0. 文件大小与占用空间
首先需要明确的是,“文件大小”代表着文件的真实大小(文件内容实际包含的全部字节数),“占用空间”往往略大于“ 文件大小”,如下图所示:
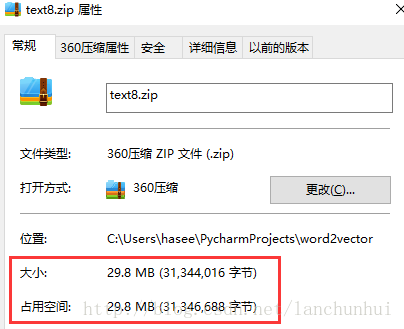
“占用空间”表示为计算机磁盘为存储该文件,所需分配的存储空间,显然“占用空间”必须不小于“文件大小”。事实上,windows 采用 NTFS 和 FAT 的文件系统管理磁盘文件,所有文件系统都是基于簇(分配单元)为大小,即文件在磁盘上的所占空间不再以 Byte 为衡量单位,最小计量单位是“簇(Cluster)”。
1. 磁盘分区与文件系统及簇大小的查看
windows 下使用 Chkdsk(check disk)来查看文件系统类型以及簇大小。
首先以管理员权限运行 cmd,在命令行输入 Chkdsk,即可在只读模式检查本地文件系统。检测结束得到的分析结果中,“分配单元”或者“Allocation unit”即表示簇的大小。
2. 为什么单个大文件比总体积相同的多个小文件复制起来要快很多?
将一个1GB大小的文件分割为 1024 个 1MB 大小的文件快,拷贝的效率要远低于直接拷贝 1 GB 大小的整个块。
从源到目的,复制一个文件需要做的有1-3步:
- 1、在目标位置创建对应的文件名项,因为文件名也是要保存在磁盘上的;
- 2、如果文件有内容,把文件内容写入磁盘,并按照块对齐(512字节-64K不等)
- 3、如果文件有内容,在一个特定的位置把文件内容的块的信息记录下来,标记这些块属于这个文件并且是被使用了。
对于1G的文件,需要的也是这三步,对于1024个1M的文件,需要的是 1024×3 步。对于磁盘设备有IOps的概念,就是每秒能执行的 I/O 次数,对于复制1024个1M文件来说,那么至少需要1024*3次 I/O,对于1G的文件来说,至少需要3次。所以从次数来说,复制小文件越多,磁盘读写次数越多,虽然有 cache 等一系列优化的机制,但整体次数还是要高很多的。并且,磁盘写1字节,和写512字节(一个扇区)的代价是相同的,虽然写入文件名短,但仍然需要写入512字节(一个扇区)。因此写1G文件就至少要比写1024*1M文件多写512K这么多数据。如果说512K这么多数据好像也不太多,但还有一个不可忽略的操作就是比较文件名:复制文件的时候,需要判断是否有重名,复制1个文件,检查1次就可以了,复制1024个文件,就需要检查1024次,并且随着文件的增多,检查的负担也越重(要跟之前的文件都检查一下)。
所以总结下来有三点:
- 1、小文件导致IO次数增多,磁盘IO次数本身就有瓶颈;
- 2、小文件实际写入的内容也更多(这里我没包括索引项,实际索引项也很多,但不好表达);
- 3、小文件导致CPU负担更重,需要匹配更多的信息。
以上三点造成了小文件复制比大文件慢,所有操作系统的所有文件系统基本上都有以上三个原因。