java尝试爬取一些简单的数据,比python复杂点
示例:爬取网站中的所有古风网名:http://www.oicq88.com/gufeng/,并储存入数据库(mysql)
jdk版本:jdk1.8
编辑器:idea
项目构建:maven
所需jar包:http://jsoup.org/packages/jsoup-1.8.1.jar
或maven依赖如下:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>
具体代码如下:
package com.ssm.web.timed; import java.io.IOException; import java.util.ArrayList; import java.util.List; import com.ssm.commons.JsonResp; import com.ssm.utils.ExportExcel; import org.apache.log4j.Logger; import org.jsoup.*; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import javax.servlet.http.HttpServletResponse; @RequestMapping @RestController public class TestCrawlerTime { private Logger log = Logger.getLogger(this.getClass()); //根据url从网络获取网页文本 public static Document getHtmlTextByUrl(String url, String page) { Document doc = null; try { //doc = Jsoup.connect(url).timeout(5000000).get(); int i = (int) (Math.random() * 1000); //做一个随机延时,防止网站屏蔽 while (i != 0) { i--; } doc = Jsoup.connect(url + page).data("query", "Java") .userAgent("Mozilla").cookie("auth", "token") .timeout(300000).get(); } catch (IOException e) { /*try { doc = Jsoup.connect(url).timeout(5000000).get(); } catch (IOException e1) { e1.printStackTrace(); }*/ System.out.println("error: 第一次获取出错"); } return doc; } //递归查找所有的名字 public static List getAllNames(List<String> names, String url, String page){ Document doc = getHtmlTextByUrl(url, page); Elements nameTags = doc.select("div[class=listfix] li p"); //名字标签 for (Element name : nameTags){ names.add(name.text()); } Elements aTags = doc.select("div[class=page] a[class=next]"); //页数跳转标签 for (Element aTag : aTags){ if ("下一页".equals(aTag.text())){ //是下一页则继续爬取 String newUrl = aTag.attr("href"); getAllNames(names, url, newUrl); } } return names; } /** * @Description: 导出爬取到的所有网名 * @Param: * @return: * @Author: mufeng * @Date: 2018/12/11 */ @RequestMapping(value = "/exportNames") public JsonResp export(HttpServletResponse response){ log.info("导出爬取到的所有网名"); String target = "http://www.oicq88.com/"; String page = "/gufeng/1.htm"; List names = new ArrayList(); getAllNames(names, target, page); System.out.println(names.size()); List<Object[]> lists = new ArrayList<>(); Integer i = 1; for (Object name : names){ lists.add(new Object[]{i, name}); i ++; } String[] rowName = new String[]{ "", "网名"}; ExportExcel exportExcel = new ExportExcel("古风网名大全", rowName, lists); try { exportExcel.export(response); } catch (Exception e) { e.printStackTrace(); } return JsonResp.ok(); } public static void main(String[] args) { String target = "http://www.oicq88.com/"; String page = "/gufeng/1.htm"; List names = new ArrayList(); getAllNames(names, target, page); System.out.println(names.size()); System.out.println(names.get(0)); System.out.println(names.get(names.size()-1)); } }
运行结果如下:
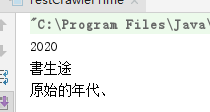

参考教程:https://www.cnblogs.com/Jims2016/p/5877300.html
https://www.cnblogs.com/qdhxhz/p/9338834.html