论文笔记 [3] Compression Artifacts Removal Using Convolutional Neural Networks

论文用CNN做blockinig,blurring和ringing 的artifacts。JPEG压缩中,blocking是由于8×8的cell使得cell的边缘不连续,ringing,或Gibbs效应,是因为量化过程中移除了高频导致的。去高频也会导致blurring,但是相对来说blurring比较不太引起注意。然后Blocking is mostly noticeable in low-frequency regions, while the ringing artifacts are especially well noticeable around sharp edges. 文章的related work 部分介绍了用CNN做deblurring和SR的一些工作,以后可以参考。在一篇SR的论文中提出的residual learning 学习残差,得到了很好的效果。但是本文的作者人为residual learning在其他的image processing任务中的效果还是不清楚的,因为对SR来说,输入输出太strongly correlated,其他的任务可能不满足。但是在JPEG recon中作者用了这个方法。即direct mapping objective 和 residual objective 的区别。
这里作者给了一个edge emphasized objective,这个是所谓的enhancement的重点:在最后reconstruction的图像和原图上分别应用一下Sobel算子,提出边缘和细节,作为除了直接匹配的loss意外的另一个loss,其意在强调高频细节。(Our assumption is that the addition of the first derivatives should force the network to focus specifically on high frequency structures such as edges, ringing artifacts, and block artifacts and it could lead to perceptually better reconstructions.)
公式如下:
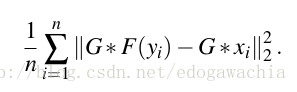
CNN结构如下:

在初始化阶段,作者认为mean=0的初始化,由于数量有限,统计意义上为无offset但是实际上均值不是0,所以要强制使其为0,We eliminate this problem by explicitly forcing individual filters to have zero mean during initialization. Such
initialization allows us to use significantly higher initial learning rates, especially together with residual learning, and it results in trained networks with significantly fewer saturated neurons. 而且,作者认为用BN层解决会在训练时候引入噪声(?)。
关于跳线,即skip connecttion,首先,这篇文章是将第一层送入后面的深层,不是对称的,而且不是吧activation加起来而是concatenate起来。
训练用的是彩色图像,通过YCbCr模型转为灰度。The images were transformed to gray-scale using the YCbCr color model by keeping the luma component – Y only. 由于主要是deringing,所以不太有色调的畸变,因此只用了灰度图。
另外,原来做deblocking的还有一个专门的考虑了block的PSNR的assessment。叫做PSNR-B。PSNR-B modifies the original PSNR by including an additional blocking effect factor (BEF)。另外,还有一个后处理滤波器( to a
simple postprocessing filter spp included in the FFmpeg framework )。
patch选取用random sample。
网络采用两种结构,一种较深的一种浅的。


文章结论是用residual learning,skip connection, symmetric weight initialization 训练8层(比之前方法深)网络。认为residual learning 比 direct mapping,edge preserving 效果好。

reference:
Svoboda, Pavel, Michal Hradis, David Barina和Pavel Zemcik. 《Compression Artifacts Removal Using Convolutional Neural Networks》. arXiv:1605.00366 [cs], 2016年5月2日. http://arxiv.org/abs/1605.00366.
2018/01/23 11:33 am
我该怎样生活?这个问题不仅是人生之初的问题,更是贯穿人一生的问题。 —— 陈嘉映