训练和测试人脸识别分类器时,总会提到Open-set和Close-set。这俩词到底是什么概念呢?有什么区别呢?
所谓close-set,就是所有的测试集都在训练集中出现过。所以每次的预测直接得出测试图片的ID,如果想测试两张图片是不是同一个人,那么就看这两张图片的预测结果是不是相同的ID。一个形象的例子就是,如果把训练集看做教科书,测试集看做考试的话,那么就是考点都在教科书中。
而open-set呢,就是测试图片并没有在训练集中出现过。试卷题目的答案在教科书中是找不到的,你用教科书教会你思考的方法举一反三来作答。
此时每张测试图片的预测结果都是一个特征向量,根据两张测试图像特征向量的距离,判断是否是同一个人。
下图是对open-set和close-set的一个直观说明。
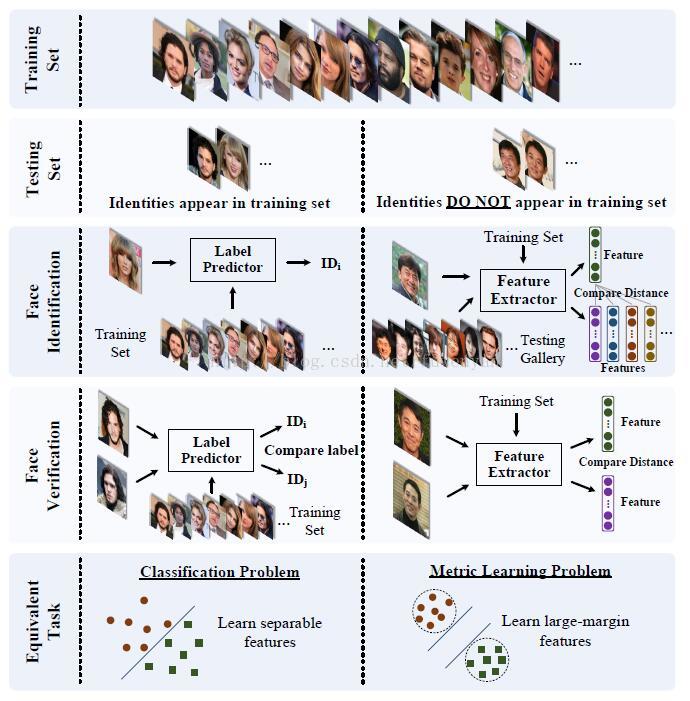
参考:Liu W, Wen Y, Yu Z, et al. SphereFace: Deep Hypersphere Embedding for Face Recognition[J]. 2017.
Open-set recognition is clearly desirable for many biometricrecognition systems, particularly face. For example,surveillance cameras in airports capture people and comparetheir faces with a watch-list of known criminals. Theairport staff, which is not included in the watch-list but regularlypasses through the eye of the camera, should not confusethe algorithm. Hence, this list of known, but uninterestingpeople can be seen as known unknowns during training.Finally, many unknown unknowns, i.e., passengers that arenot on the watch-list and sojourn in the airport need to beignored by the face recognition algorithm
In this paper we introduce a small open-set face identificationevaluation protocol based on the widely used LFWdataset, which previously has mainly been used for evaluatingface verification systems. Particularly, we introduceknown unknowns, i.e., probe images at query timewith identities that were used during training but are notpresent in the gallery; and unknown unknowns, i.e., subjectsat query time whose identities have never been seen bythe system, neither during training nor during enrollment.
