caffe框架下的lenet.prototxt定义了一个广义上的LeNet模型,对MNIST数据库进行训练实际使用的是lenet_train_test.prototxt模型。
lenet_train_test.prototxt模型定义了一个包含2个卷积层,2个池化层,2个全连接层,1个激活函数层的卷积神经网络模型,模型如下:

name: "LeNet" //神经网络的名称是LeNet
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在训练阶段有效
phase: TRAIN
}
transform_param {
scale: 0.00390625 //归一化参数,输入的数据都是需要乘以该参数(1/256)
//由于图像数据上的像素值大小范围是0~255,这里乘以1/256
//相当于把输入归一化到0~1
}
data_param {
source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_train_lmdb" //训练数据的路径
batch_size: 64 //每批次训练样本包含的样本数
backend: LMDB //数据格式(后缀)定义为LMDB,另一种数据格式是leveldb
}
}
layer { //定义一个网络层
name: "mnist" //网络层的名称是mnist
type: "Data" //网络层的类型是数据层
top: "data" //网络层的输出是data和label(有两个输出)
top: "label"
include { //定义该网络层只在测试阶段有效
phase: TEST
}
transform_param {
scale: 0.00390625 //归一化系数是1/256,数据都归一化到0~1
}
data_param {
source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_test_lmdb" //测试数据路径
batch_size: 100 //每批次测试样本包含的样本数
backend: LMDB //数据格式(后缀)是LMDB
}
}
layer { //定义一个网络层
name: "conv1" //网络层的名称是conv1
type: "Convolution" //网络层的类型是卷积层
bottom: "data" //网络层的输入是data
top: "conv1" //网络层的输出是conv1
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 20 //输出是20个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "pool1" //网络层的名称是pool1
type: "Pooling" //网络层的类型是池化层
bottom: "conv1" //网络层的输入是conv1
top: "pool1" //网络层的输出是pool1
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "conv2" //网络层的名称是conv2
type: "Convolution" //网络层的类型是卷积层
bottom: "pool1" //网络层的输入是pool1
top: "conv2" //网络层的输出是conv2
param {
lr_mult: 1 //weights的学习率跟全局基础学习率保持一致
}
param {
lr_mult: 2 //偏置的学习率是全局学习率的两倍
}
convolution_param { //卷积参数设置
num_output: 50 //输出是50个特征图
kernel_size: 5 //卷积核的尺寸是5*5
stride: 1 //卷积步长是1
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
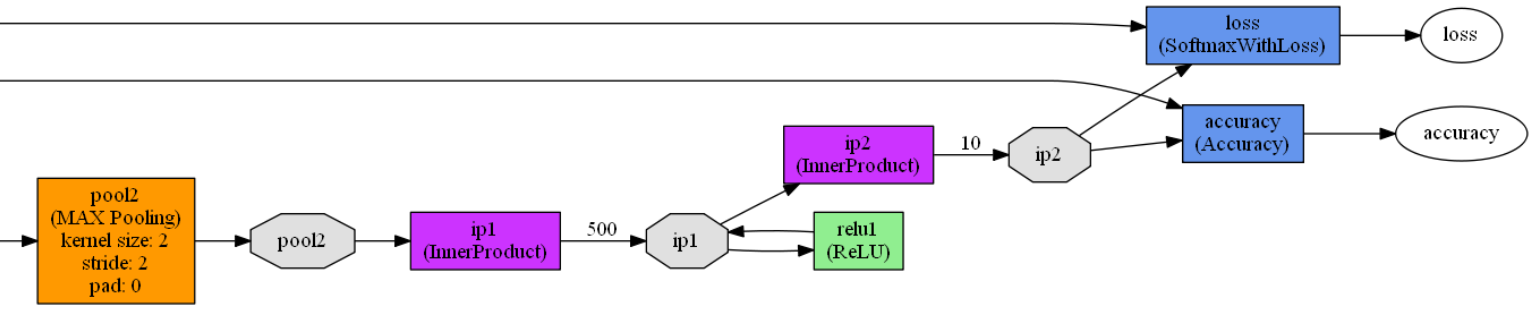
layer { //定义一个网络层
name: "pool2" //网络层的名称是pool2
type: "Pooling" //网络层的类型是池化层
bottom: "conv2" //网络层的输入是conv2
top: "pool2" //网络层的输出是pool2
pooling_param { //池化参数设置
pool: MAX //池化方式最大池化
kernel_size: 2 //池化核大小2*2
stride: 2 //池化步长2
}
}
layer { //定义一个网络层
name: "ip1" //网络层的名称是ip1
type: "InnerProduct" //网络层的类型是全连接层
bottom: "pool2" //网络层的输入是pool2
top: "ip1" //网络层的输出是ip1
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 500 //输出是一个500维的向量
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "relu1" //网络层的名称是relu1
type: "ReLU" //网络层的类型是激活函数层
bottom: "ip1" //网络层的输入是ip1
top: "ip1" //网络层的输出是ip1
}
layer { //定义一个网络层
name: "ip2" //网络层的名称是ip2
type: "InnerProduct" //网络层的类型是全连接层
bottom: "ip1" //网络层的输入是ip1
top: "ip2" //网络层的输出是ip2
param {
lr_mult: 1 //指定weights权重初始化方式
}
param {
lr_mult: 2 //bias(偏置)的初始化全为0
}
inner_product_param { //全连接层参数设置
num_output: 10 //输出是一个10维的向量,即0~9的数字
weight_filler {
type: "xavier" //指定weights权重初始化方式
}
bias_filler {
type: "constant" //bias(偏置)的初始化全为0
}
}
}
layer { //定义一个网络层
name: "accuracy" //网络层的名称是accuracy
type: "Accuracy" //网络层的类型是准确率层
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "accuracy" //网络层的输出是accuracy
include { //定义该网络层只在测试阶段有效
phase: TEST
}
}
layer { //定义一个网络层
name: "loss" //网络层的名称是loss
type: "SoftmaxWithLoss" //网络层的损失函数采用Softmax计算
bottom: "ip2" //网络层的输入是ip2和label
bottom: "label"
top: "loss" //网络层的输出是loss
}