1. 引言
最近心血来潮去参加了一个PL/SQL工程师的面试,期间被问到了Oracle分析函数,PL/SQL开发并非我的老本行,在之前的工作中,也很少使用分析函数,原因之一是对数据库移植问题的考虑;其二是很少遇到非用分析函数不可的情况;其三是分析函数的语法相对复杂,令人缺乏兴趣。这几天看了一些入门内容,发现它们还是很强大的,唯一的遗憾是目前身边没有真实的应用场景,所以这里举的例子看起来难免有点纸上谈兵的感觉。
2. 分析函数(Analytic function)与聚合函数(Aggregate function)
我们先从“ORA-00979: not a GROUP BY expression”说起,相信大家在开始使用SQL的过程中都遇到过这个错误,比如你写了下面这样的SQL:
FROM film
GROUP BY corp
ORDER BY corp;
ORA-00979错误表明,SELECT子句中出现的字段,要么包含于GROUP BY子句,要么作为聚合函数(上面的COUNT)的输入,除此之外不能包含其它字段。我们可以修改上面的SQL使它可以正常运行:
FROM film
GROUP BY corp
ORDER BY corp;
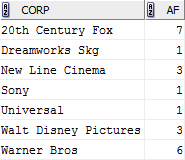
这就引出了聚合函数的一个主要特征,聚合之后,同组只保留下一条数据,由上图可知表中由“20th Century Fox”公司出品的影片共有7部,最终记录是一条。
这符合某些统计需求,然而有时候,我们并不希望聚合函数中的这种“合并”操作,尤其是我们常常希望在SELECT子句出现未参与统计的字段,此时我们便可以使用分析函数。对于表中的每一行记录,分析函数都能返回一个统计值,下面我们来看一个具体的实例:
COUNT(*) OVER (PARTITION BY corp) af
FROM film;
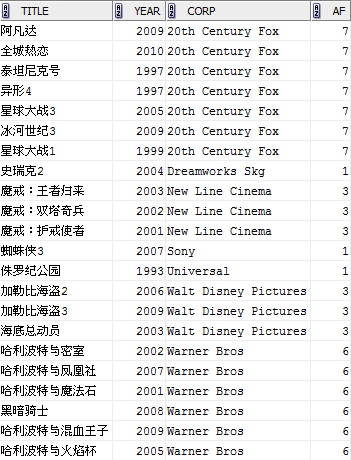
注:PARTITION BY不仅导致分区(类似于GROUP BY),而且分区之间是排序好的,也算是它的一个“副作用”。
3. 基本语法
function_name(arg1,arg2,...) OVER (<partition-clause> <order-by-clause > <window clause>)
其中<order-by-clause >子句会在下面的例子中穿插提到,<window clause>子句则会在最后一节进行解释。
另外,还需要提到的一点是,在有分析函数参与的SQL语句中,执行流程依次是:
1) JOIN, WHERE, GROUP BY, HAVING
2) 创建分区(通常通过PARTITION BY),而后分析函数将作用于分区中的每一行
3) 主语句中ORDER BY(这个我们以前就知道,主语句的ORDER BY总是最后执行)。
4. AVG, SUM, MAX, MIN, COUNT
这些大家熟知的聚合函数,同样可作为分析函数使用,当然要符合第3节中给出的分析函数的语法,下面我们来看几个实例:
ROUND(AVG(box_office) OVER (PARTITION BY corp)) af
FROM film;
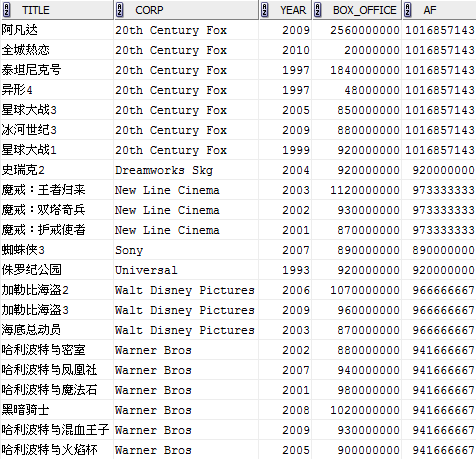
让我们看看在OVER内应用ORDER BY之后的情形:
COUNT(*) OVER (PARTITION BY corp ORDER BY year) af
FROM film;
这个结果容易让人非常困惑,实际上OVER内的ORDER BY子句导致了分区(PARTITION)内的数据进行了逐步累加。通常,这种“累加”始于排序后该分区的第一条记录,结束于当前记录。当排序列出现相同值(比如上面的两个1997、两个2009),累加则结束于相同记录的最后一条。
让我们再来看一个例子:
MAX(box_office) OVER (PARTITION BY corp ORDER BY year) af
FROM film;
5. RANK, DENSE_RANK, ROW_NUMBER
 代码
代码

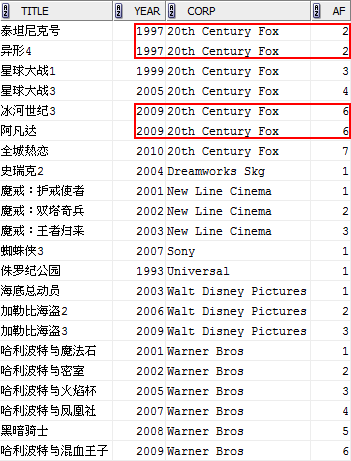
RANK() OVER (PARTITION BY corp ORDER BY year) r,
DENSE_RANK() OVER (PARTITION BY corp ORDER BY year) dr,
ROW_NUMBER() OVER (PARTITION BY corp ORDER BY year) rn
FROM film;
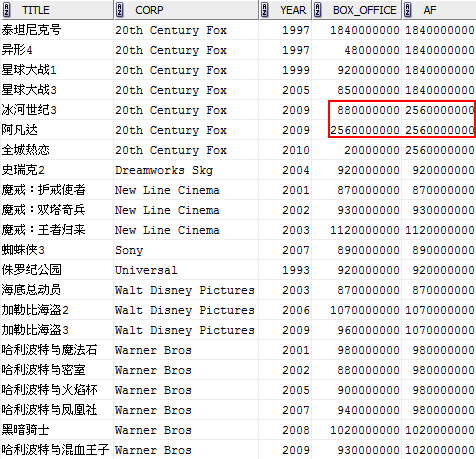
![]()
RANK, DENSE_RANK, ROW_NUMBER具有类似的行为,只有当排序列包含重复值时,它们的区别才能体现出来。注意上图中红色标识部分,对于相同的年份1997,RANK, DENSE_RANK都返回相同的值,不同的时,DENSE_RANK采用密集编号,两个1之后接着的编号是2。对于ROW_NUMBER,则总是产生连续的编号。
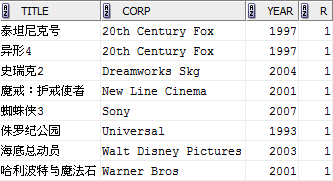
利用这几个函数的特性,可以相对简单地实现TOP N的查询,例如查询表中各电影公司年份最早的电影:
SELECT title,corp,year,
RANK() OVER (PARTITION BY corp ORDER BY year) r
FROM film
) t
WHERE t.r=1;
6. LEAD, LAG
基本语法:
LEAD(<sql_expr>, <offset>, <default>) OVER (<analytic_clause>)
LAG(<sql_expr>, <offset>, <default>) OVER (<analytic_clause>)
<sql_expr> :通常是字段名。
<offset> :表示相对于当前行的偏移幅度(对LEAD来说是向后偏移,对LAG来说则是向前),正整数,默认为1。
<default> :当偏移幅度超出该分区(PARTITION)的范围时返回的值。
LEAD(box_office,1,-9999) OVER (PARTITION BY corp ORDER BY box_office) af1,
LAG(box_office,1,-9999) OVER (PARTITION BY corp ORDER BY box_office) af2
FROM film;
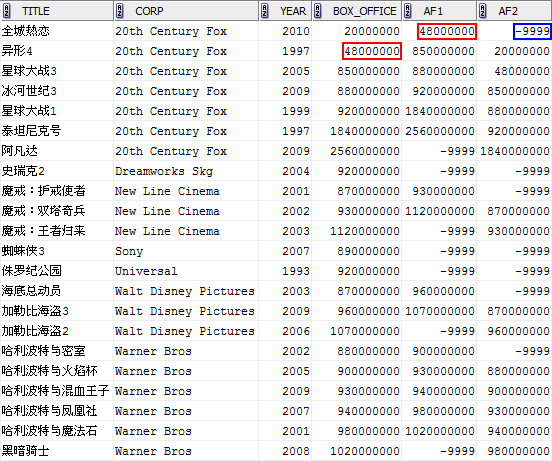
我们先来分析LEAD函数的结果,即上图中的AF1字段,对于同一行分区内,AF1字段第N行的值 = 原BOX_OFFICE第N+1行的值,参见红色标识部分。为什么是N+1呢?实际这取决到我们在SQL语句中指定的offset,我们上面指定的是1。
如果偏移之后超过了分区的范围,则返回函数中指定的default值,这里我们指定的是-9999。
LAG与LEAD类似,只不过它的偏移是向前的,这点与LEAD相反。
7. FIRST_VALUE, LAST_VALUE
FIRST_VALUE返回各分区内指定排序后的第一条记录的值,LAST_VALUE则返回最后一条记录的值。
box_office-(FIRST_VALUE(box_office) OVER (PARTITION BY corp ORDER BY box_office)) af
FROM film;
8. Window子句
我们在第3节提到了分析函数中还有一个window clause,该子句为分析函数指定统计“窗口”。在前面的例子中,大多数的统计“窗口”都是整个分区(PARTITION),也就是说每个统计结果值都是基于相应分区内的所有数据计算而得。使用Window子句则可以将统计“窗口”进一步缩小,我们看一个例子:
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING) af
FROM film;
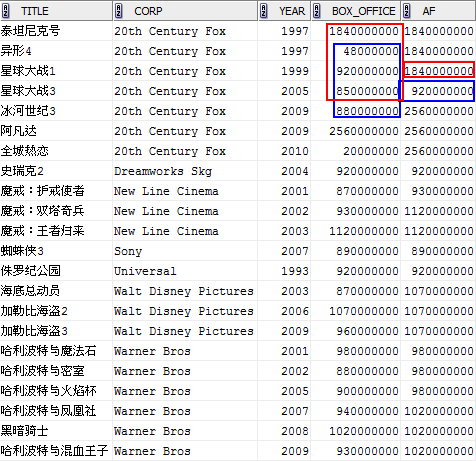
由于分析函数中给定的窗口是ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING,基本上我们可以按字面意思理解“2 Preceding”跟“1 Following”,这表示“窗口”始于当前行之前两行,终于当前行之后一行,“窗口”大小共4行,所以我们看最后一列中红色标识的1840000000是由第1行到第4行中求得的MAX值;而最后一列中蓝色标识的920000000则是由第2行到第5行中求得的MAX值。
回过来看Window子句的具体语法:
ROWS BETWEEN <start_expr> AND <end_expr>
其中<start_expr>与<end_expr> 可能是以下形式:
(1) 1, 2, ..., N PRECEDING|FOLLOWING
(2) UNBOUNDED PRECEDING|FOLLOWING
(3) CURRENT ROW
还存在一种更简单的语法:
ROWS 1, 2, ..., N PRECEDING 或ROWS UNBOUNDED PRECEDING
此时,统计“窗口”默认结束于当前行。
再来看一个综合例子:
代码
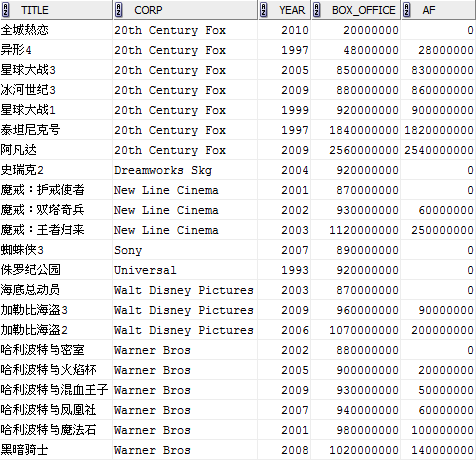
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) af1,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 2 PRECEDING AND UNBOUNDED FOLLOWING) af2,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 1 PRECEDING AND 2 PRECEDING) af3,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS 2 PRECEDING) af4,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) af5,
MAX(box_office) OVER (PARTITION BY corp ORDER BY year ROWS BETWEEN 1 FOLLOWING AND 2 FOLLOWING) af6
FROM film;
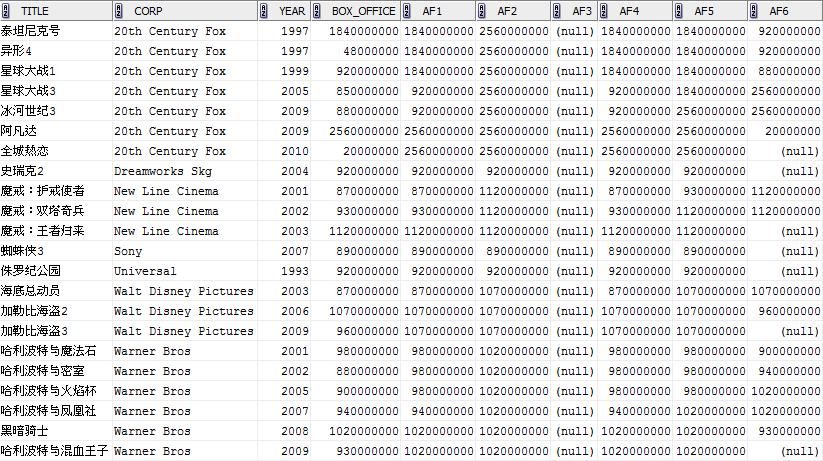
注:可以看到查询结果中的AF3这一列是NULL值,这是因为我们在指定“窗口”的时候,<start_expr>所指向的记录一定要位于<end_expr>之前,而产生AF3统计结果的“窗口”是ROWS BETWEEN 1 PRECEDING AND 2 PRECEDING,与要求不符,导致返回NULL。
除了上面用到的窗口子句——我们称之为Row Type Window,还有另外一种窗口子句,叫作Range Type Window,下面我们来看一个例子:
MAX(box_office) OVER (PARTITION BY corp ORDER BY year RANGE BETWEEN 2 PRECEDING AND 1 FOLLOWING) af
FROM film;
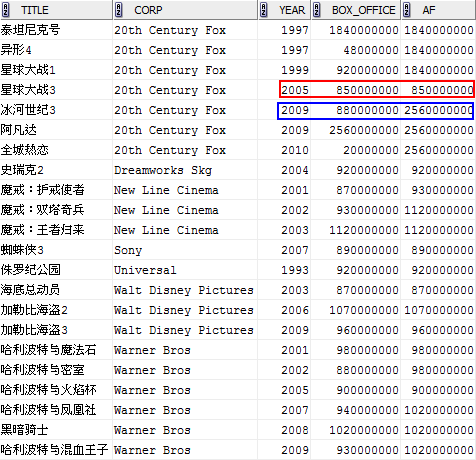
由于我们是按字段“year”进行排序的,那么上面的窗口就表示从当前行的年份往前2年,到当前行的年份往后1年,共4年的范围。
比如对于上图中红色标识的行中,该行的窗口即[2003, 2006],由于这个时间段内只有它自己,则返回对应的BOX_OFFICE;再比如蓝色标识部分,该行的窗口即[2007, 2010],返回此范围内的最大值2560000000。
--
到这里,文章写完了,文章中介绍了几个相对比较常见的分析函数,作为入门之用,其它众多的分析函数在使用上大同小异,有兴趣的同仁可以深入研究。祝阅读愉快。