- Windows:默认为 ANSI,记事本程序另存为处,可以设置其他编码格式;
- Ubuntu:默认为 UTF-8
1. ANSI
ANSI 编码表示英文字符时用一个字节,表示中文用两个或四个字节 —— 这带来了存储空间的减少,但却带来的格式的不统一和混乱;
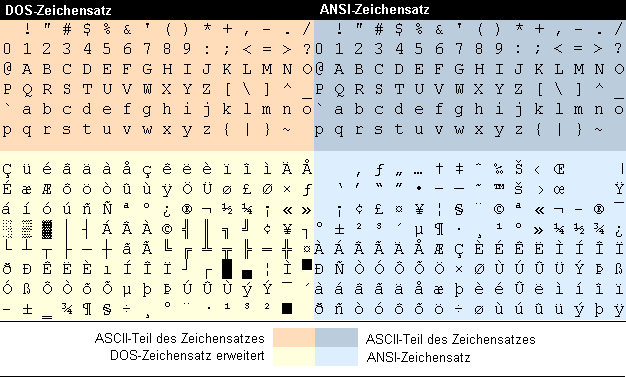
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x79 范围的 1 个字节来表示 1 个英文字符。超出此范围的使用 0x80~0xFFFF来编码,即扩展的 ASCII 编码。
为使计算机支持更多语言,通常使用 0x80~0xFFFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
- 在简体中文 Windows 操作系统中,ANSI 编码代表 GBK 编码;
- 在繁体中文 Windows 操作系统中,ANSI 编码代表 Big5;
- 在日文 Windows 操作系统中,ANSI 编码代表 Shift_JIS 编码;
2. café分别在 utf-8 和 cp1252下的编码形式
How to fix: “UnicodeDecodeError: ‘ascii’ codec can’t decode byte”
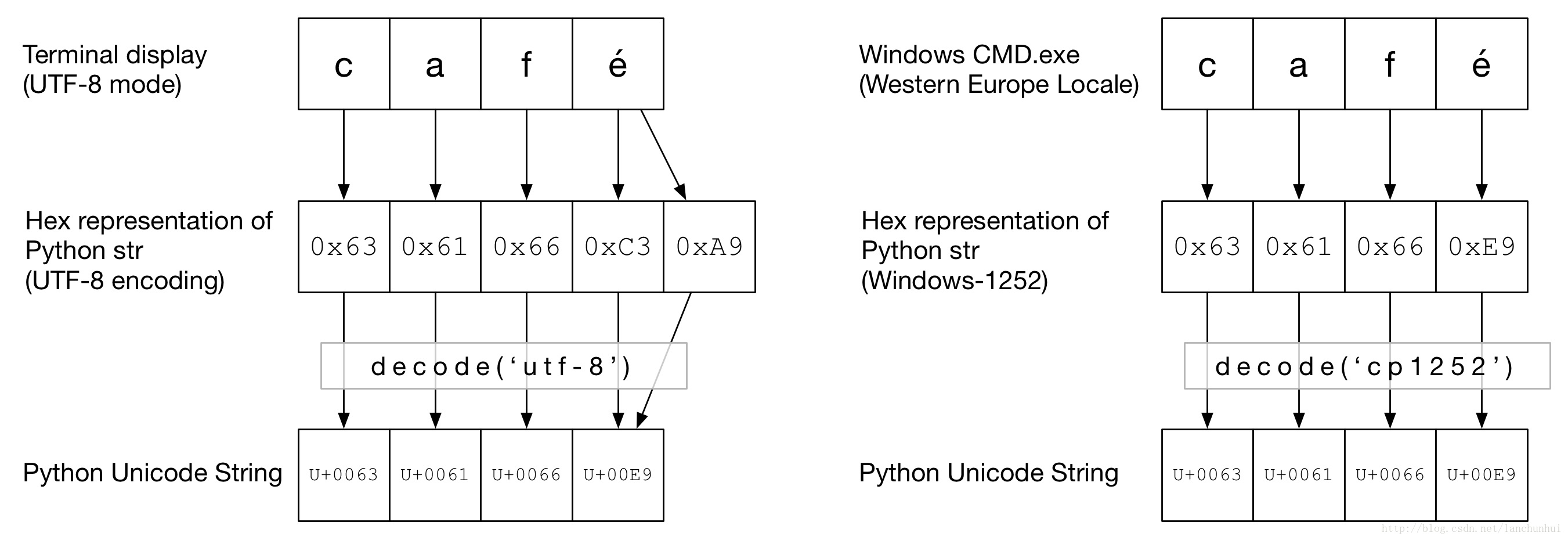
>> 'é'.encode('cp1252')
b'xe9'
>> 'é'.encode('utf-8')
b'xc3xa9'
# 通过何种形式的编码(encode),便继续通过该形式解码(decode)
>> 'café'.encode('cp1252').decode('cp1252')
'café'
>> 'café'.encode('utf-8').decode('utf-8')
'café'字符串café被编码为 utf-8还是cp1252,可通过某位数字判断。前三位字符caf是简单的 ascii。
- utf-8 下,
é使用两个字节进行编码; - cp1252 下,é is 0xE9;