ES6简介
ECMAScript 6.0(简称 ES6)是 JavaScript 语言的下一代标准,它于2015 年 6 月正式发布。ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现。ECMAScript实现还有Jscript和ActionScript。
源文本(Source Text)
ECMAScript代码使用Unicode,8.0.0或更高版本来表示。包含U+0000至U+10FFFF的所有Unicode代码点值。
词法
SourceCharacter::
any Unicode code point
note
在Java程序中,如果Unicode转义序列u000A发生在单行注释中,则将其解释为行终止符(Unicode代码点U + 000A为LINE FEED(LF)),因此下一个代码点不是注释的一部分
在ECMAScript程序中,注释中发生的Unicode转义序列从不被解释
源代码类型
主要分为以下4中类型:
全局代码(Global code)
全局代码(Global code)是被视为ECMAScript脚本的源文本。特定脚本的全局代码不包括被解析为FunctionDeclaration,FunctionExpression,GeneratorDeclaration,GeneratorExpression,MethodDefinition,ArrowFunction,ClassDeclaration或ClassExpression的一部分的源文本。
Eval代码(Eval code)
Eval代码(Eval code)是提供给内置eval函数的源文本。 更确切地说,如果内置eval函数的参数是一个String,那么它被视为一个ECMAScript脚本。 eval的特定调用的eval代码是该脚本的全局代码部分。
函数代码(Function code)
函数代码(Function code)是解析为ECMAScript函数对象的[[ECMAScriptCode]]和[[FormalParameters]]内部插槽的值的源文本。 特定ECMAScript函数的函数代码不包括被解析为嵌套的FunctionDeclaration,FunctionExpression,GeneratorDeclaration,GeneratorExpression,MethodDefinition,ArrowFunction,ClassDeclaration或ClassExpression的函数代码的任何源文本。
模块代码(Module code)
模块代码(Module code)是作为ModuleBody提供的代码的源文本。 它是在模块初始化时直接执行的代码。 特定模块的模块代码不包括被解析为嵌套的FunctionDeclaration,FunctionExpression,GeneratorDeclaration,GeneratorExpression,MethodDefinition,ArrowFunction,ClassDeclaration或ClassExpression的一部分的任何源文本。
严格模式代码
全局代码,eval代码等包含 使用严格指令(Use Strict Directive)是严格模式代码
模块代码总是严格的模式代码。
ClassDeclaration或ClassExpression的所有部分都是严格的模式代码。
输入元素
ECMAScript脚本或模块的源文本首先被转换为一系列输入元素,
源文本从左到右扫描,重复地将最长可能的代码点序列作为下一个输入元素。
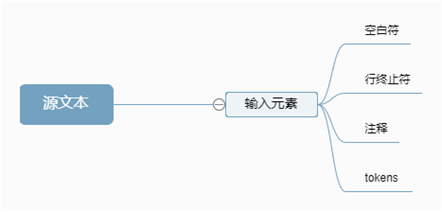
词法
词法语法的多个目标符号
InputElementDiv::
WhiteSpace
LineTerminator
Comment
CommonToken
DivPunctuator
RightBracePunctuator
InputElementRegExp::
WhiteSpace
LineTerminator
Comment
CommonToken
RightBracePunctuator
RegularExpressionLiteral
InputElementRegExpOrTemplateTail::
WhiteSpace
LineTerminator
Comment
CommonToken
RegularExpressionLiteral
TemplateSubstitutionTail
InputElementTemplateTail::
WhiteSpace
LineTerminator
Comment
CommonToken
DivPunctuator
TemplateSubstitutionTail
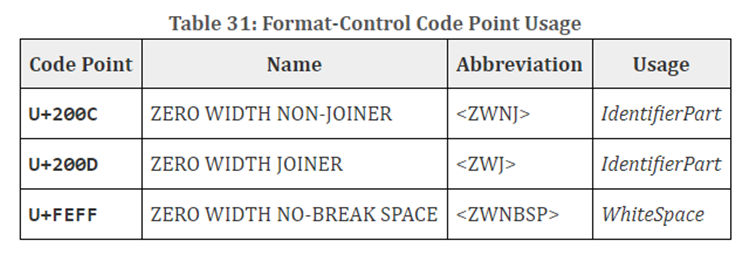
格式控制字符
Unicode格式控制字符(即,Unicode字符数据库中的类别“Cf”中的字符,),在没有更高级别的协议(如标记语言)的情况下,控制一系列文本的格式的控制代码。
允许源文本中的格式控制字符有助于编辑和显示。 所有格式控制字符可以在注释中使用,也可以在字符串文字,模板文字和正则表达式文字中使用。
U+200C(ZERO WIDTH NON-JOINER)和U+200D(ZERO WIDTH JOINER)是用于在以特定语言形成单词或短语时进行必要区分的格式控制字符。 在ECMAScript源文本中,这些代码点也可以在第一个字符之后的IdentifierName中使用。
U+FEFF(ZERO WIDTH NO-BREAK SPACE)是一种主要用于文本开头的格式控制字符,用于将其标记为Unicode,并允许检测文本的编码和字节顺序。 为此目的的字符有时也可能出现在文本开头之后,例如连接文件的结果。 在ECMAScript源文本中,代码点被视为空白字符
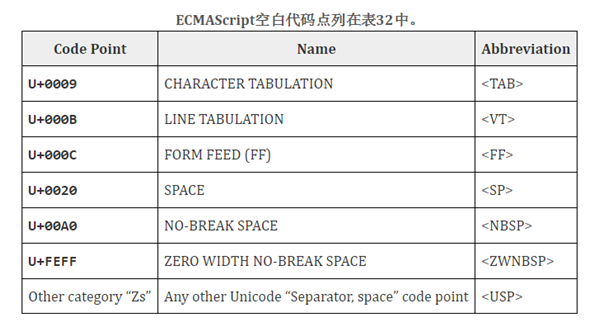
White Space
空白代码点用于提高源文本的可读性,并将词条(token)(不可分割的词汇单位)彼此分开
Line Terminators
像空白代码点一样,行终止符代码点用于提高源文本的可读性,并将token(不可分割的词汇单位)彼此分开。
行终止符可以在MultiLineComment中发生,但不能在SingleLineComment中发生。
行终止符包含在正则表达式中由s类匹配的一组空白代码点中。/s/.test("u000a")返回true。

Comments
注释可以是单行还是多行。 多行注释不能嵌套。
Tokens
CommonToken::
IdentifierName
Punctuator
NumericLiteral
StringLiteral
Template
IdentifierName
IdentifierName和 ReservedWord是根据Unicode标准附件31中标识符和模式语法给出的默认标识符语法进行解释的token,并进行了一些小的修改。ReservedWord是IdentifierName的枚举子集。 语法语法将Identifier定义为不是ReservedWord的IdentifierName 。
该标准规定了特定的代码点添加:标识符名称中的任何地方允许使用U+ 0024(DOLLAR SIGN)和U+005F(LOW LINE),代码点U+200C(ZERO WIDTH NON-JOINER)和U+200D(ZERO WIDTH JOINER)允许在IdentifierName的第一个代码点之后的任何地方。
在IdentifierName中允许使用Unicode转义序列,它们向IdentifierName贡献一个Unicode代码点。 代码点由Unicode转义序列的16进制表示(见11.8.4)。 在Unicode转义序列之前的和u和{}代码单元,如果它们出现,不贡献代码点到IdentifierName。 Unicode转义序列不能用于将代码点放入否则为非法的IdentifierName。 换句话说,如果一个UnicodeEscapeSequence序列被SourceCharacter替换,那么该结果仍然是一个有效的IdentifierName,它具有与原始IdentifierName完全相同的SourceCharacter元素序列。 本规范中IdentifierName的所有解释均基于其实际代码点,而不管转义序列是否用于提供任何特定的代码点。
IdentifierName::
IdentifierStart
IdentifierNameIdentifierPart
IdentifierStart::
UnicodeIDStart
$
_
UnicodeEscapeSequence
IdentifierPart::
UnicodeIDContinue
$
_
UnicodeEscapeSequence
<ZWNJ>
<ZWJ>
UnicodeIDStart::
any Unicode code point with the Unicode property “ID_Start”
UnicodeIDContinue::
any Unicode code point with the Unicode property “ID_Continue”
Reserved Words
保留字(reserved word)是不能用作标识符(Identifier)的IdentifierName。
ReservedWord定义被指定为特定SourceCharacter元素的文字序列。 ReservedWord中的代码点不能由 UnicodeEscapeSequence表示。
ReservedWord::
Keyword
FutureReservedWord
NullLiteral
BooleanLiteral
Keywords&Future Reserved Words

在严格模式代码中,implements package,Protected,interface,private,public,let和static通过静态语义限制
Literals
Numeric Literals
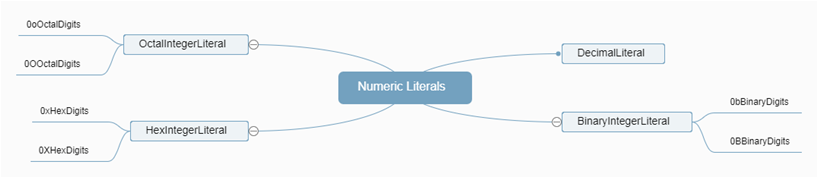
0b101,0o72,0xabc分别是2进制,8进制,16进制数字字面量
String Literals
字符串字面值为零或更多的Unicode代码点,以单引号或双引号括起来
Unicode代码点也可以由转义序列表示
U+005C(REVERSE SOLIDUS),U+000D(CARRIAGE RETURN),U+ 2028(LINE SEPARATOR),U+2029(PARAGRAPH SEPARATOR)和U+000A(LINE FEED)代码点除外,所有代码点可以以字符串文字形式出现
UTF16Encoding ( cp )算法:
Assert: 0 ≤ cp ≤ 0x10FFFF. If cp ≤ 65535, return cp. Let cu1 be floor((cp - 65536) / 1024) + 0xD800. Let cu2 be ((cp - 65536) modulo 1024) + 0xDC00. Return the code unit sequence consisting of cu1 followed by cu2.
属于基本多语言平面的代码点被编码为字符串的单个代码单元元素。 所有其他代码点被编码为字符串的两个代码单元元素。例如:
‘u{20BB7}’
‘u0005’
EscapeCharacter

同样一个字符“|”的不同转义字符表示:
十进制表示:'5'
16进制表示:'x05'
unicode表示:'u0005'
unicode表示:'u{5}'
字符串单字符转义序列:

Regular Expression Literals
正则表达式文字是每次执行文字时转换为RegExp对象(参见21.2)的输入元素。 程序中的两个正则表达式文字作为正则表达式对象执行时,即使两个文字的内容相同,也不会彼此比较为===。
/d/ === /d/
返回false
正则表达式字面量词法:
RegularExpressionLiteral::
/RegularExpressionBody/RegularExpressionFlags
正则表达式不能以* 或 或 / 或 [开始,事实证明以下正则是会报语法错误的
/[/
/*/
对于[符号,是元字符,单个[需要转义吧:
/[/
除了开始位置, 或 / 或 [ 也是不允许直接出现,如需使用需转义。
如果要匹配空字符串,可以使用如下正则:
/(?:)/.test('')
Template Literal Lexical Components
模板字面量词法组件词法:
