AX系统已有的BI分析架构
对于AX 的BI分析架构,相信大家都了解,可以看Reinhard之前的译文[译]Dynamics AX 2012 R2 BI系列-分析的架构 。
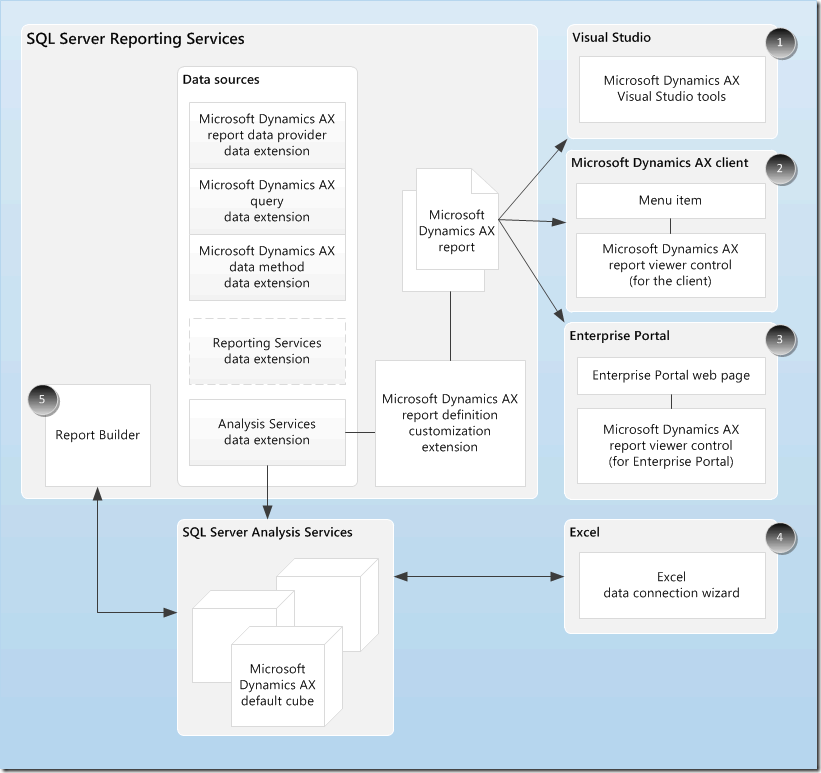
AX 的BI分析架构的优势
从图上我们可以看出,AX是弱化了数据仓库的概念,直接用多维数据集作为分析报表的数据源。得益于AX与SSAS的深度集成,并且提供了许多预先定义好的多维数据集,可以很快地制作一个简单的分析报表。
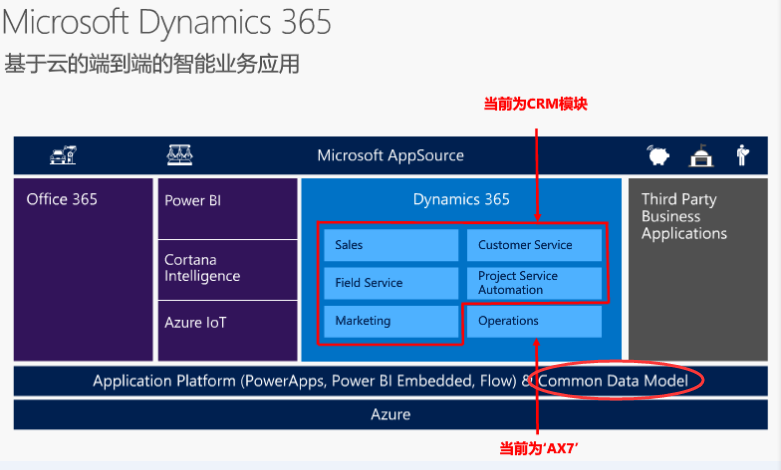
Dynamics 365技术架构的优势
在新出的Dynamics 365里,提出了Common Data Model的概念,在一定程度上,从应用的底层解决了多系统数据整合的问题。Reinhard在12月初的微软技术大会上了解到,Dynamics 365 Operations除了Online版本外,On Premise版也在12月初有了销售版,感兴趣的同学可以关注下。
数据仓库
既然说到了数据仓库,那么我们就来看看什么是数据仓库。
数据仓库的定义
数据仓库是一个数据库,这种数据库的设计,可以支持商业智能活动:帮助用户理解和提高组织的绩效。它的设计,是用于查询和分析,而不是事务处理,并且通常包含从交易数据中派生的历史数据,也包含其他数据源中的数据。数据仓库将分析的工作负载,从事务的工作负载中分离出来,让企业能够整合来自多个数据源的数据。
除了一个关系型数据库外,一个数据仓库环境还需要包含ETL解决方案、统计分析、报表、数据挖掘、客户端分析工具。
数据仓库需要使用从多个源收集的数据。这些源数据可能来自企业内部自己开发的系统,采购的应用程序,第三方数据提供商,和其他源。它可能涉及交易,生产,市场,人力资源等。在今天这个大数据的时代,网站上点击事件的数据可能超过数十亿条,还有自动化机器的传感器产生的大量数据流。
为什么不能将AX作为数据仓库来用?
这里,需要说说AX系统与数据仓库主要的区别:
环境上的不同
两者最大的不同,是AX系统其实是一个OLTP系统,它的设计需要遵循3NF标准。而数据仓库并不完全遵循3NF标准。
需求上的不同
工作负载
数据仓库的设计,是为了适应即席查询和数据分析。因为对工作负载无法预知,所以要对大量可能的查询和分析操作,进行性能优化。
AX系统中,执行的其实大多数都是预先定义好的操作,如更新、写入、删除等。
数据修改
数据仓库一般是通过ETL更新,最终用户不能直接更新数据仓库。
AX系统中,最终用户的修改会持久化到数据库中,AX系统总是反映每个商业交易的最新状态。
架构设计
数据仓库总是使用部分非规范化的架构,来优化查询和分析的性能。
AX系统中,总是使用完全规范的架构,来优化更新、写入、删除操作,来保证数据的一致性。
典型操作
数据仓库的典型查询,会扫描上百万的记录。
AX系统的典型操作,是对某一行记录进行操作,这只需访问少量的记录。
历史数据
数据仓库通常需要存储几个月甚至几年的数据,这些数据为历史分析和报表提供支持。
AX系统中,反应的是每个商业交易的最新状态。不过有时也会为了满足当前交易的需要,存储一些相关的历史数据。
建立数据仓库的必要性
传统BI分析
我们知道,OLAP Cube一般而言,在性能上要比RDBMS更好。
对于传统BI分析来说,是需要建立OLAP Cube的。在建立Cube前,一般也会在数据库使用星型架构建立维度化的模型,将数据清洗好,填充进来,作为Cube的数据源。这里的星型架构和OLAP cube其实都属于数据仓库的一部分。
AX的BI分析
对于AX而言,是用表或视图来创建透视,然后定义维度和测量,接着运行分析服务项目向导来生成、部署项目,最后对多维数据集进行处理。每次处理,Cube中的数据都会更新,其实是无法做历史数据分析的。
敏捷BI分析
随着软件发展的日新月异,计算机的硬件也越来越先进,仿佛OLAP Cube的优势也没那么明显了。近几年流行的敏捷BI工具,如Power BI、Tableau、Qlik等,就有意弱化了分析建模的过程。它们使用了内存数据库、列存储数据库等技术,来对数据进行缓存,加快了数据处理、渲染的速度,有时甚至可以直连生产环境且对生产环境性能的影响微乎其微。那么使用敏捷BI分析工具还需要建立数据仓库么?
Reinhard认为,如果你的分析需要整合多个系统的数据,如果你要分析历史数据,如果你的业务系统的数据库无法满足查询和分析的性能需求,那么你仍然需要建立数据仓库。先对多个系统的数据进行整合、清洗,然后将清洗过的数据导入到企业级的数据仓库中,才能用于数据分析和展示。