大型网站特点:
高并发,高可用,海量数据, 用户分广泛, 网络情况复杂, 安全环境恶劣, 需求快速变更,发布频繁.
发展历程
单一服务器
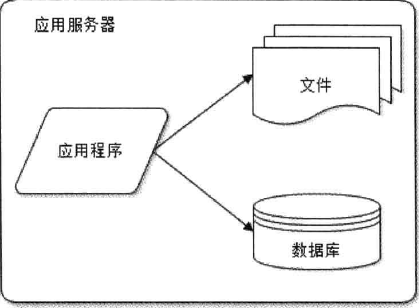
应用与数据服务分离, 数据库压力大, 影响性能.
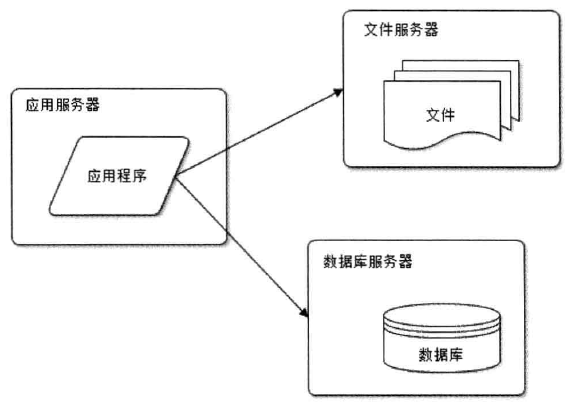
使用缓存, 改善网站性能. 缓存一般都是在内存中, 所以增加了读取的速度. 提高了网站性能.
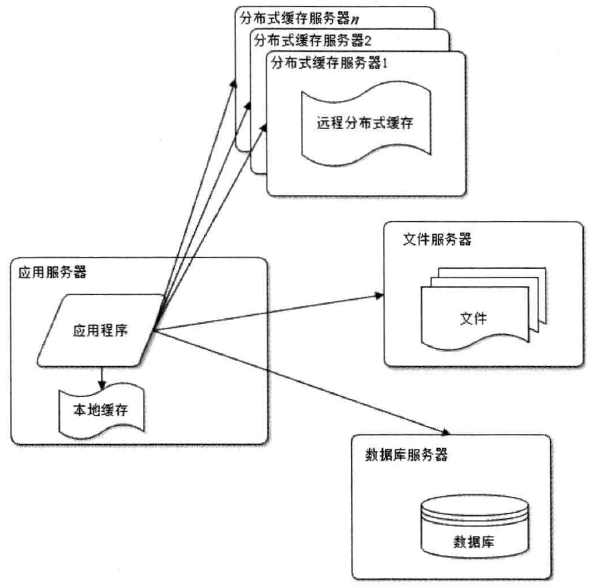
使用应用服务器集群, 改善并发能力, 负载均衡调度
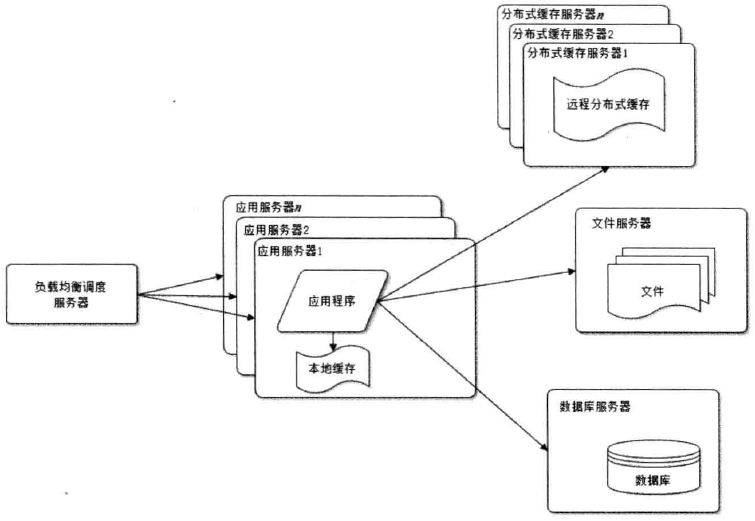
数据库读写分离
实际上, 使用缓存以后, 绝大部分的请求都不需要直接读取DB,而是从缓存来, 但是即便这样, 还是有少量数据需要读取DB,
而与当前的规模相比, 此时DB的能力又出现问题, 于是出现了读写分离的solution.
数据库主从热备,通过配置两个数据库的主从关系,可以将一个数据库的信息同步到另一个数据库中。利用这一功能,可以实现读写分离,
减轻 DB 的压力. 而此时还不需要数据库中间件, 读请求去一个DB, 写请求去另一个DB.
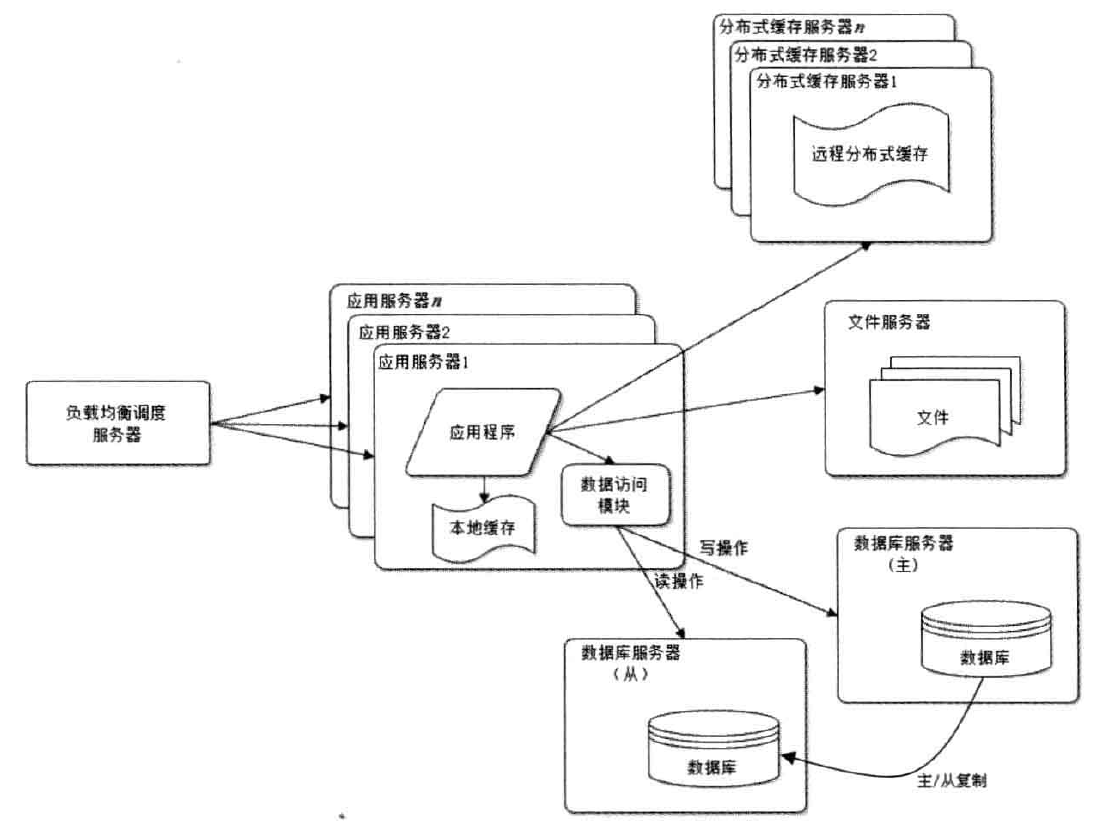
CDN 和 反向代理
CDN 和 反向代理的基本原来都是缓存, 区别在于 CDN 部署在网络提供商的机房,使用户在请求网站服务时,可以从距离自己最近的网络提供商机房
获取数据。而反向代理是部署在网站的中心机房,当用户请求到达中心机房后,首先访问的服务器是反向代理服务器,如果反向代理服务器中缓存着
用户请求的资源,就直接提供给用户.

分布式数据库, 分布式文件系统
之前已经将 DB 拆分成主, 从, 但是还是无法解决大量的访问,比较常用的方式是业务分库, 按照业务数据部署在不同的物理服务器上.
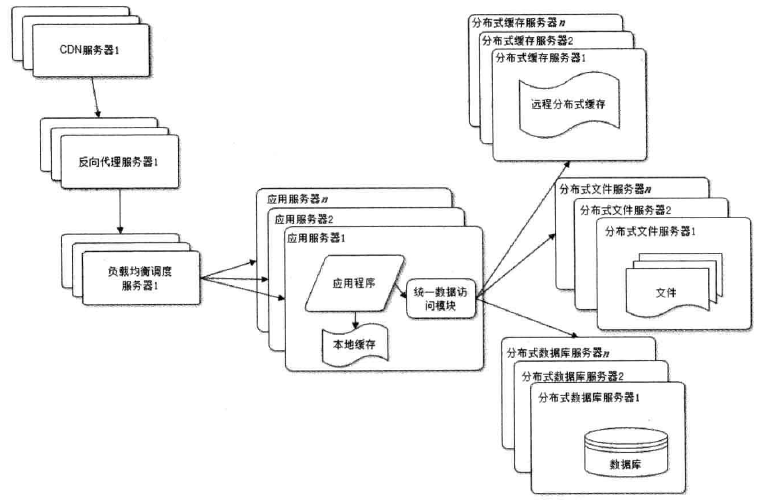
NOSQL 和 搜索引擎
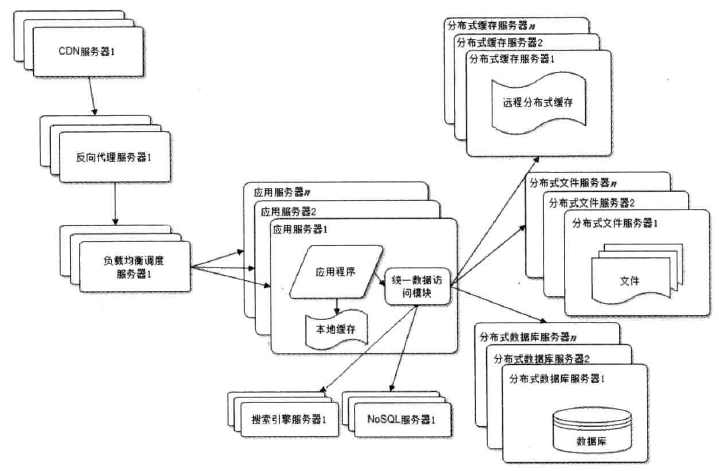
业务拆分
通过分而治之的手段, 将整个网站拆分成不同的产品线(product 思维)
具体到技术上,也会根据产品划分,将一个网站拆分成多个应用,每个应用独立部署和维护,应用之间可以通过标准的 RestfulAPI建立联系,
也可以用消息队列进行消息传递,当然最多的还是通过访问同一个存储系统来构建一个关联的系统体系.
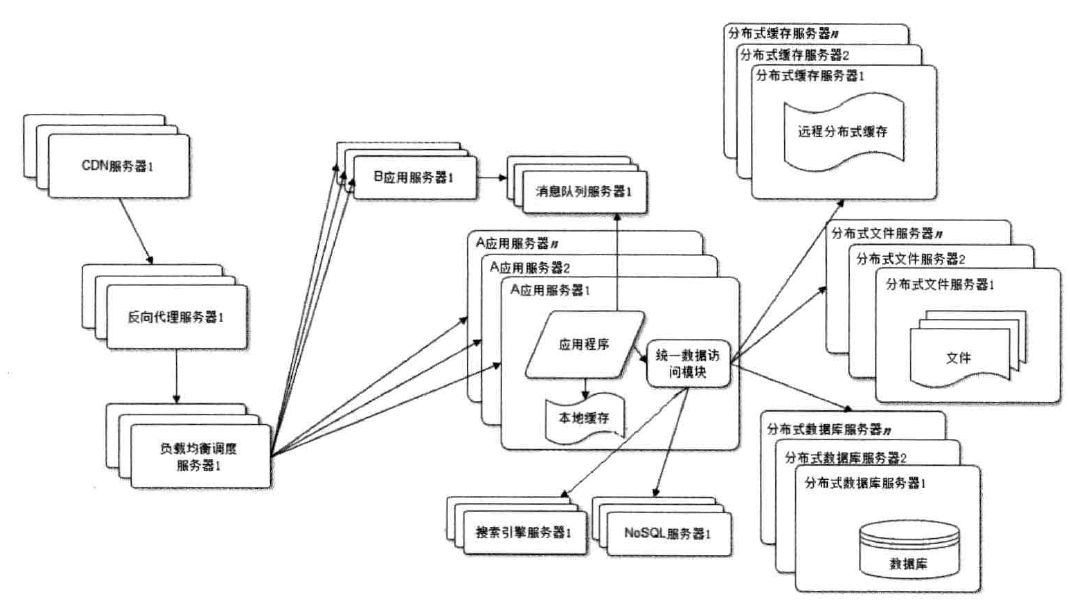
分布式服务
随着业务拆分越来越小,存储系统越来越庞大,应用系统整体复杂度直线上升,部署和运维越来越困难。由于所有应用和所有数据库连接,
在数万台服务器规模的网站中,连接数是服务器数目的平方,导致数据库资源不足,拒接服务。
既然每一个应用系统都需要执行许多业务操作,比如用户管理,那么,可以将这些共用的业务提取出来,独立部署。由这些可复用的业务连接数据库,
提供共性服务,而应用系统只需要管理用户界面,通过分布式服务调用共性服务完成业务操作。
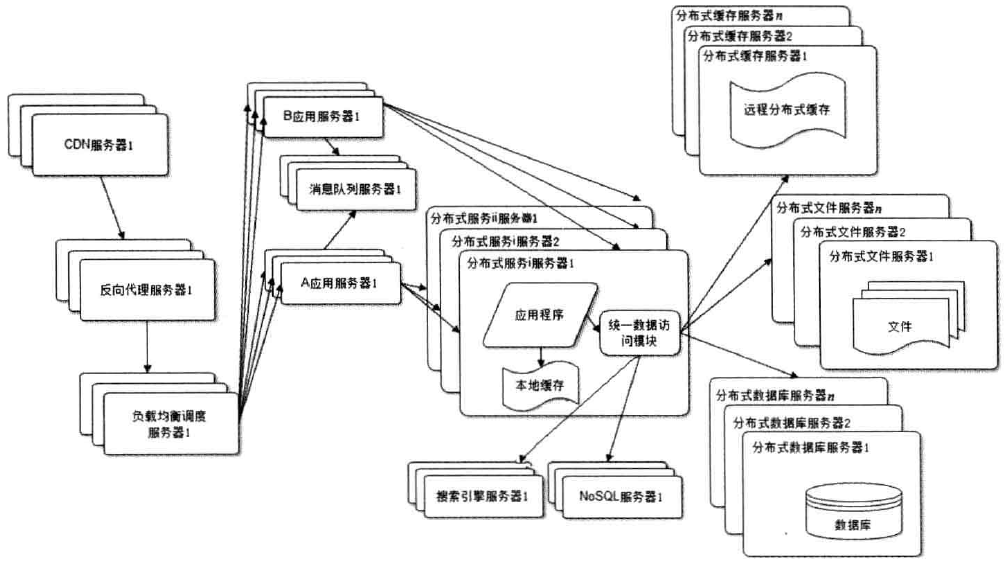
演化到此, 基本上很多问题都得以解决.
现在很多大型网站转向云平台.
网站设计的误区
一味追求大公司的解决方案.
为了技术而技术
不要想着用技术去解决所有为题, 比如 12306,最后的方式是分时售票, 引入排队机制等.