1 前言
Scrapy使用ImagesPipeline类中函数get_media_requests下载到图片后,默认的图片命名为图片下载链接的哈希值,例如:它的下载链接是http://img.ivsky.com/img/bizhi/pre/201101/10/harry_potter5-017.jpg,哈希值为7710759a8e3444c8d28ba81a4421ed,那么最终的图片下载到指定路径后名称为7710759a8e3444c8d28ba81a4421ed.JPG。想要自定义图片名称则需要借助ImagesPipeline类中item_completed()函数来重命名。
{kind=link}
2 爬虫过程
爬虫过程就不赘述了,链接请参看:https://www.cnblogs.com/mrtop/p/10180072.html,本文章重点介绍如何自定义图片名称。爬虫运行后获得的图片如下图:
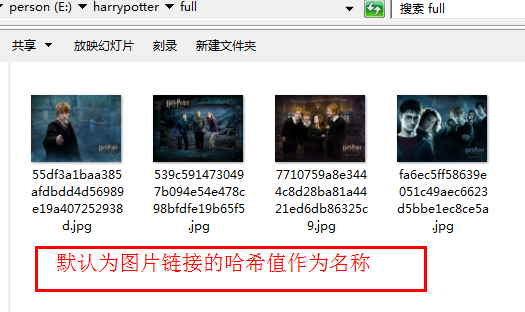
3 自定义图片名称具体方法
3.1 自定义图片名称代码
import os from harry.settings import IMAGES_STORE as IMGS from scrapy.pipelines.images import ImagesPipeline from scrapy import Request class HarryPipeline(object): def process_item(self, item, spider): return item class HarryDownLoadPipeline(ImagesPipeline): def get_media_requests(self, item, info): for imgurl in item['img_url']: yield Request(imgurl) def item_completed(self, results, item, info): print ('******the results is********:',results) os.rename(IMGS + '/' + results[0][1]['path'], IMGS + '/' + item['img_name']) def __del__(self): #完成后删除full目录 os.removedirs(IMGS + '/' + 'full')
注:对于def __del__(self)函数可要可不要,因为重命名过程是携带路径重命名,所以默认生成的full文件夹就为空,只是顺手删除空文件夹(如果里面有文件存在是删除不了的)
3.2 自定义图片名称代码详细解析
3.2.1 get_media_requests函数
get_media_requests方法的原型为:
def item_completed(self, results, item, info): if isinstance(item, dict) or self.images_result_field in item.fields: item[self.images_result_field] = [x for ok, x in results if ok] return item
可以看到get_media_requests有三个参数,
第一个是self,这个不必多说;
第二个是 item,这个就是 spiders传递过来的 item
第三个是 info,看名字就知道这是用来保存信息的,至于是什么信息,info其实是一个用来保存保存图片的名字和下载链接的列表
3.2.2 Item_completed函数
item_completed方法的原型如下:
def item_completed(self, results, item, info): if isinstance(item, dict) or self.images_result_field in item.fields: item[self.images_result_field] = [x for ok, x in results if ok] return item
注意到 item_completed里有个 results参数,results参数保存了图片下载的相关信息,将他print看看具体信息:
[(True, {'url': 'http://img.ivsky.com/img/bizhi/pre/201101/10/harry_potter5-015.jpg', 'path': 'full/539c5914730497b094e5c98bfdfe19b65f5.jpg', 'checksum': '37d23ffb0ab983ac2da9a9d'})]
真实结构为一个list [(DownLoad_success_or_failure),dict],字典中含有三个键:1、'url':图片路径 2、'path':图片下载后的保存路径 3、'checksum':校验码
从中我们可以看到只要我们修改字典中图片保存路径(路径详细到图片名称)的值,那么我们就能自定义图片名称。
关键代码为:
os.rename(IMGS + '/' + results[0][1]['path'], IMGS + '/' + item['img_name'])
解释:rename函数,results[0][1]['path']意思就是:在result这个list中找到图片的名称,其中我们也可以看到这个图片的位置是绝对路径,所以需要携带路径IMGS修改。
4 更新pipelines.py后运行结果

如有疑问,欢迎留言讨论交流,转载请注明出处。