json & pickle 模块
用于序列化的两个模块(所谓序列化,就是把变量从内存中变成可存储或可传输的过程。序列化之后便可以存储在硬盘上,并可以传输至别的机器上,再通过反序列化,便可以获得之前的变量内容)
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换,该模块也是python特有的模块,可以保存当前状态,俗称挂起。
Json模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...还可以把一个程序,一个类给序列化掉)
json模块
首先,我们声明一个字典s,通过dumps方法将s进行序列化,此时可以将序列化的结果写到文本中(都是字符串的格式),即为存档。
之后,通过loads方法对序列化后的结果进行反序列化,得到之前的变量信息s,即为读档。
1 import json 2 s = {"desc":"invilad-citykey", "status":1002} 3 4 result = json.dumps(s) # 序列化 5 result1 = json.loads(result) #反序列化 6 7 print(result, type(result)) 8 print(result1, type(result1))
执行上述代码,如下图所示,第一行是序列化的结果,可以看出,json将字典转换成一个类型为字符串格式的序列化结果;第二行是反序列化的结果,其将之前序列化的结果又转化成为字典s。

同样,对于列表,也可以通过同样的方式进行序列化和反序列化。
1 Company = ['ALi','tencent','BAIDU'] 2 result2 = json.dumps(Company) 3 result3 = json.loads(result2) 4 print(result2, type(result2)) 5 print(result3, type(result3))
执行上述代码,如下图所示,第一行是序列化的结果,可以看出,json将列表转换成一个类型为字符串格式的序列化结果;第二行是反序列化的结果,其将之前序列化的结果又转化成为列表Company。
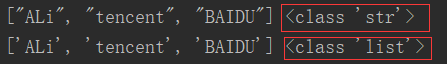
dump的功能可以直接将序列化的结果写入文件中,load也可以直接从文件中读取并反序列化。
dump:
1 obj = ['foo', {'bar': ('baz', None, 1.0, 2)}] 2 with open(r"c:json.txt","w+") as f: 3 json.dump(obj, f)
load:
1 with open(r"c:json.txt","r") as f: 2 print json.load(f)
但是,当存在较为复杂的数据类型时,json却不能够很好的序列化。比如,我们在字典中添加函数:
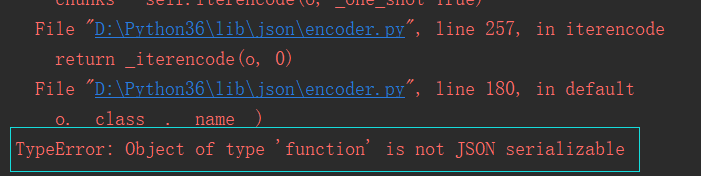
1 def sayhi(name): 2 print("hello,",name) 3 s = {"desc":"invilad-citykey", "status":1002, "func": sayhi} 4 5 result = json.dumps(s) # 序列化 6 result1 = json.loads(result) #反序列化 7 8 print(result, type(result)) 9 print(result1, type(result1))
执行上述代码,结果如下,显示json没有类型为函数的序列化。
因此,JSON在python中分别由list和dict组成。
pickle模块
pickle模块的用法和json模块没用太大的区别,但其可以实现上述需求。
1 import pickle 2 3 def sayhi(name): 4 print("hello,",name) 5 s = {"desc":"invilad-citykey", "status":1002, "func": sayhi} 6 7 result = pickle.dumps(s) # 序列化 8 result1 = pickle.loads(result) #反序列化 9 10 print(result, type(result)) 11 print(result1, type(result1))
上述字典中包含函数,利用pickle模块可以实现序列化与反序列化。

区别:
1、JSON只能处理基本数据类型。pickle能处理所有Python的数据类型。
2、JSON用于各种语言之间的字符转换。pickle用于Python程序对象的持久化或者Python程序间对象网络传输,但不同版本的Python序列化可能还有差异。