数据的重塑和轴向旋转
- 行列层次化索引
- Series转DataFrame
- 索引交换层次
- 每个索引项都是个元组 按正常索引序列访问既可
- 数据旋转/行列转化 转置
import numpy as np
import pandas as pd
df=pd.read_excel("movie_data2.xlsx")
df[:5]

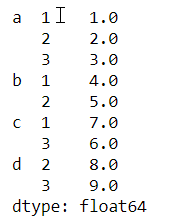
层次化索引
s=pd.Series(np.arange(1,10),index=[['a','a','a','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,3]])
s

s.index

Series转DataFrame
不堆叠unstack 将series 变成dataframe
s.unstack().stack()
对Dataframe 行列层次化索引
data=pd.DataFrame(np.arange(12).reshape(4,3),index=[['a','a','b','b'],[1,2,1,2]],columns=[['A','A','B'],['Z','X','C']])
print(data)
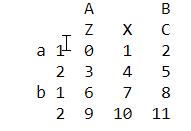
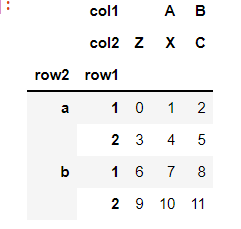
索引交换层次
data.index.names=['row2','row1']
data.columns.names=['col1','col2']
data
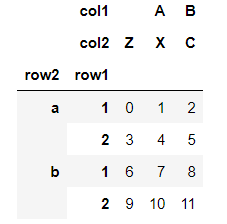
data.swaplevel('row1','row2')
data
set_index把列变成索引 reset_index把索引变成列
df=df.set_index(['产地','年代'])
df

每个索引项都是个元组 按正常索引序列访问既可
df.index[0]
(‘美国’, 1994)
行标签索引行数据 两边闭区间 以年代为索引
df.loc['美国']

取消层次化索引
df=df.reset_index()

数据旋转

分组与聚合 (groupby/数据透视表格pivot_table)
group=df.groupby(df['产地'])
type(group)
group.sum()

使用聚合函数
df['评分'].groupby(df['年代']).mean()

groupby多个分组变量
df.groupby([df['产地'],df['年代']]).mean()

#每个地区 每一年的评分的均值
group=df['评分'].groupby([df['产地'],df['年代']])
mean=group.mean()
mean

mean.unstack().T#转为dataframe

离散化,分组/区间化处理
python 之 .cut函数:
区间化的定义 x数组 bins区间/序列 分组依据 right右端点 include_lowest左端点 labels 定义的名称等级
pd.cut(x,bins,right = True,labels = None,retbins=False,precision = 3,include_lowest = False)
df['评分等级'] = pd.cut(df['评分'],[0,3,5,7,9,10],labels = ['E','D','C','B','A'])
df.head(10)

根据百分数的分布来切割区间 投票人数的排序分成五份 排名每20%作为一个等级
bins = np.percentile(df['投票人数'],[0,20,40,60,80,100])
df['热门程度'] = pd.cut(df['投票人数'],bins,labels = ['E','D','C','B','A'])
df

合并数据集的三种方法
.append
将数据集拆分成多个 再进行合并
df_usa = df[df.产地=='美国']
df_cn = df[df.产地=='中国大陆']
df_cn.append(df_usa)
pd.merge
python 之pd.merge函数
pd.merge(left,right,how=‘inner’,on=None,left_on = None)
left:左边的对象
right:右边对象
on:要加入的列:交集 连接键 左连接 右连接 内连接
left_on:如果不同 则自己指定
right_on:
sort:按照连接件 排序
suffixes:前缀 重复键 自定义后缀
df1 = df.loc[:5]
df1
df2 = df.loc[:5][['名字','产地']]
df2['票房'] = [123344,23454,343543,435,222,555]
df2


将数据表格打乱后重新设置索引
df2 = df2.sample(frac = 1)
df2

df2.index = range(len(df2))
df2
合并
pd.merge(df1,df2,how = "inner",on = '名字',)

pd.concat
多个数据表 进行某一维度的拼接
