缓存里放的是一些平时不怎么变动的数据,当用户查询时,可以直接从缓存里查询。缓存集群的并发能力是很强的,而且读缓存的性能是很高的,缓存其实在系统架构里是非常重要的组成部分。很多时候,对于那些很少变化但是大量高并发读的数据,通过缓存集群来抗高并发读,是非常合适的。
但是在使用过程中,会出现热点缓存问题,简单的说就是突然因为莫名的原因,出现大量的用户访问同一条缓存数据,最终导致缓存集群全盘崩溃,引发系统集体宕机。所以对于这种热点缓存,最关键的一点就是你的系统需要能够在热点缓存突然发生的时候,直接发现他,然后瞬间实现毫秒级的自动负载均衡。此时完全可以基于大数据领域的流式计算技术来进行实时数据访问次数的统计,比如storm、spark streaming、flink,这些技术都可以实现。比如在实时数据访问次数统计的过程中,发现某条数据访问次数在短时间内突然增多超过一个危险数值,就把这条数据判定为热点数据。
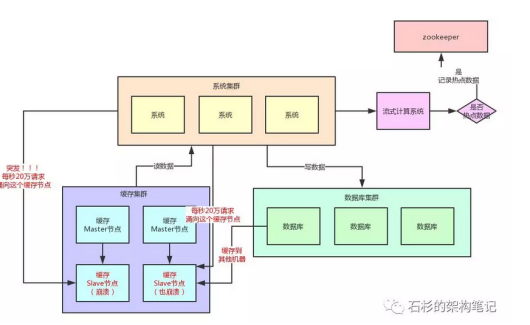
--流程图,引用自文章“如果20万用户同时访问一个热点缓存,如何优化你的缓存架构?”
我们自己系统可以对zookeeper指定的热点缓存对应的znode进行监听,有变化时进行感知。此时系统层就可以立刻把相关缓存数据从数据库加载,然后存放在本地缓存。这个本地缓存,主要说的就是将缓存集群里的集中式缓存,直接变成每个系统自己本地实现缓存即可,每个系统自己本地是无法缓存过多数据的。之后对热点缓存的读取操作,直接将本地缓存读取即可。
除此之外,在每个系统内部,其实还应该专门加一个对热点数据访问的限流熔断保护措施。通过系统层自己直接加限流熔断保护措施,可以很好的保护后面的缓存集群、数据库集群之类的不要被打死。