数据压缩的方式非常多,不同特点的数据有不同的数据压缩方式:如对声音和图像等特殊数据的压缩,就可以采用有损的压缩方法,允许压缩过程中损失一定的信 息,换取比较大的压缩比;而对音乐数据的压缩,由于数据有自己比较特殊的编码方式,因此也可以采用一些针对这些特殊编码的专用数据压缩算法。
hadoop使用的压缩工具主要有:
| 压缩格式 | 工具 | 算法 | 扩展名 | 多文件 | 可分割性 |
|---|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 不 | 不 |
| GZIP | gzip | DEFLATE | .gzp | 不 | 不 |
| ZIP | zip | DEFLATE | .zip | 是 | 是,在文件范围内 |
| BZIP2 | bzip2 | BZIP2 | .bz2 | 不 | 是 |
| LZO | lzop | LZO | .lzo | 不 | 是 |
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
gzip |
8.3GB |
1.8GB |
17.5MB/s |
58MB/s |
bzip2 |
8.3GB |
1.1GB |
2.4MB/s |
9.5MB/s |
LZO-bset |
8.3GB |
2GB |
4MB/s |
60.6MB/s |
LZO |
8.3GB |
2.9GB |
49.3MB/s |
74.6MB/s |
这还不是全部,hadoop通过压缩流,也就是将文件写进压缩流里面进行数据读写,性能如何呢?
下例中说明了如何使用API来压缩从标谁输入读取的数据及如何将它写到标准输出:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public class StreamCompressor { public static void main(String[] args) throws Exception { String codecClassname = args[0]; Class<?> codecClass = Class.forName(codecClassname); // 通过名称找对应的编码/解码器 Configuration conf = new Configuration();CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf); // 通过编码/解码器创建对应的输出流 CompressionOutputStream out = codec.createOutputStream(System.out); // 压缩 IOUtils.copyBytes(System.in, out, 4096, false); out.finish(); }} |
在阅读一个压缩文件时,我们通常可以从其扩展名来推断出它的编码/解码器。以.gz结尾的文件可以用GzipCodec来阅读,如此类推。每个压缩格式的扩展名如第一个表格;
CompressionCodecFactory提供了getCodec()方法,从而将文件扩展名映射到相应的CompressionCodec。此方法接受一个Path对象。下面的例子显示了一个应用程序,此程序便使用这个功能来解压缩文件。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class FileDecompressor { public static void main(String[] args) throws Exception { String uri = args[0]; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), conf); Path inputPath = new Path(uri); CompressionCodecFactory factory = new CompressionCodecFactory(conf); CompressionCodec codec = factory.getCodec(inputPath); if (codec == null) { System.err.println("No codec found for " + uri); System.exit(1); } String outputUri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension()); InputStream in = null; OutputStream out = null; try { in = codec.createInputStream(fs.open(inputPath)); out = fs.create(new Path(outputUri)); IOUtils.copyBytes(in, out, conf); } finally { IOUtils.closeStream(in); IOUtils.closeStream(out); } }} |
% hadoop FileDecompressor file.gz| 属性名 | 类型 | 默认值 | 描述 |
| io.compression.codecs | 逗号分隔的类名 | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.Bzip2Codec |
用于压缩/解压的CompressionCodec列表 |
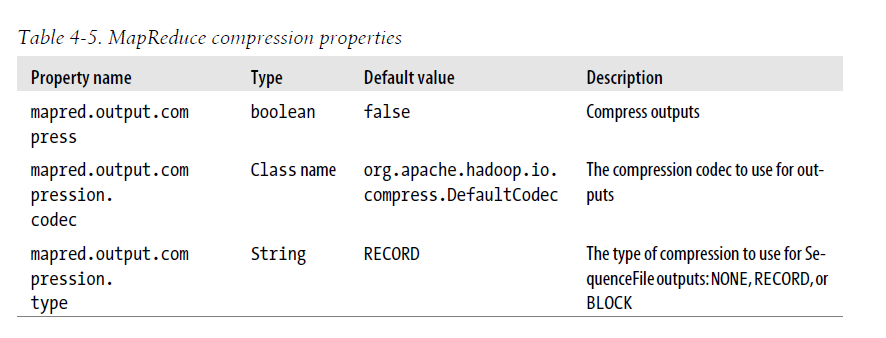
考虑到性能,最好使用一个本地库(native library)来压缩和解压。例如,在一个测试中,使用本地gzip压缩库减少了解压时间50%,压缩时间大约减少了10%(与内置的Java实现相比 较)。表4-4展示了Java和本地提供的每个压缩格式的实现。井不是所有的格式都有本地实现(例如bzip2压缩),而另一些则仅有本地实现(例如 LZO)。
| 压缩格式 | Java实现 | 本地实现 |
| DEFLATE | 是 | 是 |
| gzip | 是 | 是 |
| bzip2 | 是 | 否 |
| LZO | 否 | 是 |
Hadoop带有预置的32位和64位Linux的本地压缩库,位于库/本地目录。对于其他平台,需要自己编译库,具体请参见Hadoop的维基百科http://wiki.apache.org/hadoop/NativeHadoop。
本地库通过Java系统属性java.library.path来使用。Hadoop的脚本在bin目录中已经设置好这个属性,但如果不使用该脚本,则需要在应用中设置属性。
默认情况下,Hadoop会在它运行的平台上查找本地库,如果发现就自动加载。这意味着不必更改任何配置设置就可以使用本地库。在某些情况下,可能 希望禁用本地库,比如在调试压缩相关问题的时候。为此,将属性hadoop.native.lib设置为false,即可确保内置的Java等同内置实现 被使用(如果它们可用的话)。
CodecPool(压缩解码池)
如果要用本地库在应用中大量执行压缩解压任务,可以考虑使用CodecPool,从而重用压缩程序和解压缩程序,节约创建这些对象的开销。
下例所用的API只创建了一个很简单的压缩程序,因此不必使用这个池。此应用程序使用一个压缩池程序来压缩从标准输入读入然后将其写入标准愉出的数据:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public class PooledStreamCompressor { public static void main(String[] args) throws Exception { String codecClassname = args[0]; Class<?> codecClass = Class.forName(codecClassname); Configuration conf = new Configuration();CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf); Compressor compressor = null; try {compressor = CodecPool.getCompressor(codec);//从缓冲池中为指定的CompressionCodec检索到一个Compressor实例CompressionOutputStream out = codec.createOutputStream(System.out, compressor); IOUtils.copyBytes(System.in, out, 4096, false); out.finish(); } finally { CodecPool.returnCompressor(compressor); } }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public class MaxTemperatureWithCompression { public static void main(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: MaxTemperatureWithCompression <input path> " + "<output path>"); System.exit(-1); } Job job = new Job(); job.setJarByClass(MaxTemperature.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); job.setMapperClass(MaxTemperatureMapper.class); job.setCombinerClass(MaxTemperatureReducer.class); job.setReducerClass(MaxTemperatureReducer.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
|
1
2
3
4
5
|
Configuration conf = new Configuration();conf.setBoolean("mapred.compress.map.output", true);conf.setClass("mapred.map.output.compression.codec", GzipCodec.class,CompressionCodec.class);Job job = new Job(conf); |
|
1
2
|
conf.setCompressMapOutput(true);conf.setMapOutputCompressorClass(GzipCodec.class); |
压缩就到此为止了。总之编码和解码在hadoop有着关键的作用。