- maxpooling 的 max 函数关于某变量的偏导也是分段的,关于它就是 1,不关于它就是 0;
- BP 是反向传播求关于参数的偏导,SGD 则是梯度更新,是优化算法;
1. 一个实例
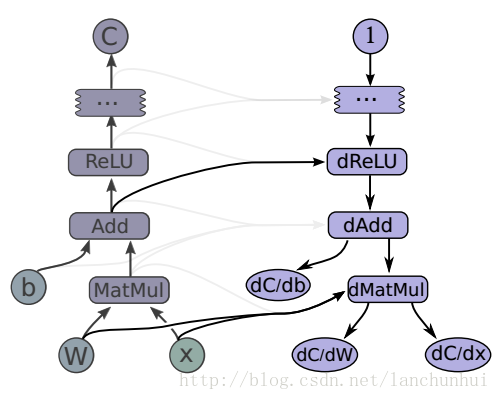
relu = tf.nn.relu(tf.matmul(x, W) + b)
C = [...]
[db, dW, dx] = tf.gradient(C, [b, w, x])relu = tf.nn.relu(tf.matmul(x, W) + b)
C = [...]
[db, dW, dx] = tf.gradient(C, [b, w, x])