一.函数的有用信息
1.首先我们看这样一个装饰器:
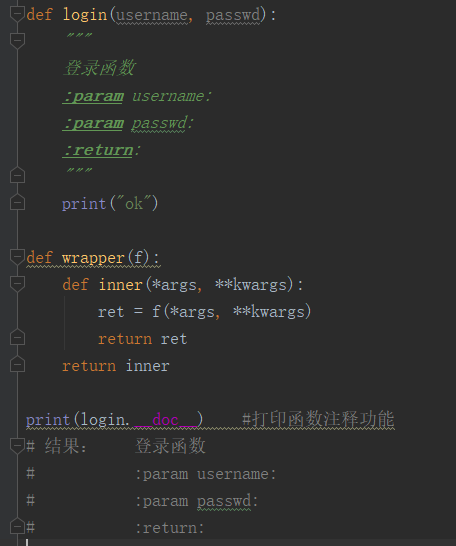
可以看到我们用login.__doc__就把函数的有用信息打印出来了,注意此时并没有用装饰器,接下来我们把装饰器加上实验:
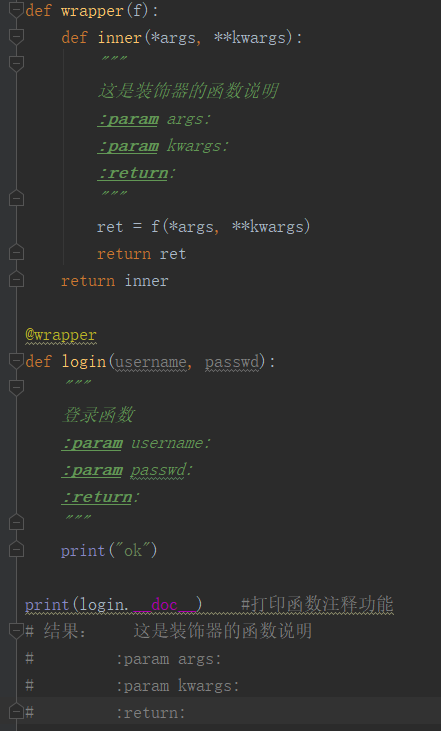
很明显,当加上装饰器的时候,原函数的函数说明就无法调用的到,只能调用到装饰器的函数说明,那如果我们想要调用到,该怎么办呢?,py的一个模块提供了一个方法:
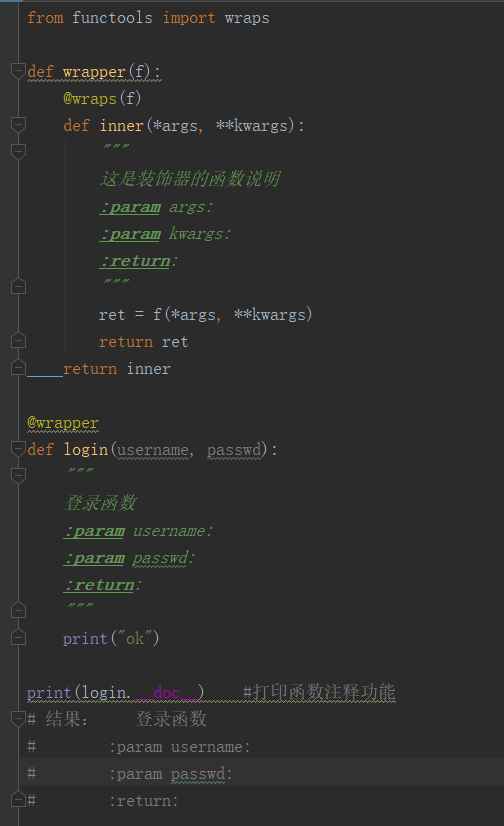
可以看到,这样就调用到了被装饰函数的函数说明啦。
二.装饰器的升级
1.带参数的装饰器,我们先看如下函数:
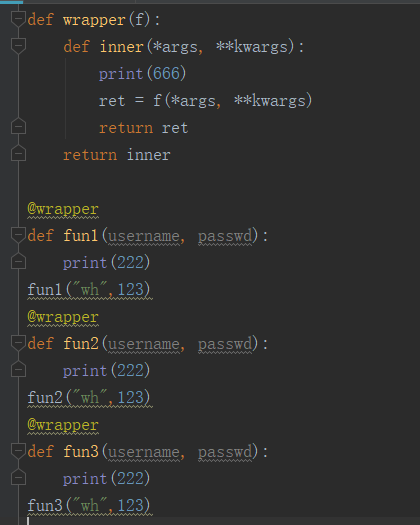

如上是三个函数,我们用了一个装饰器进行装饰,假设有这样一个场景,我们有500个函数需要装饰,ok,有的同学可能会说,那就写500遍@wrapper就行了,等你写完我又不想用他装饰了,那是不是还要在删500次呢,这样看来是不是太复杂了呢,接下来我们引入一个带参数的装饰器解决这个问题,一步轻松搞定!


此时我们的flog变量设置的是True,就是启用装饰器,接下来设为False,看下结果:


这是不是就是一步就搞定了呢,不用在来回删除增加啦,这里简单分析下:
在外层加了一个timmer(flog)的函数,装饰器函数形式为:@timmer(flog),首先将@和timmer(flog)拆分,先计算timmer(flog),执行timmer函数,将flog的值赋值给flog1,然后执行函数返回wrapper,此时在于@结合成@wrapper,这就与之前的装饰器调用形式一样了,接下来继续执行程序,判断flog1的值,为True就进行装饰,为Falase就不装饰。
2.多个装饰器装饰一个函数,首先看下面的例子:
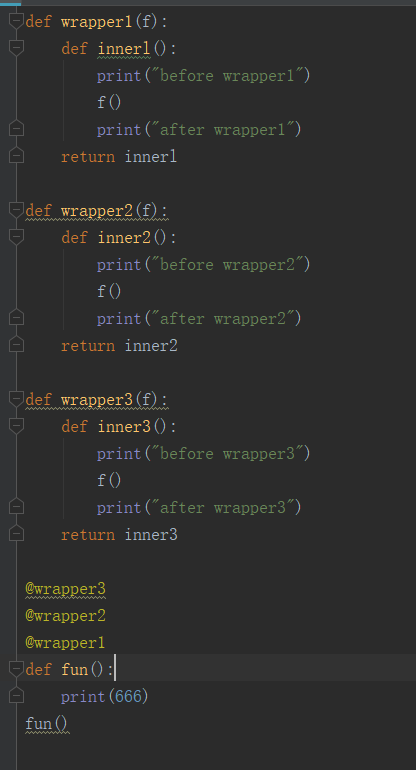
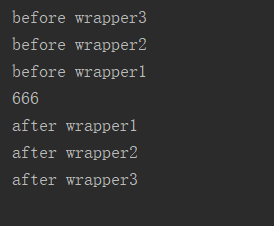
想一想为什么会打印出这样的结果呢?接下来一步步来分析:
首先我们知道函数最近的装饰器先执行,这里先执行wrapper1这个装饰器,fun = wrapper1(fun),里面的fun是函数名,外面的fun是inner1.接下来执行wrapper2这个装饰器,fun=wrapper2(fun),执行完毕,里面的fun是inner1,外面的fun是inner2,接下来在执行wrapper3这个装饰器,fun=wrapper3(fun),执行完毕,里面的fun是inner2,外面的fun是inner3.这时,所有的装饰器已经循环完毕,首先会打印inner3的装饰器:打印before wrapper3,然后是inner2(),打印before wrapper2,然后是inner1(),打印before wrapper1,接下来就是执行fun函数打印666666666,打印完毕依次返回打印after wrapper1,after wrapper2,after wrapper3,然后程序结束。
三.迭代器
1.什么是可迭代对象?类似于for循环遍历这种:
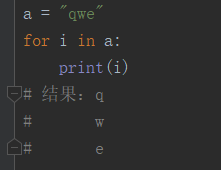
以上是字符串的循环,接下来看下整形数据的:
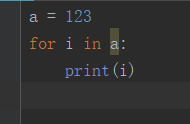
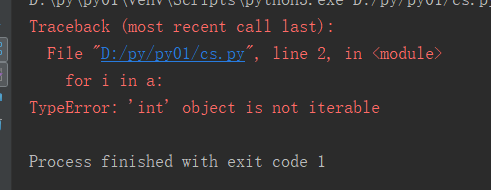
可以看到int类型是不可迭代的。
str, list tuple dict set range 文件句柄都是可迭代对象
该对象中,含有__iter__方法的就是可迭代对象,遵循可迭代协议
print(dir(str))
判断该对象是不是可迭代对象的两种方法:
(1):判断是否含有__iter__方法:

(2).利用isinstance方法进行判断:
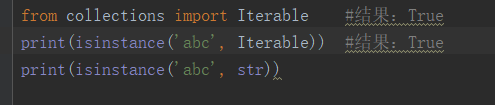
2.迭代器:
迭代器 内部含有__iter__ 且含有__next__方法的对象就是迭代器,遵循迭代器协议。
可迭代对象转换为迭代器:
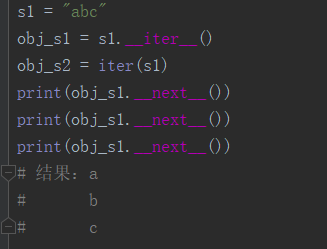
判断该对象是不是迭代器的两种方法:
(1).判断是否含有__next__方法:

(2).利用isinstance方法:
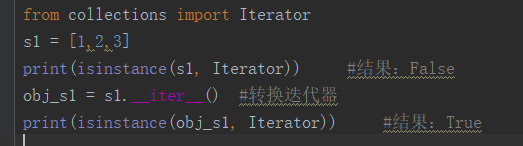
迭代器的好处:节省内存、惰性机制、单向执行,不可逆。
用while取值迭代器案例:

四.生成器:
1.生成器本质就是迭代器,他是自定义的迭代器(自己用python代码写的迭代器),生成器的关键词是yield,下面利用函数的方式构建一个生成器:
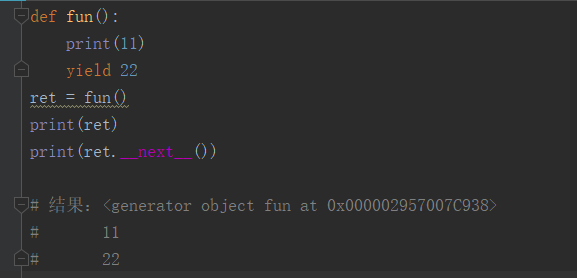
凡是函数中有yield关键词就是生成器。
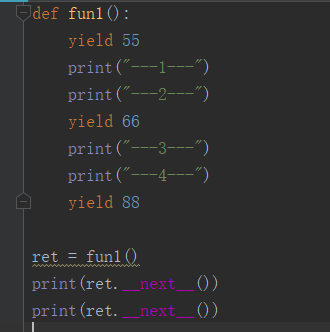
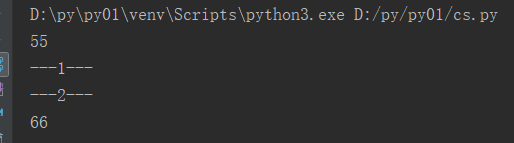
可以看出,每执行一个next就对应一个yield,也就是只执行一个yield.
案例:
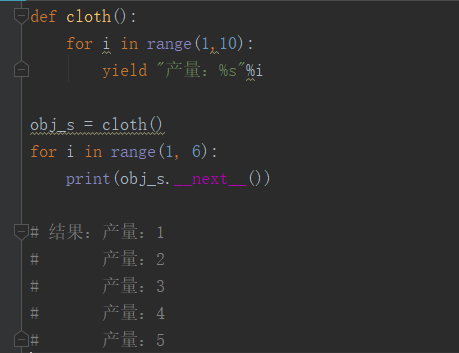
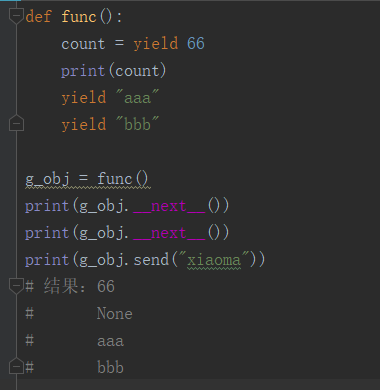
send和next都是对生成器取值,
send会给上一个yield发送一个值
send不能用在第一次取值
最后一个yield不能得到值
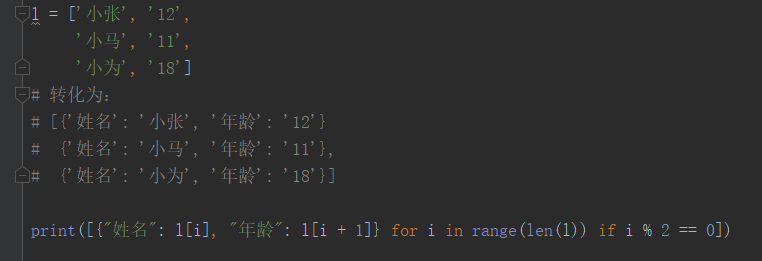
五.生成器表达式,列表推导式
1.生成器表达式的基本语法:
[变量(加工后的变量) for 变量 in iterable] 遍历模式

打印30以内能被3整除的数:
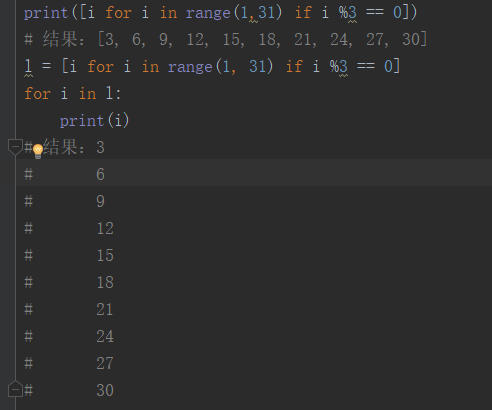
2.列表生成式:
# 列表推导式:简单,一行搞定。
# 特别复杂的数据列表推导式无法实现,只能用其他方式实现。
# 列表推导式不能排错。
# 列表推导式与生成器表达式区别
# 1 ,列推直观能看出,但是占内存
# 2,生成器表达式不易看出,但是节省内存。
案例练习:
(1).构建列表: 十以内的所有的元素的平方。

(2).20以内所有能被3整除的数的平方

(3).[3,6,9] 组成的列表M = [[1,2,3],[4,5,6],[7,8,9]]

(4).