一、is 判断的是内存地址是否相同
在Python中,id是什么?id是内存地址,那就有人问了,什么是内存地址呢? 你只要创建一个数据(对象)那么都会在内存中开辟一个空间,将这个数据临时加在到内存中,那么这个空间是有一个唯一标识的,就好比是身份证号,标识这个空间的叫做内存地址,也就是这个数据(对象)的id,那么你可以利用id()去获取这个数据的内存地址
l1 = [1,2,3]
l2 = [1,2,3]
print(id(l1),id(l2))
print(l1 is l2)
输出结果如下:
2421600222080 2421601939264
False
s1 = 'mrxiong'
s2 = 'mrxiong'
print(id(s1),id(s2))
print(s1 is s2)
输出结果如下:
2421601938672 2421601938672
True
那么 is 是什么? == 又是什么?
==是比较的两边的数值是否相等,而 is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址。
- id相同,值一定相同
- 值相同,id不一定相同
二、代码块
1、代码块
-
代码块:我们所有的代码都需要依赖代码块执行
-
一个文件就是一个代码块
-
交互式命令下一行就是一个代码块
2、两个机制
-
同一个代码块下,有一个机制
-
不同的代码块下,遵循另一个机制
3、同一个代码块下的缓存机制
Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在你给出的例子中,文件执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
l1 = 10000
l2 = 10000
l3 = 10000
print(id(l1),id(l2),id(l3))
输出结果:3045461481424 3045461481424 3045461481424
- 前题条件:同一代码块
- 优点:节省内存、提升性能。
- 适用对现: int、 bool、str
- 具体细则:所有的数字,bool值,机乎所有的字符串
4、不同代码块下的缓存机制:小数据池
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
- 前提条件:不同代码块
- 适用对现: int、 bool、str
- 具体细则:-5----256数字、bool、满 足规则的字符串
- 优点:节省内存、提升性能。
三、集合
python基础数据类型之:集合set。容器型的数据类型,它要求它里面的元素是不可变的数据。但是它本身是可变的数据类型,集合是无序的。{}
- 集合的作用:
- 列表的去重
- 关系测试:交集、并集、差集
1、集合的创建
set1 = {1,3,'mrxing',4,'小米',False,'天气'}
print(set1)
输出结果:
{False, 1, 3, 4, '天气', 'mrxing', '小米'}
由此例子看到,集合是无序的
2、空集合
set2 = set()
print(set2)
3、集合的增
add
set1 = {1,3,'mrxing',4,'小米','三胖','天气'}
set1.add('xxxx')
print(set1)
update迭代着增加
set1.update('A')
print(set1)
set1.update('老师')
print(set1)
set1.update([1,2,3])
print(set1)
4、集合的删
set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
5、变相改值
set1 = {'alex', 'wusir', 'ritian', 'egon', 'barry'}
set1.add('男神')
set1.remove('alex')
print(set1)
6、集合的其他操作
6.1 交集。(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
6.2 并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7,8}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7,8}
6.3 差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
6.4 反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
6.5子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
6.6 frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
7、列表去重
li = [1,2,1,2,3,4,5,6,5,10,1]
set1 = set(li)
li = list(set1)
print(li) #[1, 2, 3, 4, 5, 6, 10]
列表去重,不能保留原来列表的顺序
li = [1,'mrxiong',2,1,2,'mrxiong',3,4,5,6,'mrxiong',5,10,1]
set1 = set(li)
li = list(set1)
print(li) #[1, 2, 3, 'mrxiong', 4, 5, 6, 10]
四、其它
for循环:用户按照顺序循环可迭代对象的内容。
msg = '认证咨询服务机构_全国十大认证机构'
for item in msg:
print(item)
li = ['alex','银角','女神','egon','太白']
for i in li:
print(i)
dic = {'name':'太白','age':18,'sex':'man'}
for k,v in dic.items():
print(k,v)
五、深浅copy
1、先看赋值运算。
l1 = [1,2,3,['barry','alex']]
l2 = l1
l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']]
l1[3][0] = 'wusir'
print(l1) # [111, 2, 3, ['wusir', 'alex']]
print(l2) # [111, 2, 3, ['wusir', 'alex']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的,在举个例子,比如张三李四合租在一起,那么对于客厅来说,他们是公用的,张三可以用,李四也可以用,但是突然有一天张三把客厅的的电视换成投影了,那么李四使用客厅时,想看电视没有了,而是投影了,对吧?l1,l2指向的是同一个列表,任何一个变量对列表进行改变,剩下那个变量在使用列表之后,这个列表就是发生改变之后的列表。
2、浅copy
l1=[1,2,3,[22,33]]
l2 = l1.copy()
l1.append(666)
print(l1,id(l1))
print(l2,id(l2))
输出结果:
[1, 2, 3, [22, 33], 666] 3011484790656
[1, 2, 3, [22, 33]] 3011484790400
l1=[1,2,3,[22,33]]
l2 = l1.copy()
l1[-1].append(666)
print(l1,id(l1))
print(l2,id(l2))
输出结果:
[1, 2, 3, [22, 33, 666]] 2821469319040
[1, 2, 3, [22, 33, 666]] 2821469318784
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。

3、深拷贝deepcopy
import copy
l1=[1,2,3,[22,33]]
l2=copy.deepcopy(l1)
print(id(l1))
print(id(l2))
l1[-1].append(666)
l1.append(777)
print(l1)
print(l2)
输出结果:
2353320427712
2353322012352
[1, 2, 3, [22, 33, 666], 777]
[1, 2, 3, [22, 33]]
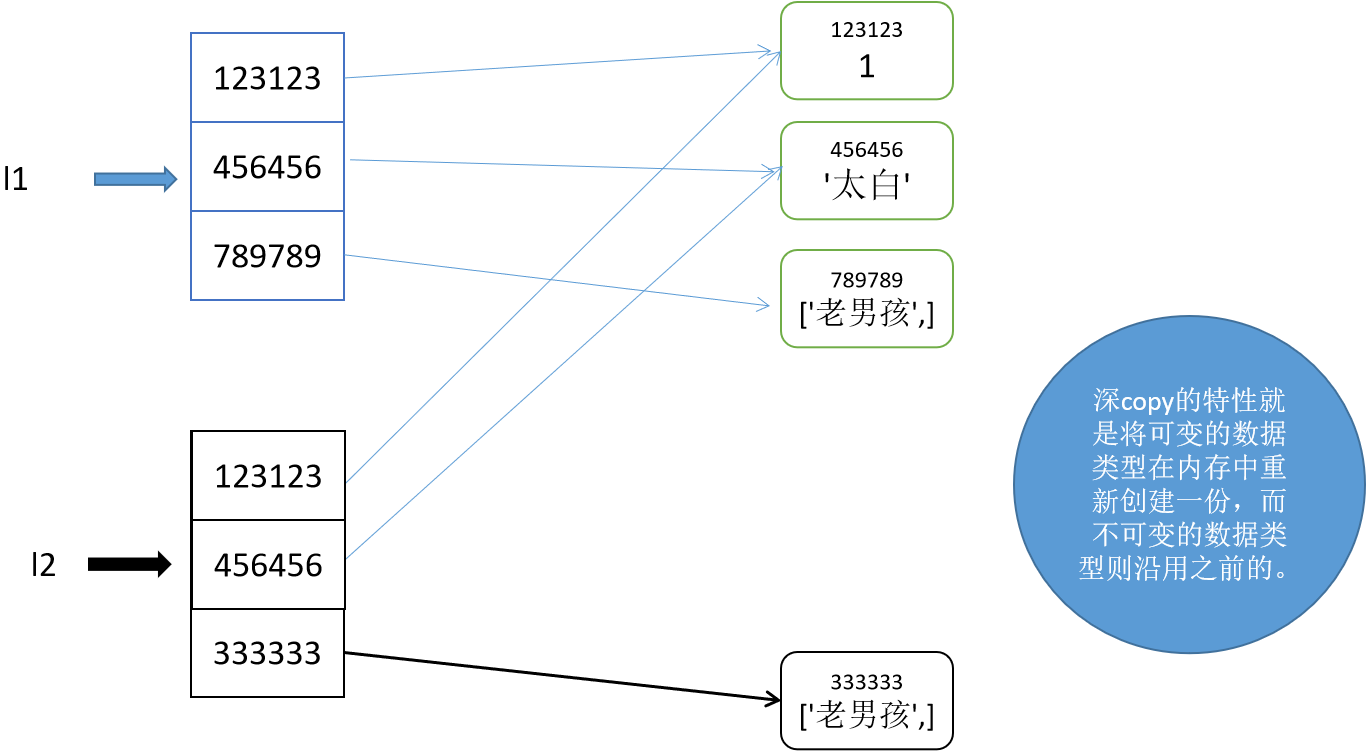
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
l1 = [1, 2, 3, 4, ['alex']]
l2 = l1[::]
print(l2)
l1[-1].append(666)
print(l1)
print(l2)
浅copy:list dict:嵌套的可变的数据类型是同一个
深copy:list dict:嵌套的可变的数据类型 不是同一个
六、练习
1、请用代码验证name是否是在字典的键中?
info = {'name':'张三','hobby':'铁狂','age':18}
info = {'name':'张三','hobby':'铁狂','age':18}
print('name' in info.keys())
2、请用代码验证张三是否是在字典的键值中?
info = {'name':'张三','hobby':'铁狂','age':18}
info = {'name':'张三','hobby':'铁狂','age':18}
print('张三' in info.values())
3、循环提示用户输入,并将输入内容追加到列表中(如果输入N或者n则停止循环)
l1 = [1, 2, 3, 4, '李四']
while 1:
a = input('请输入需要追加到列表的内容,如果退出输入n:')
if a.upper() == 'N':
print('程序结束~!')
break
else:
l1.append(a)
print(l1)
4、循环提示用户输入,并将输入内容追加到集合中(如果输入N或者n则停止循环)
set1 = {1,3,'mrxing',4,'小米',False,'天气'}
while 1:
a = input('请输入需要追加到集合的内容,如果退出输入n:')
if a.upper() == 'N':
print('程序结束~!')
break
else:
set1.add(a)
print(set1)
5、看代码判断结果
info = [1, 2, 3]
user_list = []
for item in range(10):
user_list.append(info)
info[1] = '是谁说python好学的?'
print(user_list)
结果输出:
[[1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3], [1, '是谁说python好学的?', 3]]
七、7的倍数游戏
让用户随便输入数字,从1开始数数,遇到7或7的倍数时侧在列表中添加一个'咣'
num = int(input('请输入随便一个数字:'))
ls=[]
for i in range(1,num+1):
if str(i).find('7') == -1 and i % 7 != 0 : #把i转成字符串,使用find方法(字符串中不包含时,返回-1)
ls.append(i)
else:
ls.append('咣')
print(ls)