更多内容,欢迎关注微信公众号:全菜工程师小辉。公众号回复关键词,领取免费学习资料。
当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。 所以更多时候,我们优先考虑哨兵(sentinel) 模式。
Redis sentinel是Redis高可用实现方案:故障发现、故障自动转移、配置中心、客户端通知。从Redis的2.6版本开始提供的,但是当时这个版本的模式是不稳定的,直到Redis的2.8版本以后,这个哨兵模式才稳定下来,在生产环境中,如果想要使用Redis的哨兵模式,也会尽量使用Redis的2.8版本之后的版本。
哨兵虽然有一个单独的可执行文件Redis-sentinel ,但实际上它只是一个运行在特殊模式下的 Redis服务器,你可以在启动一个普通Redis服务器时通过给定--sentinel选项来启动哨兵,哨兵的一些设计思路和zookeeper非常类似。
sentinel的定时任务
sentinel机制中有三种重要的定时任务。
- 每10秒每个sentinel对master和slave执行info
作用:
- 发现slave节点。
- 确认主从关系。
- 每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
作用:
- 互相通信掌握节点的信息和自身信息,可以感知新加入的sentinel
通过master节点的__sentinel__:hello频道进行交互,所有sentinel订阅这个频道并每2秒向该频道发布信息
- 每1秒每个sentinel对其他sentinel和master,slave进行ping
作用:
- 心跳检测
主观下线和客观下线
主观下线
主观下线:单个sentinel节点对Redis节点通信失败的“偏见”。
这是一种主观下线。因为在复杂的网络环境下,这个sentinel与这个master不通,但是如果master与其他的sentinel都是通的呢?所以是一种“偏见”。
这是依靠的第三种定时:每秒去ping一下周围的sentinel和Redis。对于slave Redis,可以使用这个主观下线,因为他不需要进行故障转移;但是对于master Redis,必须使用客观下线。
客观下线
客观下线:所有sentinel节点对master Redis节点失败“达成共识”(超过quorum个则统一,quorum可配置)。
这是依靠的第二种定时:每两秒,sentinel之间进行“商量”(一个 sentinel 可以通过向另一个 sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
对于master redis的下线,必须要达成共识才可以,因为涉及故障转移,仅仅依靠一个sentinel判断是不够的
领导者选举
当sentinel集群需要故障转移的时候会在集群中选出Leader执行故障转移操作。sentinel采用了Raft协议实现了sentinel间选举Leader的算法,不过也不完全跟论文描述的步骤一致。sentinel集群运行过程中故障转移完成,所有sentinel又会恢复平等。Leader仅仅是故障转移操作出现的角色。
选举流程
- 某个sentinel认定master客观下线的节点后,该sentinel会先看看自己有没有投过票,如果自己已经投过票给其他sentinel了,在2倍故障转移的超时时间自己就不会成为Leader。相当于它是一个Follower。
- 如果该sentinel还没投过票,那么它就成为Candidate。
- 和Raft协议描述的一样,成为Candidate,sentinel需要完成几件事情
3.1 更新故障转移状态为start
3.2 当前epoch加1,相当于进入一个新term,在sentinel中epoch就是Raft协议中的term。
3.3 更新自己的超时时间为当前时间随机加上一段时间,随机时间为1s内的随机毫秒数。
3.4 向其他节点发送is-master-down-by-addr命令请求投票。命令会带上自己的epoch。
3.5 给自己投一票,在sentinel中,投票的方式是把自己master结构体里的leader和leader_epoch改成投给的sentinel和它的epoch。 - 其他sentinel会收到Candidate的is-master-down-by-addr命令。如果sentinel当前epoch和Candidate传给他的epoch一样,说明他已经把自己master结构体里的leader和leader_epoch改成其他Candidate,相当于把票投给了其他Candidate。投过票给别的sentinel后,在当前epoch内自己就只能成为Follower。
- Candidate会不断的统计自己的票数,直到他发现认同他成为Leader的票数超过一半而且超过它配置的quorum(quorum可以参考《redis sentinel设计与实现》)。sentinel比Raft协议增加了quorum,这样一个sentinel能否当选Leader还取决于它配置的quorum。
- 如果在一个选举时间内,Candidate没有获得超过一半且超过它配置的quorum的票数,自己的这次选举就失败了。
- 如果在一个epoch内,没有一个Candidate获得更多的票数。那么等待超过2倍故障转移的超时时间后,Candidate增加epoch重新投票。
- 如果某个Candidate获得超过一半且超过它配置的quorum的票数,那么它就成为了Leader。
- 与Raft协议不同,Leader并不会把自己成为Leader的消息发给其他sentinel。其他sentinel等待Leader从slave选出master后,检测到新的master正常工作后,就会去掉客观下线的标识,从而不需要进入故障转移流程。
故障转移过程
- 当多个sentinel发现并确认了master有问题
- 接着会选举出一个sentinel作为领导
- 再选举出一个slave作为master
- 通知其余的slave,新的master是谁
- 通知客户端一个主从的变化
- 最后,sentinel会等待旧的master复活,然后将新master成为slave
那么,如何选择“合适”的slave节点呢?
- 选择slave-priority(slave节点优先级,人为配置)最高的slave节点,如果存在则返回,不存在则继续。
- 其次会选择复制偏移量最大的slave节点(复制得最完整),如果存在则返回,不存在则继续
- 最后会选择run_id最小的slave节点(启动最早的节点)
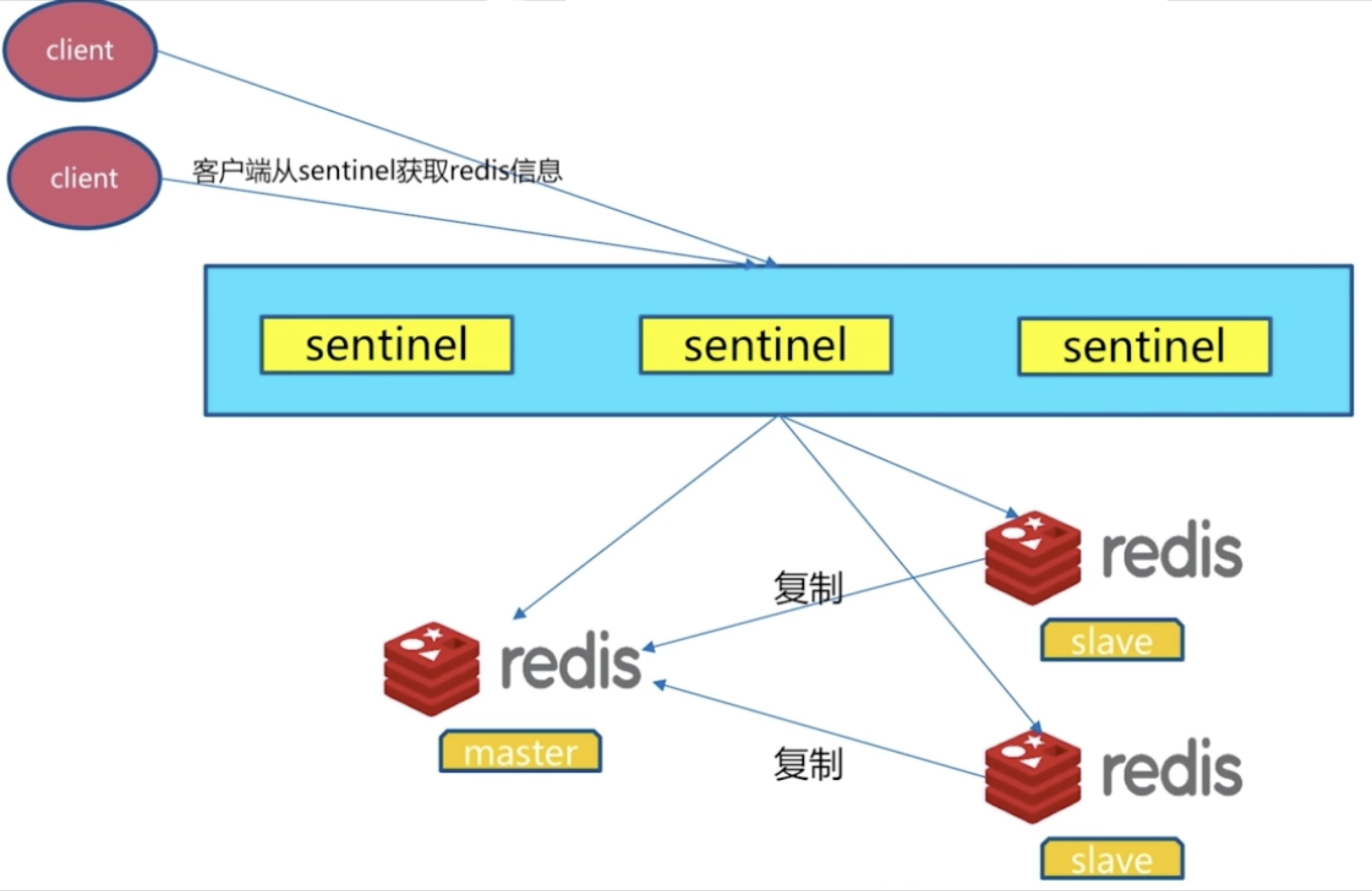
客户端实现高可用的基本原理
故障转移后客户端无法感知将无法保证正常的使用。所以,实现客户端高可用的步骤如下:
- 客户端获取sentinel节点集合
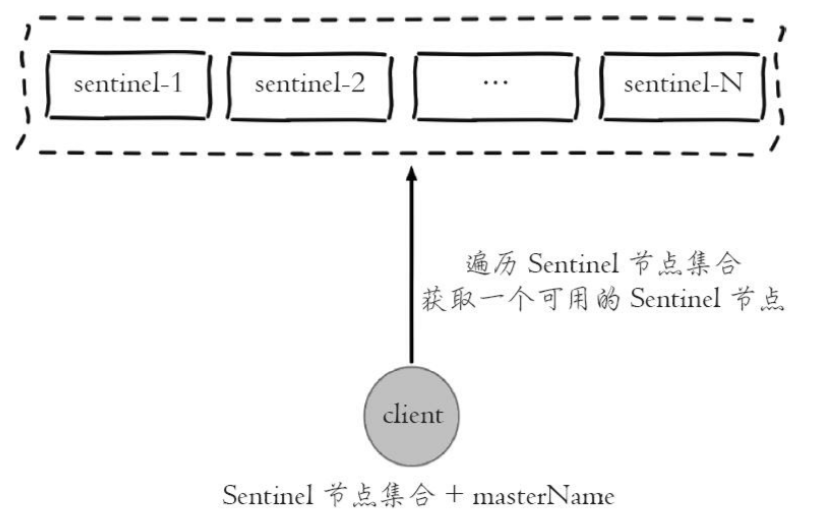
- 客户端通过sentinel get-master-addr-by-name master-name这个api来获取对应主节点信息
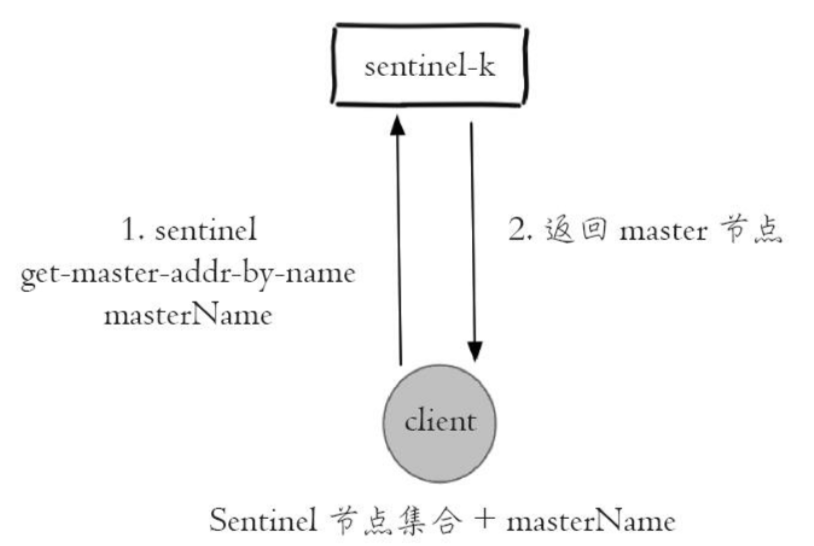
- 客户端验证当前获取的“主节点”是真正的主节点,这样的目的是为了防止故障转移期间主节点的变化
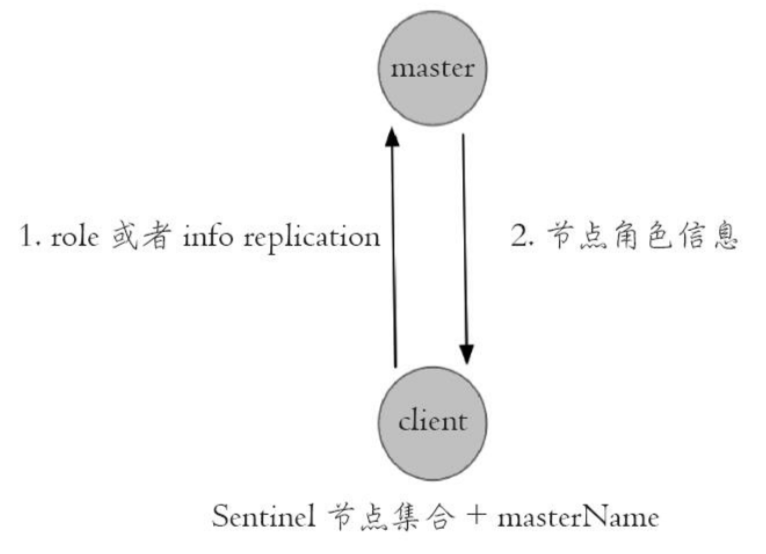
- 客户端保持和sentinel节点集合的联系,即订阅sentinel节点相关频道,时刻获取关于主节点的相关信息

从上面的模型可以看出,Redis sentinel客户端只有在初始化和切换主节点时需要和sentinel进行通信来获取主节点信息,所以在设计客户端时需要将sentinel节点集合考虑成配置(相关节点信息和变化)发现服务。
需要说明的问题
- 尽可能在不同物理机上和同一个网络部署Redis sentinel的所有节点
- Redis sentinel中的sentinel节点个数应该大于等于3且最好是奇数。(节点数多可以保证高可用)
- Redis sentinel中的数据节点和普通数据节点没有区别。每个sentinel节点在本质上还是一个Redis实例,只不过和Redis数据节点不同的是,其主要作用是监控Redis数据节点
- 客户端初始化时连接的是sentinel节点集合,不再是具体的Redis节点,但sentinel只是配置中心不是代理。
更多内容,欢迎关注微信公众号:全菜工程师小辉。公众号回复关键词,领取免费学习资料。
