条形图简介
数据可视化中,最常用的图非条形图莫属,它主要用来展示不同分类(横轴)下某个数值型变量(纵轴)的取值。其中有两点要重点注意:
1. 条形图横轴上的数据是离散而非连续的。比如想展示两商品的价格随时间变化的走势,则不能用条形图,因为时间变量是连续的;
2. 有时条形图的值表示数值本身,但也有时是表示数据集中的频数,不要引起混淆;
绘制基本条形图
本例选用测试数据集如下:
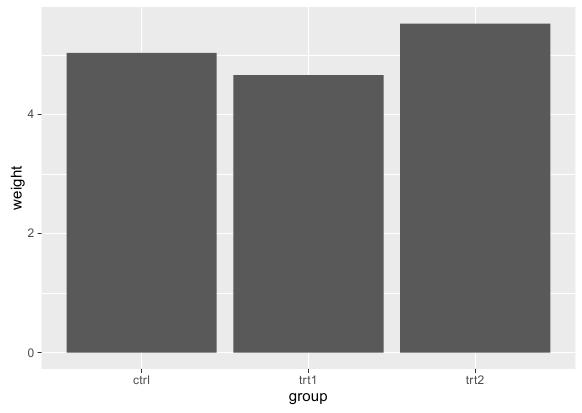
绘制方法是首先调用ggplot函数选定数据集,并在aes参数中指明横轴纵轴。然后调用条形图函数geom_bar(stat="identity")便可绘制出基本条形图。其中stat="identity"表明取用样本点对应纵轴值,R语言实现代码如下:
# 基函数:aes绑定条形图横轴纵轴 ggplot(pg_mean, aes(x = group, y = weight)) + # 条形图函数:stat表明取用样本点对应纵轴值 geom_bar(stat = "identity")
运行效果:
如果觉得灰色调比较难看,可以在条形图函数中指定条形图需要填充的颜色以及条形图的边框颜色。R语言实现代码如下:
# 基函数 ggplot(pg_mean, aes(x = group, y = weight)) + # 条形图函数:fill设置条形图填充色,colour设置条形图边界颜色 geom_bar(stat = "identity", fill = "lightblue", colour = "black")
运行效果:

要强调的是如果横轴对应数据非离散型,则须先将其转为因子类型,否则结果会出现"空条"。
绘制(簇状)条形图
本例选用测试集如下:
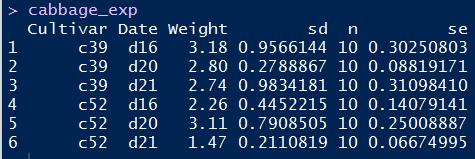
绘制方法是在条形图函数中设置fill参数,将数据集中表示分类的列赋值给它。R语言实现代码如下:
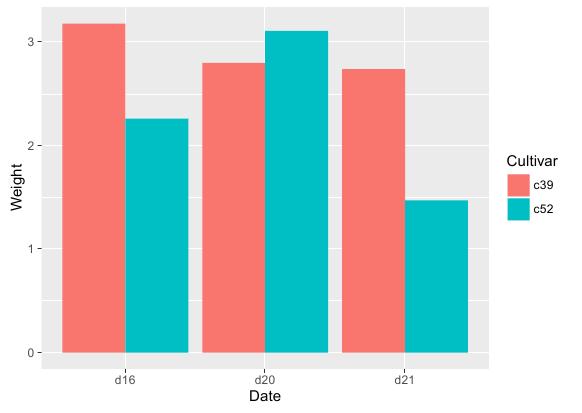
# 基函数:fill绑定"美学特征" ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) + # 条形图函数:position设置条形图类型为簇状 geom_bar(position = "dodge", stat = "identity")
运行效果:
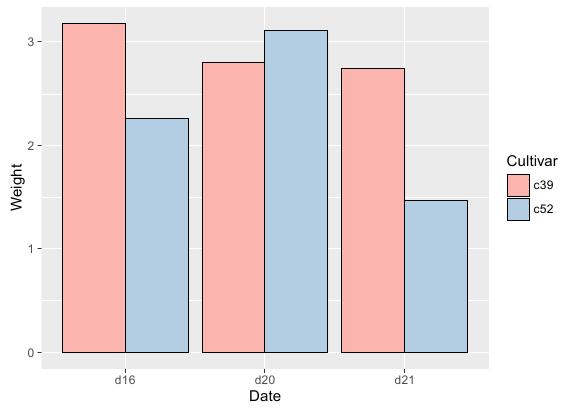
可使用填充标尺函数scale_fill_brewer(palette)重新选择配色,并为条状加上黑色边框。R语言实现代码如下:
# 基函数 ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) + # 条形图函数 geom_bar(position = "dodge", stat = "identity", colour = "black") + # 调色标尺:设置调色板为Pastel1 scale_fill_brewer(palette="Pastel1")
运行效果:
绘制频数条形图
选用测试数据集如下:
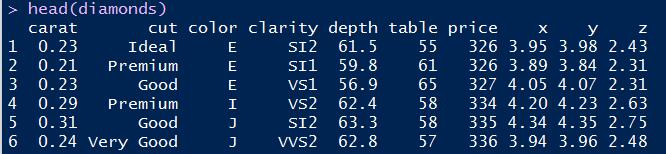
本例需要展示的是不同cut类型变量的样本个数,要实现这点关键在于将stat参数设置为bin。之前将stat设置为identity是直接展示样本点绑定的纵轴值,而设置为bin则会统计样本点落到横轴上各离散值的个数,这种情况下ggplot的aes参数只需绑定横轴。R语言实现代码如下:
# 基函数 ggplot(diamonds, aes(x = cut)) + # 条形图函数:stat参数默认为bin geom_bar(fill = "lightblue", colour = "black")
执行效果:
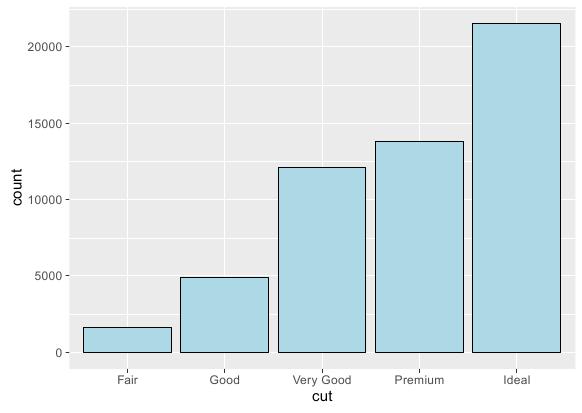
如果横轴是连续变量,那么这张图就会变成直方图。和将来要讲的geom_histogram()函数效果是一样的。
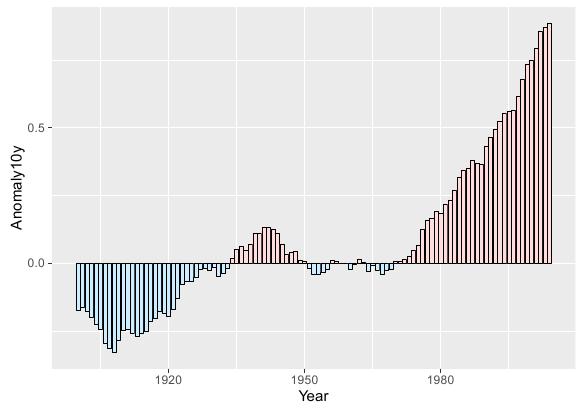
对正负条形图分别着色
本例测试数据集如下:

如若现在需要绘制出数据集中Anomaly10y列随时间的变化,同时可视化方面要求做到小于0的用蓝色表示,大于0的用红色表示。
对于这种情况可为数据集创建一个辅助列pos,该列为布尔类型:TRUE表示Anomaly10y属性大于0,而FALSE表示Anomaly10y列小于0。之后原数据集便多了一个pos列,表征Anomaly10y列值大于等于/小于0。然后将这个字段fiil到ggplot函数,再调用标尺函数对配色进行自定义并令guide=FALSE取消图例。R语言实现代码如下:
# 增加辅助列,表示当前记录Anomaly10y值大于/小于0。
csub$pos = csub$Anomaly10y >= 0
# 基函数
ggplot(csub, aes(x = Year, y = Anomaly10y, fill = pos)) +
# 条形图函数:position设置为"identity"是为了避免系统因绘制负值条形而引发的警告
geom_bar(stat = "identity", position = "identity", colour = "black", size = 0.1) +
# 手动调色标尺:大于0为红,小于0为蓝
scale_fill_manual(values = c("#CCEEFF", "#FFDDDD"), guide = FALSE)
运行效果:
绘制(百分比)堆积型条形图
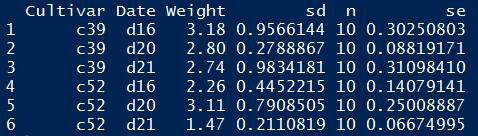
本例测试数据集如下:
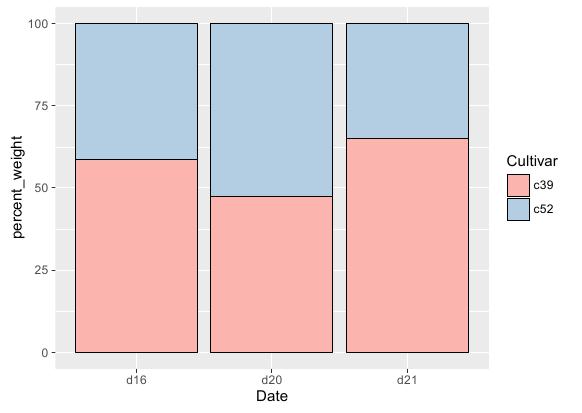
使用ggplot2绘制条形图时,只要不修改geom_bar()函数的position参数,所得条形图便为堆积型。但堆积条形图纵轴大都采用百分比形式,故在具体绘制前,需要对原数据集进行预处理,将纵轴数据转换为分类百分比格式。
本例要统计c39和c52两个品种在不同日期下的重量对比,则需首先将各记录的Weight值除以该记录所在类目的Weight和,然后再将新的百分比列绑定到纵轴。R语言实现代码如下:
# 计算Weight列的分类百分比列 library(plyr) ce = ddply(cabbage_exp, "Date", transform, percent_weight = Weight / sum(Weight) * 100) # 基函数 ggplot(ce, aes(x = Date, y = percent_weight, fill = Cultivar)) + # 条形图函数:未将position参数显示设置为dodge,则绘制出的条形图为堆积型 geom_bar(stat = "identity", colour = "black") + # 调色标尺 scale_fill_brewer(palette = "Pastel1")
运行效果:
添加数据标签
本例测试数据集如下:
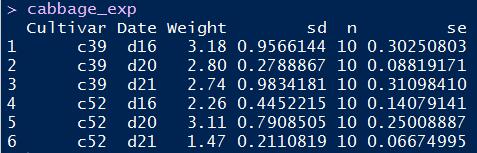
为了给条形图添加标签显示纵轴值,关键在于gemo_text()函数。使用这个函数时,需要在它的aes参数里绑定各样本的横纵坐标,以及要展示的值。
下面首先来展示不同Cultivar分类在不同日期下Weight的对比簇状条形图。R语言实现代码如下:
# 基函数 ggplot(cabbage_exp, aes(x = Date, y = Weight, fill = Cultivar)) + # 条形图函数 geom_bar(stat = "identity", position = "dodge") + # 标签函数:label设置展示标签,vjust设置标签偏移(正上负下),position设置各标签的间距 geom_text(aes(label = Weight), vjust = 1.5, colour = "white", position = position_dodge(.9), size = 5)
运行结果:
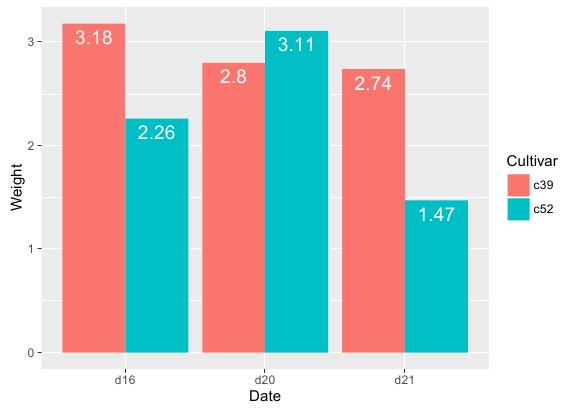
特别要注意的是geom_text()函数的position参数,绘制簇状图必须通过该参数指定各标签的间距。否则一个簇的所有标签都会堆到同一横轴坐标上,像下面这样:

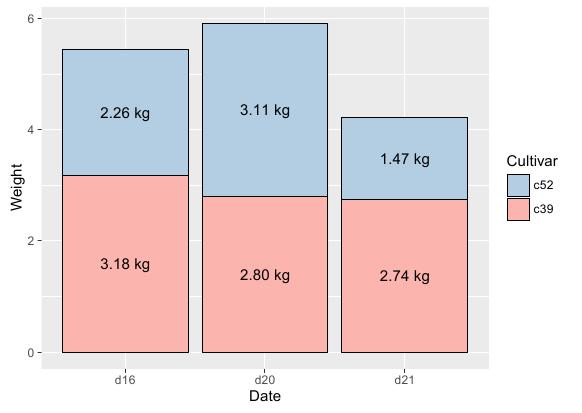
如果要在堆积状的条形图上打标签,则稍微复杂一点。因为要对每组数据进行求和及居中化处理,才能更好的展示出结果。其中关键点在于使用ggplot库提供的ddply方法对分组变量进行汇总求和。具体R语言实现代码如下:
# 根据日期和性别对数据进行排序 ce = arrange(cabbage_exp, Date, Cultivar) # 对不同Date分组内的数据进行累加求和 ce = ddply(ce, "Date", transform, label_y = cumsum(Weight) - 0.5*Weight) # 基函数 ggplot(ce, aes(x = Date, y = Weight, fill = Cultivar)) + # 条形图函数 geom_bar(stat = "identity", colour = "black") + # 标签函数:paste和format方法对标签进行格式化 geom_text(aes(y=label_y, label = paste(format(Weight, nsmall=2), "kg")), size = 4) + # 图例函数:反转图例 guides(fill = guide_legend(reverse = TRUE)) + # 调色标尺 scale_fill_brewer(palette = "Pastel1")
运行结果: