Memcached是一套高性能的、分布式内存对象缓存系统。它由C写成,以Key/Value的方式将数据储存在内存中。
一、Memcached特性
Memcached作为高速运行的分布式缓存服务器,具有以下特点:
1、协议简单
Memcached的服务器客户端通信使用简单的文本协议,而不是笨重复杂的XML等格式。因此,通过telnet 也能在memcached上保存数据、取得数据;
2、基于libevent的事件处理
Libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能 封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。 memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能;
3、内置内存存储方式
Memcached中保存的数据都存储在Memcached内置的内存存储空间中。 由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。 另外,内容容量达到指定值(启动时可以通过-m参数配置)之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存,不用担心,这个功能是可以配置的:Memcached启动时通过"-M"参数可以禁止LRU。不过,Memcached本身是为缓存而设计的,建议开启LRU.另外,Memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题;
4、Memcached不互相通信的分布式
Memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能,各个Memcached不会互相通信以共享信息。Memcached的分布式是完全由客户端程序库实现的,这种分布式是Memcached的最大特点。通过这种方式,Memcached Server之间的数据不需要同步,也就不需要互相通信了。
二、Memcached的适用场景
适用memcached的业务场景:
1)如果网站包含了访问量很大的动态网页,因而数据库的负载将会很高。由于大部分数据库请求都是读操作,那么memcached可以显著地减小数据库负载。
2)如果数据库服务器的负载比较低但CPU使用率很高,这时可以缓存计算好的结果( computed objects )和渲染后的网页模板(enderred templates)。
3)利用memcached可以缓存session数据 、临时数据以减少对他们的数据库写操作。
4)缓存一些很小但是被频繁访问的文件,图片这种大点儿的文件就由CDN(内容分发网络)来处理了;
不适用memcached的业务场景:
1)缓存对象的大小大于1MB,Memcached本身就不是为了处理庞大的多媒体(large media)和巨大的二进制块(streaming huge blobs)而设计的;
2)key的长度大于250字符;
3)虚拟主机不让运行memcached服务。 如果应用本身托管在低端的虚拟私有服务器上,像vmware, xen这类虚拟化技术并不适合运行memcached。Memcached需要接管和控制大块的内存,如果memcached管理的内存被OS或 hypervisor交换出去,memcached的性能将大打折扣。
4)应用运行在不安全的环境中。Memcached为提供任何安全策略,仅仅通过telnet就可以访问到memcached。如果应用运行在共享的系统上,需要着重考虑安全问题。
5)业务本身需要的是持久化数据或者说需要的应该是database。
三、Memcached的内存管理
Memcached有一个很有特色的内存管理方式,为了提高效率,它使用预申请和分组的方式管理内存空间,而并不是每次需要写入数据的时候去malloc,删除数据的时候free一个指针。Memcached使用slab->chunk的组织方式管理内存。
注:1.1和1.2的slabs.c中的slab空间划分算法有一些不同
Slab可以理解为一个内存块,一个slab是memcached一次申请内存的最小单位,在memcached中,一个slab的大小默认为1048576字节(1MB),所以memcached都是整MB的使用内存。每一个slab被划分为若干个chunk,每个chunk里保存一个item,每个item同时包含了item结构体、key和value(注意在memcached中的value是只有字符串的)。slab按照自己的id分别组成链表,这些链表又按id挂在一个slabclass数组上,整个结构看起来有点像二维数组。slabclass的长度在1.1中是21,在1.2中是200。
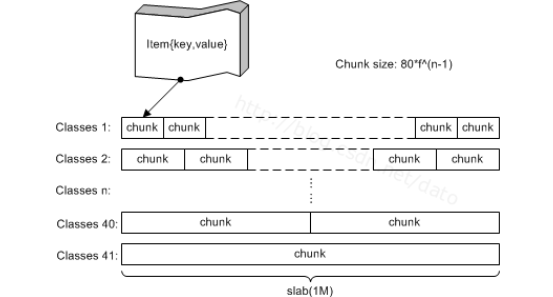
使用slabs来管理内存,内存被分成大小不等的slabs chunks(先分成大小相等的slabs,然后每个slab被分成大小相等的chunks,不同slab的chunk大小是不相等的)。chunk的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。
如果最小值为400B,最大值为1MB,因子是1.20,各个slab的chunk的大小依次是:slab1-400B slab2-480B slab3-576B.....
slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分配内存,因此如果设置了较小的因子和较大的最大值,会需要更多的内存。
关于Memcached的介绍可以参考:http://www.cnblogs.com/sunniest/p/4437806.html
http://www.cnblogs.com/rollenholt/p/3381429.html
四、Memcached的内存算法
在开始之前,有必要先了解几个基本概念:
1、slab class:在memcached中,对元素的管理是以slab为单元进行管理的。每个slab class对应一个或多个空间大小相同的chunk,如下图所示:

图一 slab class逻辑结构图
2、chunk:存放元素的最小单元。用户数据item(key、value等)最终会保存在chunk中。memcached会根据元素大小将其放到合适的slab class中。每一个slab class中的chunk空间大小是一样的,所以元素存放进来后,chunk可能会有部分空间剩余。参考下图二、下图三。

图二 元素存入memcached会寻找最合适的slab class
3、page:大小固定为1MB。当slab class空间不足时,就会申请page,并将page按chunk的大小进行切割。

图三 元素放入chunk时可能会有空间浪费
启动memcached时,以-m指定大小的内存将会用于数据的存放。默认情况下,这些内存会被分隔成1M的page。每个page在必要时分配给slab class,然后根据slab class里chunk的大小,将page分隔成chunk。一旦一个page被赋给一个slab class后,它将不会再被移动。因为内存空间有限,如果在slab class 3中使用了较多的page,那么在slab class 4中就只能使用较少的page。可以这么认为,memcached是一个有很多更小的相互独立的缓存系统,每一个更小的缓存系统实际上就是slab class。每个slab class都有它自己的统计信息以及自己的LRU。
在启动memcached时,指定-vv参数,可以在启动日志中查看每个slab class的chunk大小。
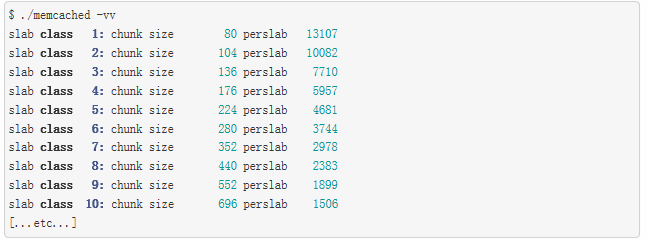
在slab class 1中,每个chunk大小为80字节,每个页面包含13107个chunk(或item)。这两个数相乘,应该最近接1个page的大小(默认是1MB)。
当存储元素时,它们将被放到最合适的slab class中。例如,50字节的元素(包含key、value等信息)将被存放到slab class 1中的chunk,根据之前的说明,此chunk中将会有30字节的空间浪费。如果存放数据总共有90字节,将被存放到slab class 2中,此时会有14字节的空间浪费。
启动时,通过设置参数-f,可以设置每个slab class下chunk的空间增长率。
另外,memcached因为一些其他功能也会使用内存空间。例如:用来查找元素的hash table;连接时也会使用一些缓存。当然,这些功能只会占用很少一部分内存空间。
内存什么时候被回收
与redis不同的是,memcached不会主动回收内存。
如果获取了一个已失效的元素,memcached将会释放内存。后续再将新的元素存放进来时,将会重用此内存(前提是新元素也是要存放在同一slab class中)。由于LRU,元素将被踢出以让给新的元素,或发现有过期的元素,它们的内存将被重用。
五、Memcached的缓存策略
Memcached的缓存策略是LRU+到期失效策略。当你在Memcached内存存储数据项时,你有可能会指定它的缓存的失效时间,默认为永久。当Memcached服务器用完分配的内存时,失效的数据被首先替换,然后也是最近未使用的数据。在LRU中,Memcached使用的是一种Lazy Expiration策略,自己不会监控存入的key/value对是否过期,而是在获取key值时查看记录的时间戳,检查key/value对空间是否过期,这样可减轻服务器的负载。mcached
六、Memcached的分布式算法
当向Memcached集群存入/取出key/value时,memcached客户端程序根据一定的算法计算存入哪台服务器,然后再把key/value值存到此服务器中,也就是说,存取数据分二步走,第一步:选择服务器;第二步:存取数据.
假设memcached服务器有node1~node3三台, 应用程序要保存键名为"tokyo","kanagawa","chiba","saitama","gunma" 的数据.
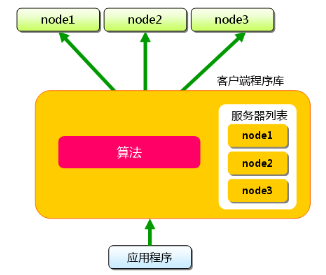
图1 分布式简介:准备
首先向memcached中添加"tokyo"。将"tokyo"传给客户端程序库后, 客户端实现的算法就会根据"键"来决定保存数据的memcached服务器。服务器选定后,即命令它保存"tokyo"及其值。
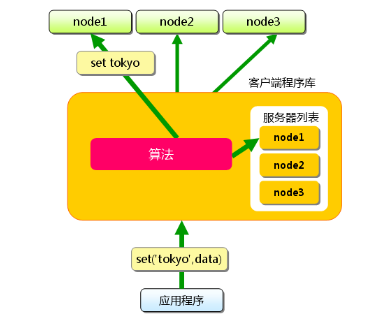
同样,"kanagawa","chiba","saitama","gunma"都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库.函数库通过与数据保存时相同的算法,根据"键"选择服务器.使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令.只要数据没有因为某些原因被删除,就能获得保存的值。
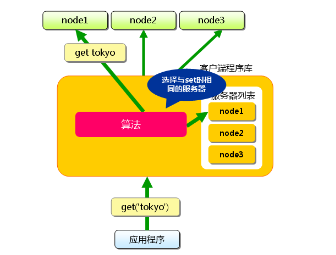
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
缓存系统中应用比较多的是余数计算分散和一致性 HASH 计算分散。
余数计算法:余数计算分散法简单来说,就是 "根据服务器台数的余数进行分散 " 。
1、求得传入键的整数哈希值( int hashCode );
2、使用计算出的 hashCode 除以服务器台数 (N) 取余数( C=hashCode % N );
3、在 N 台服务器中选择序号为 C 的服务器
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。 那就是当添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。
散列算法:在一个大的数据范围内的构建一个虚拟的环,首( 0 )尾(Integer.MAXVALUE )相接的圆环,然后通过某种 HASH算法增加虚拟节点的方式( 1 个实体节点可以虚拟 N个虚拟阶段,如 160 , 200 , 1000 等)让节点更为均匀的分别在环上。 KEY 请求的时候,也通过相同的某种HASH 算法 计算出 HASH 值,然后在在到环上定位同向最接近的虚拟节点,最后通过虚拟节点与实体节点的对应关系找到服务的实体节点。
散列算法请参见:http://blog.csdn.net/sparkliang/article/details/5279393