===安装===
a>.官网:www.python.org
b>.linux系统自带,ubuntu,CentOS,redhat
注:Python3.0比python2.6早,python3.x和pthon2.5不兼容,python2.6之后有个工具python2to3可转换到python3.x。建议使用2.75及以上版本
===查版本==
直接打python
===打印===
print 'hello,world'
===python解释器===
-CPython 官方标准--动态解释语言(边执行边编译)
-IPython--ipython是一个Pythond额交互式shell,比默认的python shell好用的多,支持变量自动补全,自动缩进,支持bash shell命令,内置了许多很有用的功能和函数。在ubuntu下只要sudo apt-get install ipython就装好了。
-Jython--Jython是一种完整的语言,它是一个python语言在Java中的完全实现(即用Java重新把python写了一遍)。Jython也有很多从Cpython中继承的模块库。Jython不仅提供了python的库,同时也提供了所有的Java类,所以它有一个巨大的资源库。
-pypy--python写的解释器。号称速度比Cpython快6倍。
--IronPython--.net version
===语法要求===
-缩进统一
-变量
标识符的第一个字符必须是字母(a-z,A-Z)或下划线(_),其他部分可以是字母、下划线或数字(0-9)
标识符对大小写敏感
-常量--习惯用全部大写的变量名表示
===数据类型===
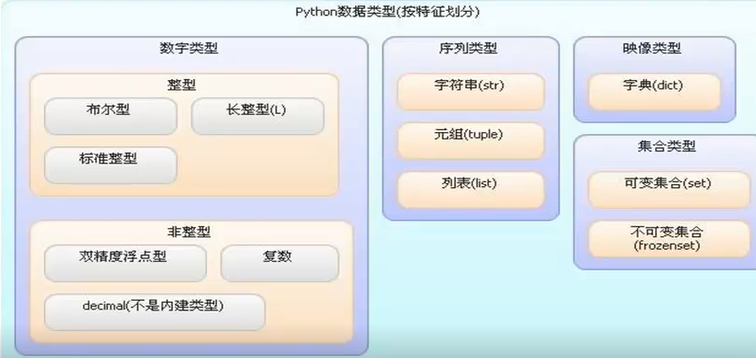
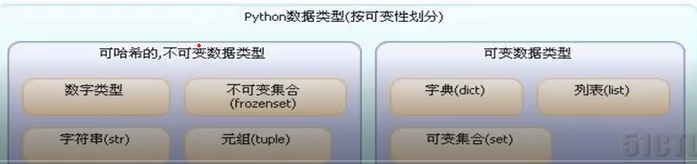
基础详细教程参考:
www.w3cschool.cc/python
===注释===
-单行注释--行前加‘#’
-多行注释--前后三个单引号,同时它是一个格式化打印。前后三个双引号,和单引号效果一样
’‘’ssssss sss' sssss 'sssss'''---->注释
log=‘’‘sssss
ssss aaa '
sssss''''---->print log,则按照以上格式打印
===字符编码:ASSIC、Unicode、UTF-8编码===
浏览网页的时候,服务器会把动态生成的Unicode内容转换成UTF-8再传输到浏览器
-ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
-Unicode(统一码、万国码、单一码)
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。ASCII编码一个字节能表示的最大的整数就是255(二进制11111111=十进制255)。如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
-UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
python首行加: #_*_coding:utf-8_*_ ,处理中文字符编码
unicode_var.encode()---->变成utf-8
utf8_var.decode()---->变成Unicode
读到硬盘是utf-8,到内存中的时候都是Unicode
===导入模块===
import moduleName
from module import sayHi
import moduleName as newName
例如:
import os #和系统交互
os.system('pwd')
a = os.popen('pwd').read()
import commands
rst = commands.getstatusoutput('pwd') #同时存状态和打印结果
import sys
sys.argv #取python执行时的传参
sys.argv[2]
===用户交互===
raw_input() #不论输入什么,都把它作字符串处理
input()#按原生格式处理
===流程控制===
if...else...
for
while
break---->跳出循环
continue--->跳出当次