下载安装的 JDK 目录
java 主目录下的: src.zip 是 jdk 的源代码.
JDK: java development kit 包含java 编译器和JRE
JRE: java run environment java 运行时环境,JRE 包含 JVM
JVM: java virtual machine java 的虚拟机, 真正跑 class 文件的.
JAVA 内存结构
java 虚拟机内存分为3个区域, 栈stack, 堆heap, 方法区method area
底层都类似的,各种语言互相抄袭的.
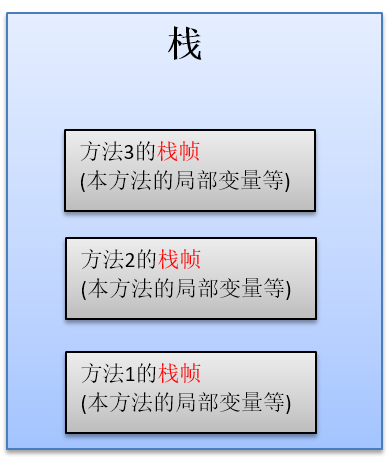
栈 stack
表示方法执行的内存模型, 每个方法被调用都会创建一个栈帧(栈帧是栈内部的一个独立的存储空间)(存储局部变量, 操作数, 方法出口 等)
JVM 为每个线程创建一个栈, 用于存放该线程执行方法的信息(实际参数,局部变量等)
栈属于线程私有, 不能实现线程间的共享。
栈的存储特性是“先进后出”
栈由系统自动分配,速度快,栈是一个连续的内存空间.
堆heap
堆用于存储创建好的对象和数组(数组也是对象) {对象的所有东西都存储在这里, 包括实例变量, 比如 new一个对象, 那么全部都在这里}
JVM 只有一个堆, 被所有线程共享.
堆是一个不连续的内存空间, 分配灵活, 速度慢.
方法区 (又叫静态区)
JVM 只有一个方法区, 被所有线程共享。
方法区实际上也是堆,只是用于存储类(不是实例, 而是类[模板]), 常量的相关信息.
用于存储程序中永远不变或唯一的内容(类信息, 静态变量,字符常量 等)
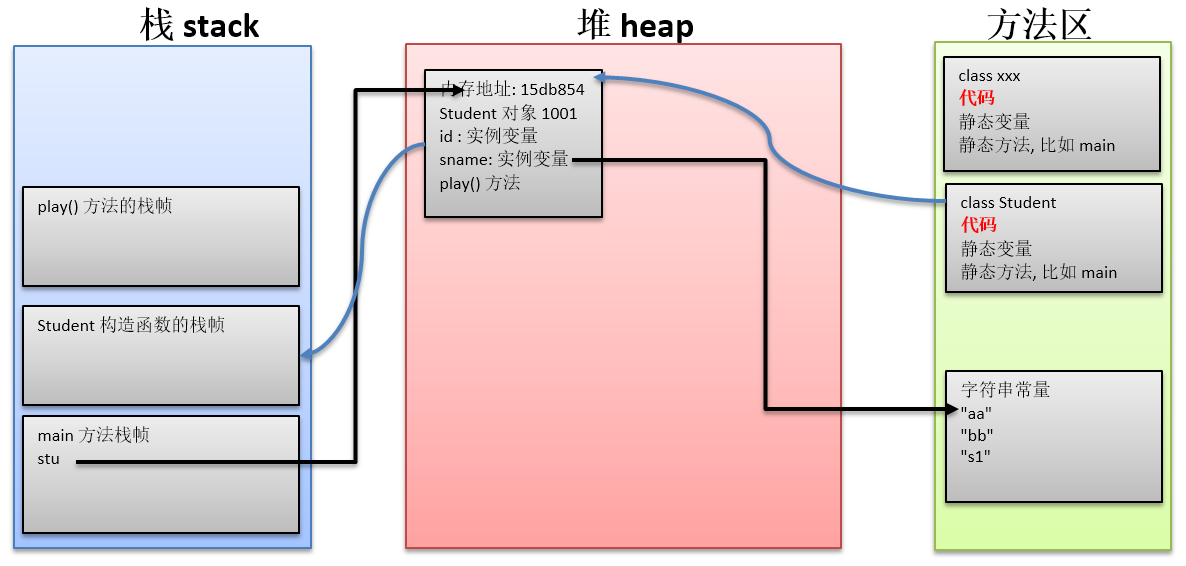
画一个程序内存走势
1. java xxx 开始执行程序. 这时候开始启动虚拟机, 分配内存空间(栈和堆)
2. 将 文件名相同的类(也就是main方法所在的类), 这个类本身加载到内存的方法区中. 也就是将 xxx 加载到方法区.
然后找到 static 的 main方法(xxx的静态方法刚才都已经在内存中了), 然后可以执行这个 main 方法.
3. 这时候在栈空间开辟 main 方法的 栈帧, 然后 main 方法里有 stu = new Student(),
这时: (新建对象的过程)
a. 首先执行类加载过程(如果此时Student类本身没在方法区), 加载类之后, 这个类的相关代码就在内存中了(也就是方法区中)
b. JVM 在堆中为新生成的对象Student 开辟内存空间. 对于分配内存的大小, 在Student类本身加载到方法区后, 就可以知道了.
c. 将构造函数放到栈 stack 中, 开始进行对象初始化工作.
d. 将新开辟内存的地址返回给 main 函数中的 stu 局部变量.
4. 根据main函数的执行, stu.id = 1001, stu.sname = "aa", 这样就会在堆的对象中, 对实例变量进行赋值.
5. 当调用 stu.play() 时, 找到堆中该对象的 play()方法的内容, 将play方法入栈, 开始执行 play() 方法中的内容.
Comment: 栈中的函数执行完之后, 就会出栈(根据栈的规则)
JVM 调优与垃圾回收
垃圾回收
引用计数: 判断对象是否要回收, 但是如果是循环互相引用,就会有问题。
引用可达法: 所有的引用关系做一张图,(貌似可以排除循环互相引用)
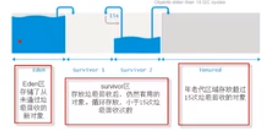
分代垃圾回收机制: 年轻代(新创建的对象),年老代(新创建之后过了一段时间),持久代(不用回收)
持久代: 用于存储静态文件, 如类方法,静态变量等. (一直在内存中, 也不变化,不会被移出内存) 这个区满了,会调用 FullGC来清理(要注意)
年轻代: 分为 Eder 和 Suvivor 两个区域.
Eder, Suvivor {Eder 满了,触发垃圾回收GC(Minor GC) -> 将留下来的对象copy放到 Suvivor1Suvivor2 中, 然后清空Eder, 然后再新增加对象到Eder区}
依次类推, 这样如果迭代15次, 对象还在Suvivor中, 就把该对象放到 Tenured/Old 区.
年老代old: 只有一个区, 名字叫 Tenured
Tenured: 当这个区的占用达到一定比例, 就会触发 Major GC 来清理这个Old区. 如果Old 区满了,就会触发 Full GC.(影响性能)
GC(垃圾回收) 的分类
Minor GC: Eder 满了触发,用于清理年轻代区域.
Major GC: 用于清理年老代区域.
Full GC: 对所有的区域做 GC 清理, 这个代价很高,我们很多时候优化,都是对这个 Full GC 做优化. (尽量不要使用Full GC)
System.gc(); 这实际只是发一个请求,掉GC, 这只是一个建议,但是,程序是否真正掉GC, 还是有垃圾回收器决定。
对象创建与 this
创建一个对象分为如下四步:
- 分配对象空间,并将对象成员变量初始化为0, false 或空
- 执行属性值的显式初始化, 比如属性值等于一个静态变量或字符常量等.
- 执行构造函数, 在这里都可以使用 this, 因为通过上面1,2两步,实际上对象已经创建好了.
- 返回对象的地址给相关的变量, 比如 Student stu = new Student(), 就返回地址给了 stu.
this 的本质就是创建好的对象的地址。this(a,b) 实际上是调用构造函数. 必须位于第一句. this 不能用于static方法中.
继承的初始化过程从继承树向上, 首先执行爷爷的初始化 -> 爸爸的初始化 -> 自己的初始化. 因为 super() 一层一层往上调用父类的构造器.
静态导入
import static java.lang.Math.PI; // 相当于导入这个类的静态属性, 也可以使用 import static java.lang.Math.* 就是导入这个类的所有的静态属性和方法.
这样导入之后, 在程序中, 就不用在写 类似 System.out.println(Math.PI), 而是可以直接写System.out.println(PI) , 但是个人觉得还是之前那种看着习惯.
封装的一般规则
类属性: private 修饰,暴露方法来修改这个属性, 可以加 validation.
javaBean: 只提供了属性的get 和 set 方法的简单方类. 没有复杂逻辑功能。
需要被外部访问的,一般情况下方法都是用 public.
多肽3个必要条件
继承, 方法重写, 父类引用指向子类对象(向上转型).
final 关键字
final 修饰变量是常量.
final 修饰方法: 方法不能被子类重写,可以被重载.
final 修饰类: 此类不能被继承. (这个类就是最终的类, 此类不能再被扩展了) 比如 String 这个类就是一个 final 类.
数组
数组是一个对象,数组的每一个元素可以看做是这个对象的成员变量.
三种初始化
静态初始化: int[] a = {1, 2, 3};
动态初始化: int[] a = new int[3]; a[0] = 1; 先分配空间, 之后分别单独初始化
默认初始化: 默认的, 比如 int[] a = new int[3]; 这时就是数组元素默认初始化为 0
for each 循环 : 只能读取, 而不用于修改, 因为没有下标, 但是适合遍历数组
for ( int m: a ) {
}
抽象类 与 抽象方法
- 有抽象方法, 只能定义成抽象类
- 抽象类不能实例化,即不能用 new 来实例化抽象类
- 抽象类可以包含属性,方法,构造方法,但是构造方法不能用来 new 实例, 只能用来被子类调用.
- 抽象类只能用来被继承
- 抽象方法必须被子类实现(重写Override)
抽象类的意义 为子类提供统一的,规范的模板,子类必须实现抽象方法。例如 Number 类(包装类) 就是一个抽象类.
接口
只能定义 常量 或 抽象方法. (即便不加 final 或 abstract, 默认的就是常量和抽象方法), 而且全部都是 public 的.
因为接口需要稳定
内部类
非静态内部类: Outer.Inner inner = new Outer().new Inner(); // 定义内部类, 必须要有外部类, 因为这时内部类相当于外部类的成员变量.
所以也就是说,非静态内部类依托外部对象(实例)。
静态内部类: 理解为outer 类的一个内部类变量, 这时不再依托外部类实例. (使用不多)
匿名内部类: 这个内部类只调用一次. 别的地方不再用.
this.addWindowListener(new WindowAdapter() {
@Override
public void windowClosing(WindowEvent e) {
System.exit(0);
}
});
数组
Arrays 这个类集成了一些数组的方法,可以直接调用, 比如排序等.
包装类自动装箱拆箱
Integer a = 234; 对象, 装箱
int b = a; int 型, 拆箱
Collection
ArrayList, LinkedList: 线性结构
因为 java 不像 C 语言, 允许动态分配数组, 所以, 实际上可以使用普通数组来构建ArrayList, 比如每当数组长度超过80%时,
就创建一个新数组(2倍长度于原来数组), 并copy 这个数组到新数组里.
下边是 key, value 的形式:
HashSet: set 是无序不可重复的.
TreeSet: TreeSet 底层是 TreeMap 实现的, 通过 key 来存储 Set 元素, TreeSet是一维的, 比如 Set<User> = new TreeSet<User>();
HashMap: Map<Integer, String>m1 = new HashMap<>();
散列码: 首先将键key 转换为散列码整数, 每个Java对象都有散列码. 散列码是32位整数
散列码是通过 hash 函数计算得到的数值,一般情况下, 不同的对象, 散列码是不同的. 在数学中, 要将较大的组映射到较小的组上时, 必须使用重复,比如你有6个球, 想放到5个抽屉里, 那必然会有重复出现, 而一般在数学上,我们可以采取取模的方式, 这样抽屉1可能就重复了,对于重复的情况,应该继续查找. 手工解决这种重复问题, 举例:
首先考虑数据结构, 我们使用了一个对象 HashEntry 来存储, 这个对象有3个实例变量, key,value,link指针, 也就是说, 当有重复发生时, 这个指针变量可以帮助这些重复的hashcode值来继续遍历这个link链表. 还拿放球的例子, 本例中, N_BUCKETS = 5, 而我们实际有6个球, 执行过程是:
1,2,3,4,5 球来了, 都正常进入相应的 bucketArray 数组中, 当 6 来了时, 把6作为 bucketArray[1] 的第一个元素, 原来的的1是6的后继. 这样前插入链表的好处是, 不用遍历链表, 直接插入在链表头.
链表头插入:

package com.hash.duplicate; public class SimpleStringMap { public SimpleStringMap() { bucketArray = new HashEntry[N_BUCKETS]; } public void put(String key, String value) { int bucket = Math.abs(key.hashCode()) % N_BUCKETS; HashEntry entry = findEntry(bucketArray[bucket], key); if (entry == null) { entry = new HashEntry(key, value); entry.setLink(bucketArray[bucket]); bucketArray[bucket] = entry; } else { entry.setValue(value); } } public String get(String key) { int bucket = Math.abs(key.hashCode()) % N_BUCKETS; HashEntry entry = findEntry(bucketArray[bucket], key); if (entry == null) { return null; } else { return entry.getValue(); } } public HashEntry findEntry(HashEntry entry, String key) { while (entry != null) { if (entry.getKey().equals(key)) return entry; entry = entry.getLink(); } return null; }private static final int N_BUCKETS = 5; private HashEntry[] bucketArray; } class HashEntry { public HashEntry(String key, String value) { entryKey = key; entryValue = value; } public String getKey() { return entryKey; } public String getValue() { return entryValue; } public void setValue(String value) { entryValue = value; } public HashEntry getLink() { return entryLink; } public void setLink(HashEntry nextEntry) { entryLink = nextEntry; } private String entryKey; private String entryValue; private HashEntry entryLink; // a reference to the next entry in the chain. }
TreeMap: 一般不用, 需要map 中排序时会使用, 是通过红黑二叉树实现的.
因为是 key,value 存储, 键值是否重复, 根据 equals 方法可以比较. 也就是说, JAVA 对象的散列码通过 hashcode()函数得出来的散列码就等于equals方法,也是判断对象是否相等的依据. 所以尽量不要重写equals方法,因为重写equals方法, 就要重写hashcode方法.
