn.Linear(H, C) 9 ) 10 model.to(device) # 把模型放到GPU上 11 12 # nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数 13 criterion = torch.nn.CrossEntropyLoss() 14 15 # 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化 16 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) 17 18 # 开始训练 19 for t in range(1000): 20 # 把数据输入模型,得到预测结果 21 y_pred = model(X) 22 # 计算损失和准确率 23 loss = criterion(y_pred, Y) 24 score, predicted = torch.max(y_pred, 1) 25 acc = (Y == predicted).sum().float() / len(Y) 26 print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc)) 27 display.clear_output(wait=True) 28 29 # 反向传播前把梯度置 0 30 optimizer.zero_grad() 31 # 反向传播优化 32 loss.backward() 33 # 更新全部参数 34 optimizer.step()

分类问题(添加了Relu函数)
1 learning_rate = 1e-3 2 lambda_l2 = 1e-5 3 4 # 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数 5 model = nn.Sequential( 6 nn.Linear(D, H), 7 nn.ReLU(), 8 nn.Linear(H, C) 9 ) 10 model.to(device) 11 12 # 下面的代码和之前是完全一样的,这里不过多叙述 13 criterion = torch.nn.CrossEntropyLoss() 14 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2 15 16 # 训练模型,和之前的代码是完全一样的 17 for t in range(1000): 18 y_pred = model(X) 19 loss = criterion(y_pred, Y) 20 score, predicted = torch.max(y_pred, 1) 21 acc = ((Y == predicted).sum().float() / len(Y)) 22 print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc)) 23 display.clear_output(wait=True) 24 25 # zero the gradients before running the backward pass. 26 optimizer.zero_grad() 27 # Backward pass to compute the gradient 28 loss.backward() 29 # Update params 30 optimizer.step()
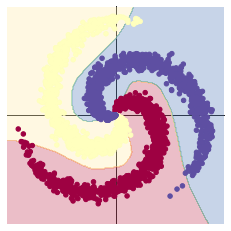
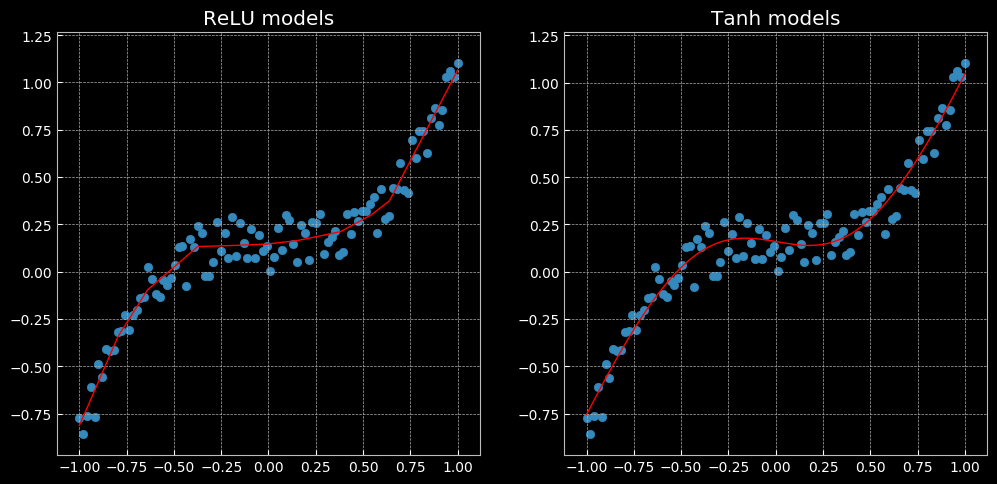
回归问题结果
猫狗大战的代码,我运行了一下,按照老师说的把优化器换成Adam以后,效果的确有提高。尝试按照比赛的要求写输出,因为对python语言不是很熟悉,还存在一些问题。
本周除了完成以上深度学习的内容,还接着学习了吴恩达的机器学习课程,很多东西从基础讲起,很清晰。尤其是参数更新这一块,比以前了解得更深了。