
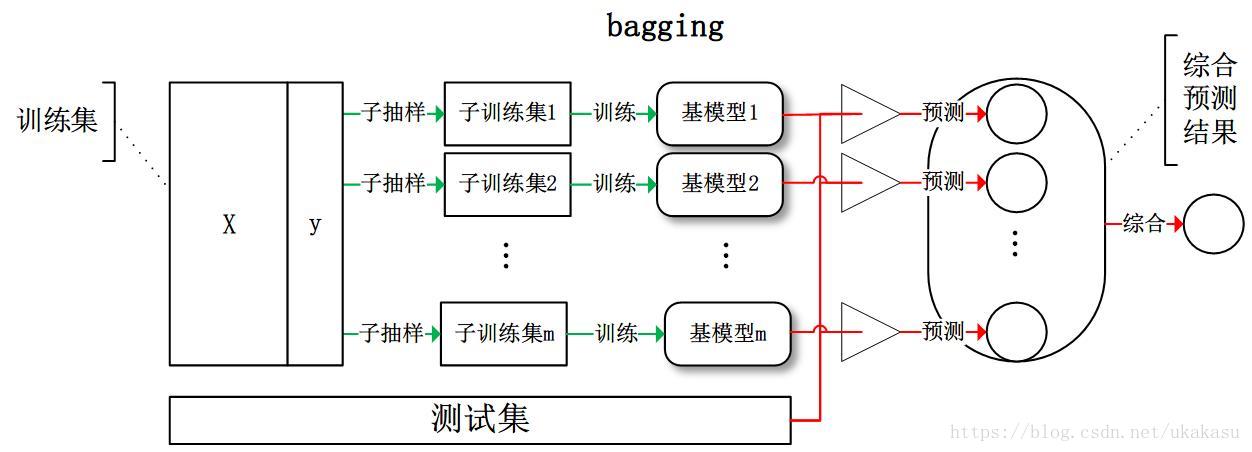
Bagging
典型的代表:随机森林。
从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果:
Boosting
典型代表:AdaBoost, Xgboost。
训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重。对所有基模型预测的结果进行线性综合产生最终的预测结果:

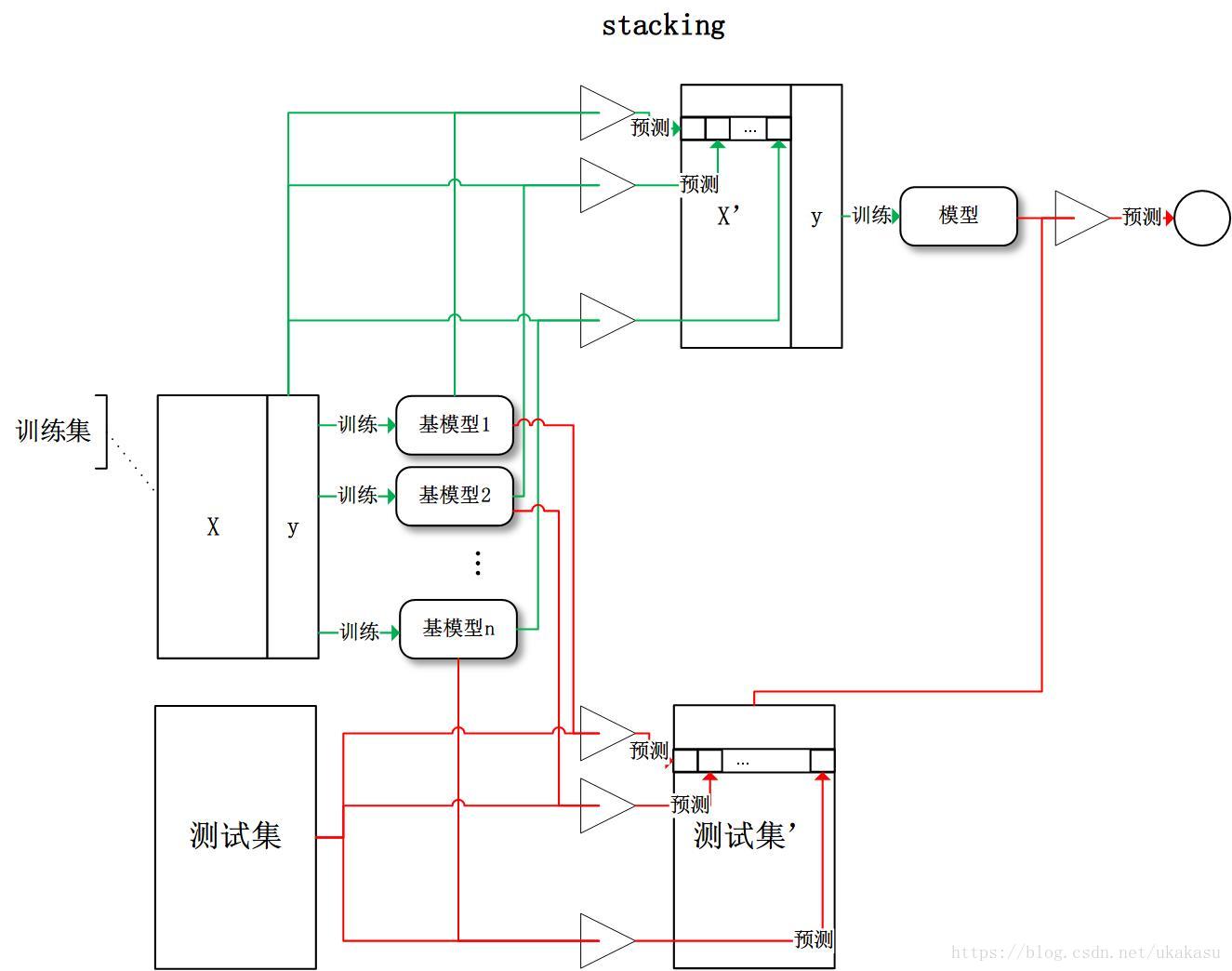
Stacking
将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
---------------------
作者:ukakasu
来源:CSDN
原文:https://blog.csdn.net/ukakasu/article/details/82781047
Boosting
典型代表:AdaBoost, Xgboost。
训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重。对所有基模型预测的结果进行线性综合产生最终的预测结果:
Stacking
将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
--------------------- 作者:ukakasu 来源:CSDN 原文:https://blog.csdn.net/ukakasu/article/details/82781047 版权声明:本文为博主原创文章,转载请附上博文链接!