什么是索引
在关系数据库中,索引是一种单独、物理的对数据库表中一列或多列的值进行排序的存储结构;也被称之为key。
索引相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
为什么需要索引
,对数据的读操作会更加频繁,比例在10:1左右,也就是说对数据库的查询操作是非常频繁的。
随着时间的推移,表中的记录会越来越多,此时如果查询速度太慢的话对用户体验是非常不利的。
索引是提升查询效率最有效的手段!
在数据库中插入数据会引发索引的重建。
简单的说索引的就是用帮我们加快查询速度的。
索引的实现原理
数据库中的索引,实现思路与字典是一致的,需要一个独立的存储结构,专门存储索引数据
本质上索引是通过不断的缩小查询范围来提高查询效率
索引数据结构剖析
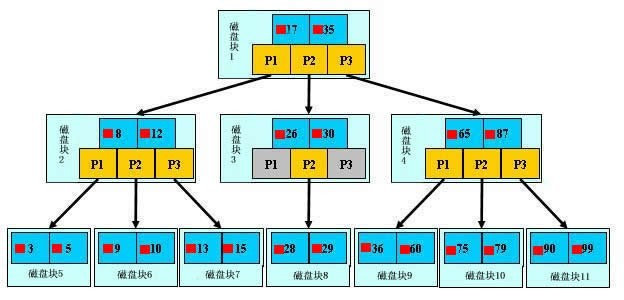
索引最终的目的是要尽可能降低io次数,减少查找的次数,以最少的io找到需要的数据,此时B+树闪亮登场
光有数据结构还不行,还需要有对应的算法做支持,就是二分查找法
有了B+数据结构后查找数据的方式就不再是逐个的对比了,而是通过二分查找法来查找(流程演示)
另外,其实大多数文件系统都是使用B+是来完成的!
应该尽可能的将数据量小的字段作为索引
通过分析可以发现在上面的树中,查找一个任何一个数据都是3次IO操作, 但是这个3次并不是固定的,它取决于数结构的高度,目前是三层,如果要存储新的数据比99还大的数据时,发现叶子节点已经不够了必须在上面加一个子节点,由于树根只能有一个所以,整个数的高度会增加,一旦高度增加则 查找是IO次数也会增加,所以:
应该尽可能的将数据量小的字段作为索引,这样一个叶子节点能存储的数据就更多,从而降低树的高度;
例如:name 和id,应当将id设置为索引而不是name
最左匹配原则*
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候(多字段联合索引),b+树会按照从左到右的顺序来建立搜索树,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
聚集索引*
聚焦索引的特点:
叶子节点保存的就是完整的一行记录,如果设置了主键,主键就作为聚集索引,
如果没有主键,则找第一个NOT NULL 且QUNIQUE的列作为聚集索引,
如果也没有这样的列,innoDB会在表内自动产生一个聚集索引,它是自增的
辅助索引*
除了聚集索引之外的索引都称之为辅助索引或第二索引,包括 foreign key 与 unique
辅助索引的特点:
其叶子节点保存的是索引数据与所在行的主键值,InnoDB用这个 主键值来从聚集索引中搜查找数据
覆盖索引
覆盖索引指的是需要的数据仅在辅助索引中就能找到:
#假设stu表的name字段是一个辅助索引 select name from stu where name = "jack";
这样的话则不需要在查找聚集索引数据已经找到
回表
如果要查找的数据在辅助索引中不存在,则需要回到聚集索引中查找,这种现象称之为回表
# name字段是一个辅助索引 而sex字段不是索引 select sex from stu where name = "jack";
需要从辅助索引中获取主键的值,在拿着主键值到聚集索引中找到sex的值
查询速度对比:
聚集索引 > 覆盖索引 > 非覆盖索引