7-1 The Closest Fibonacci Number (20 分)
The Fibonacci sequence Fn is defined by
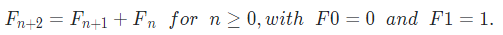
The closest Fibonacci number is defined as the Fibonacci number with the smallest absolute difference with the given integer N.
Your job is to find the closest Fibonacci number for any given N.
Input Specification:
Each input file contains one test case, which gives a positive integer N (≤10^8).
Output Specification:
For each case, print the closest Fibonacci number. If the solution is not unique, output the smallest one.
Sample Input:
305
Sample Output:
233
Hint:
Since part of the sequence is { 0, 1, 1, 2, 3, 5, 8, 12, 21, 34, 55, 89, 144, 233, 377, 610, ... }, there are two solutions: 233 and 377, both have the smallest distance 72 to 305. The smaller one must be printed out.
题目大意
给定一个N,要求输出斐波拉契数列中最接近N的数字。
算法思路
需要不断生成斐波拉契数列的每一项,遇到第一次大于等于N的数字就停止,然后记录当前位置为k,判断k-1和k位置的那个数字和N更接近就输出哪个。生成斐波那契数列的方法就是采用递归加上记忆化搜索(使用dp数组作为一个缓存,遇到算过的值就直接返回,否则就递归计算,然后保存)
递归解法
点击查看代码
#include<cstdio>
#include<algorithm>
#include<cstring>
using namespace std;
int dp[1000000];
int F(int n) {
if (n == 0 || n == 1) {
dp[n] = n;
return n;
}
if(dp[n]!=-1){
return dp[n];
}else{
dp[n] = F(n - 1) + F(n - 2);
}
return dp[n];
}
int main() {
int N;
scanf("%d", &N);
memset(dp, -1, sizeof(dp));
dp[0] = dp[1] = 1;
int k;
for (int i = 0;; ++i) {
if (dp[i] == -1) {
dp[i] = F(i);
}
if (dp[i] >= N) {
k = i;
break;
}
}
int a = abs(dp[k] - N);
int b = abs(dp[k - 1] - N);
if (a < b) {
printf("%d", dp[k]);
} else {
printf("%d", dp[k - 1]);
}
return 0;
}
非递归解法(超简洁)!!
#include<vector>
using namespace std;
int n;
int main(){
scanf("%d", &n);
int x = 0, y = 1, z = 1;
while(true){
z = x+y;
if(z>=n) break;
x = y; y = z;
}
int a = n-y, b = z-n;
if(a<=b) printf("%d\n", y);
else printf("%d\n", z);
}
注意点
1、直接暴力递归会导致测试点5运行超时
7-2 Subsequence in Substring (25 分)
A substring is a continuous part of a string. A subsequence is the part of a string that might be continuous or not but the order of the elements is maintained. For example, given the string atpaaabpabtt, pabt is a substring, while pat is a subsequence.
Now given a string S and a subsequence P, you are supposed to find the shortest substring of S that contains P. If such a solution is not unique, output the left most one.
Input Specification:
Each input file contains one test case which consists of two lines. The first line contains S and the second line P. S is non-empty and consists of no more than 10^4 lower English letters. P is guaranteed to be a non-empty subsequence of S.
Output Specification:
For each case, print the shortest substring of S that contains P. If such a solution is not unique, output the left most one.
Sample Input:
atpaaabpabttpcat
pat
Sample Output:
pabt
题目大意
给定两个字符串S和P,输出包含P的最短S子串,如果有多个,那么就输出最左边的那个.
算法思路
使用双指针进行暴力搜索,我们使用指针i搜索字符串S不回退,指针j搜索字符串P会回退,同时使用end标记当前字符串S与P[j]待比较的位置,初始为i+1,如果s[end] == p[j],那么就++end,++j。否则就++end。如果最后j来到P的结尾位置,说明当前S的子串 [ i,end) 包含字符串P,使用minLen记录其最短长度,同时如果在遍历的时候发现当前[i,end)的长度end-i已经大于minLen了,就说明就算后面有解也不是最优解,直接退出即可。
参考
双指针法
#include<cstdio>
#include<vector>
#include<iostream>
#include<algorithm>
using namespace std;
int main() {
string s, p;
cin >> s >> p;
int n = s.size();
int m = p.size();
int minLen = 0x3fffffff;
string ans;
for (int i = 0; i < n; ++i) {
// 起始位不同一定不行
if (s[i] != p[0]) {
continue;
}
int j = 1;
int end = i + 1;
// 判断[i,end)的子串是否有子序列b
while (j < m && end < n) {
if (s[end] == p[j]) {
++end;
++j;
} else {
++end;
}
// 当前子串的长度已经长于已保存的记录,就不需要继续判断了
if (end - i >= minLen) {
break;
}
}
// [i,end)的子串含有子序列b
if (j == m) {
int len = end - i;
if (len < minLen) {
ans = s.substr(i, len);
minLen = len;
}
}
}
cout << ans;
return 0;
}
模拟法
#include<iostream>
#include<vector>
using namespace std;
string s, p;
int main(){
cin >> s >> p;
int n = s.size(); int m = p.size();
int r = 0; int t = 0;
int K = 1e9; string ans;
while(r < n){
if(s[r]==p[t]) t++;
if(t==m) {
int pos = m-1;
int l;
for(l = r; l >=0; l--){
if(s[l]==p[pos]) pos--;
if(pos==-1) break;
}
int len = (r-l+1);
if(len < K) {K = len; ans = s.substr(l, len);}
t = 0; r = l+1; continue;
}
r++;
}
cout << ans << endl;
}
7-3 File Path (25 分)
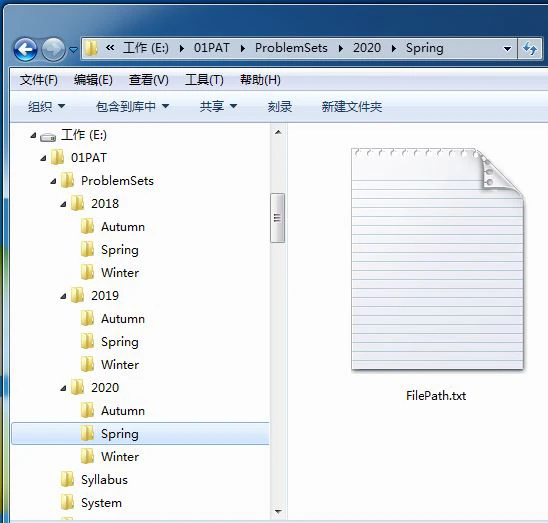
The figure shows the tree view of directories in Windows File Explorer. When a file is selected, there is a file path shown in the above navigation bar. Now given a tree view of directories, your job is to print the file path for any selected file.
Input Specification:
Each input file contains one test case. For each case, the first line gives a positive integer N (≤10^3), which is the total number of directories and files. Then N lines follow, each gives the unique 4-digit ID of a file or a directory, starting from the unique root ID 0000. The format is that the files of depth d will have their IDs indented by d spaces. It is guaranteed that there is no conflict in this tree structure.
Then a positive integer K (≤100) is given, followed by K queries of IDs.
Output Specification:
For each queried ID, print in a line the corresponding path from the root to the file in the format: 0000->ID1->ID2->...->ID. If the ID is not in the tree, print Error: ID is not found. instead.
Sample Input:
14
0000
1234
2234
3234
4234
4235
2333
5234
6234
7234
9999
0001
8234
0002
4 9999 8234 0002 6666
Sample Output:
0000->1234->2234->6234->7234->9999
0000->1234->0001->8234
0000->0002
Error: 6666 is not found.
题目大意
给定N个数字,每一个数字代表了文件或者文件夹,并且采用缩进的方式表示每一个文件或者文件夹之间的相对深度,缩进d格代表在d层。然后给定K个查询,要求输出从根节点到查询节点的路径,如果查询节点不存在输出Error: ID is not found.
算法思路
此题可以分为两步来进行,第一步建树,第二步深度优先搜索。难点就是建树,由于我们需要输出从根节点到查询节点的路径,并且字符串的长度就代表了节点的深度,那么我们直接使用一个二维数组,第一维代表了层数,第二维代表了在当前层数的所有节点,同时使用pre数组记录每一个节点的前驱节点。
建树过程:
我们使用字符串的长度size来代表节点的层数,那么每一次添加一个节点d,就记录当前节点的前驱节点,如果是第一个节点说明是根节点root,前驱为-1,否则前驱就是上一层中的最后一个节点 level [size - 1] [level [size - 1].size() - 1];
建树完毕后,对于每一个合法查询直接调用DFS进行深度搜索,从指定节点向前搜索,来到root后开始输出即可。
题解
!!!每一个节点的前缀就是上一层节点的最后一个节点
这一点应该是最难想到的,甚至我在看答案的时候还debug了半天。
他的上一级的size应该是动态变化的,而不是我刚开始认为的都统计完之后的固定值。而是在输入的时候的上一级,也就是说,当前size=5->size=6->size=5,后面的size会覆盖前面的。
#include<cstdio>
#include<iostream>
#include<string>
#include<unordered_map>
#include<algorithm>
#include<vector>
using namespace std;
int pre[10004];// 记录每一个节点的前驱节点
unordered_map<int, bool> isExist;// 标记节点是否存在
vector<int> level[1005];// 每一层次的结点,按照顺序
int root;// 根节点
void DFS(int end) {
if (root == end) {
printf("%04d", end);
return;
}
DFS(pre[end]);
printf("->%04d", end);
}
int main() {
int N;
scanf("%d", &N);
string current;
// 吸收回车
getchar();
for (int i = 0; i < N; ++i) {
getline(cin, current);
int d = stoi(current);
// 标记当前节点合法
isExist[d] = true;
// 使用字符串的长度代表层数,越小的层数越低
int size = current.size();
// 为当前层节点添加d
level[size].push_back(d);
// 记录每一个节点的前缀和根节点root
if (i == 0) {
pre[d] = -1;
root = d;
} else {
// 每一个节点的前缀就是上一层节点的最后一个节点
pre[d] = level[size - 1][level[size - 1].size() - 1];
}
}
int K;
scanf("%d", &K);
for (int i = 0; i < K; ++i) {
int a;
scanf("%d", &a);
if (!isExist[a]) {
printf("Error: %04d is not found.\n", a);
} else {
DFS(a);
printf("\n");
}
}
return 0;
}
7-4 Chemical Equation (30 分)
A chemical equation is the symbolic representation of a chemical reaction in the form of symbols and formulae, wherein the reactant entities are given on the left-hand side and the product entities on the right-hand side. For example,
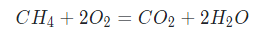
means that the reactants in this chemical reaction are methane and oxygen: CH4 and O2, and the products of this reaction are carbon dioxide and water: CO2 and H2O.
Given a set of reactants and products, you are supposed to tell that in which way we can obtain these products, provided that each reactant can be used only once. For the sake of simplicity, we will consider all the entities on the right-hand side of the equation as one single product.
Input Specification:
Each input file contains one test case. For each case, the first line gives an integer N (2≤N≤20), followed by N distinct indices of reactants. The second line gives an integer M (1≤M≤10), followed by M distinct indices of products. The index of an entity is a 2-digit number.
Then a positive integer K (≤50) is given, followed by K lines of equations, in the format:
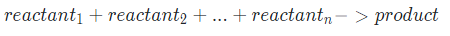
where all the reactants are distinct and are in increasing order of their indices.
Note: It is guaranteed that
- one set of reactants will not produce two or more different products, i.e. situation like 01 + 02 -> 03 and 01 + 02 -> 04 is impossible;
- a reactant cannot be its product unless it is the only one on the left-hand side, i.e. 01 -> 01 is always true (no matter the equation is given or not), but 01 + 02 -> 01 is impossible; and
- there are never more than 5 different ways of obtaining a product given in the equations list.
Output Specification:
For each case, print the equations that use the given reactants to obtain all the given products. Note that each reactant can be used only once.
Each equation occupies a line, in the same format as we see in the inputs. The equations must be print in the same order as the products given in the input. For each product in order, if the solution is not unique, always print the one with the smallest sequence of reactants -- A sequence
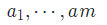
is said to be smaller than another sequence
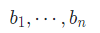
It is guaranteed that at least one solution exists.
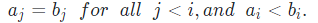
Sample Input:
8 09 05 03 04 02 01 16 10
3 08 03 04
6
03 + 09 -> 08
02 + 08 -> 04
02 + 04 -> 03
01 + 05 -> 03
01 + 09 + 16 -> 03
02 + 03 + 05 -> 08
Sample Output:
02 + 03 + 05 -> 08
01 + 09 + 16 -> 03
04 -> 04
题目大意
给定n个反应物,m个生成物和k个化学反应方程式。要求根据反应物和化学方程式输出可以获得生成物的化学方程式,生成规则如下:
1、一组反应物只会生成一种product
2、除了 pro->pro 的情况,一个化学方程式是不可能出现反应物中存在生成物的情况
3、对于有多个生成的化学式输出字典序最小的那个。
4、每一种反应物只能使用一次
算法思路
此题好像只能使用深度优先遍历来处理,原因在于需要将所有的生成物进行生成,并且题目保证一定存在一个解。那么使用贪心算法取每一次获得当前生成物字典序最小的有可能会导致后面的生成物无法生成的情况。为了方便进行搜索我们使用结构体Equation来封装我们需要的数据,这里将算法的过程分为预处理和DFS。
数据结构:
struct Equation {
string equation;
vector<int> reacts;
int prod{};
friend bool operator<(const Equation &a, const Equation &b) {
return a.equation < b.equation;
}
};
unordered_map<int, bool> reactants;// 标记当前反应物是否可以使用
unordered_map<int, set<Equation>> products;// 根据product建立到所有生成该生成物的Equation集合
vector<int> pro;// 所有需要生成的生成物编号
vector<string> ans;// 所有的结果集合
数据的预处理
首先在输入所有反应物的时候标记reactants[index] = true,在输入生成物的时候需要建立product->product这样的方程式添加到products集合中,并同时标记当前成物为反应物。最后在输入每一行的化学方程式的时候使用process函数进行处理,将其封装为一个Equation,并添加到products集合中。
DFS
我们使用输入的生成物数组pro的下标来代表当前搜索的位置,起始为0,终止位置为m-1,DFS(proCur,proEnd)的含义为数组[proCur,proEnd-1]的生成物是否可以被生成,如果可以返回true,否则返回false。那么原问题的解就是DFS(0,m)。那么递归边界和递归体分别为:
- 递归边界:
当我们当前遍历的下标为m的时候说明遍历完毕,获得了一组解,直接返回true。 - 递归体:
首先遍历当前生成物pro[proCur]的所有化学方程式,判断当前的方程是是否可以使用,如果可以,先标记当前化学方程式的生成物全部已经使用,并将方程式添加到ans数组中,然后进行下一层递归,判断proCur + 1以及后续的生成物是否可以被生成,如果为true,说明从proCur位置到数组末尾的所有生成物都可以被生成,返回true。否则说明后续生成物生成失败,需要回溯,先将所有的反应物标记为未使用,然后ans弹出之前添加的方程式。
注意点
1、这里使用DFS主要是因为需要生成所有的生成物,一个都不能落下,所以贪心算法不可用,测试点1和5考察该点。
2、每一个查询的生成物都可以生成 product->product的化学方程式,需要人为添加该式子到集合中。
题解
对于DFS的理解掌握还是不足,对于复杂题目的处理欠练习Orz
#include<cstdio>
#include<vector>
#include<iostream>
#include<unordered_map>
#include <set>
#include <string>
using namespace std;
struct Equation {
string equation;
vector<int> reacts;
int prod{};
friend bool operator<(const Equation &a, const Equation &b) {
return a.equation < b.equation;
}
};
unordered_map<int, bool> reactants;// 标记当前反应物是否可以使用
unordered_map<int, set<Equation>> products;// 根据product建立到所有生成该生成物的Equation集合
vector<int> pro;// 所有需要生成的生成物编号
vector<string> ans;// 所有的结果集合
// 将s封装为一个Equation
void process(const string &s) {
int n = s.size();
if (n == 0) {
return;
}
Equation e;
// 最后两位为生成物编号
e.prod = stoi(s.substr(n - 2));
// 分解字符串获取反应物
string temp;
for (int i = 0; i < n; ++i) {
if (s[i] >= '0' && s[i] <= '9') {
temp.push_back(s[i]);
} else if (s[i] == ' ' && !temp.empty()) {
int v = stoi(temp);
e.reacts.push_back(v);
temp.clear();
} else if (s[i] == '-') {
break;
}
}
e.equation = s;
products[e.prod].insert(e);
}
// 判断当前的生成物pro[proCur]是否可以被生成,如果不可以就得回溯
bool DFS(int proCur, int proEnd) {
if (proCur == proEnd) {
// 此时已经将所有的生成物生成完毕
return true;
}
// 生成物编号
int proNo = pro[proCur];
// 遍历当前生成物proNo的所有化学方程式
for (const auto &allEquations:products[proNo]) {
// 判断当前的方程是是否可以使用(所有的反应物是否都没有被使用过)
bool isvalid = true;
for (int react:allEquations.reacts) {
if (!reactants[react]) {
// 当前反应物被使用过
isvalid = false;
break;
}
}
if (!isvalid) {
continue;
}
// 存在一种解
ans.push_back(allEquations.equation);
// 然后将所有的反应物都进行标记使用过
for (int react:allEquations.reacts) {
reactants[react] = false;
}
// 递归查询后续的生成物是否可以生成
if (DFS(proCur + 1, proEnd)) {
// 可以生成说明找到了一组解,直接返回即可
return true;
}
// 当前选择的化学方程式使得后续的生成物无法生成,需要回溯
for (int react:allEquations.reacts) {
reactants[react] = true;
}
ans.pop_back();
}
// 遍历了所有的化学生成式都没有办法获得当前生成物
return false;
}
int main() {
// n为反应物数量,m为生成物数量
int n, m;
scanf("%d", &n);
int index;
for (int i = 0; i < n; ++i) {
scanf("%d", &index);
// 标记所有给出的反应式
reactants[index] = true;
}
scanf("%d", &m);
for (int i = 0; i < m; ++i) {
string s;
cin >> s;
pro.push_back(stoi(s));
// 每一个反应物都存在一个 pro->pro 的化学方程式
Equation e;
e.equation.append(s);
e.equation.append(" -> ");
e.equation.append(s);
e.prod = pro[i];
e.reacts.push_back(pro[i]);
// 标记当前的生成物同时为反应物
reactants[pro[i]] = true;
// 将当前的pro->pro的化学方程式添加到products集合中
products[pro[i]].insert(e);
}
int k;
scanf("%d", &k);
// 吸收回车
getchar();
string s;
for (int i = 0; i < k; ++i) {
getline(cin, s);
// 处理每一个化学方程式,封装为Equation
process(s);
}
// 深度搜索,保证获得所有的生成物
DFS(0, m);
// 输出结果集合
for (const auto &v:ans) {
cout << v << endl;
}
return 0;
}