其中OCR识别的关键技术在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。
自然场景文字识别(Scene text detection)
01. Detecting Text in Fine-scale proposals
02. Recurrent Connectionist Text Proposals
04. Model outputs and loss function
什么是OCR?
OCR的全称是"Optical Character Recognition".它利用光学技术和计算机技术读取打印在纸上或写在纸上的文字,并将其转换为计算机和人都能理解的形式.
简易OCR的过程

- 第一步,通过图像信息采集(一般是相机),得到了一幅包含待识别字符的图像,并对其结构进行了分析.
- 第二步,采用阈值运算等图像处理方法对待测对象进行去噪,并校正待检测的物体.
- 第三步,由于文本信息的特殊性,需要进行行和列分割用于检测单个或连续的字符.
- 第四步,将分割后的字符图像导入识别模型进行处理, 从而获得原始图像中的字符信息.

其中,OCR识别的关键技术在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。
自然场景文字识别(Scene text detection)
印刷字体的OCR技术现在已经相当成熟.腾讯Tim手机版自带图像文本提取功能;Microsoft Office lens具备扫描功能.虽然不能说100%正确,但基本上可以做到95%以上的打印字体识别基本可以完成.所以现在的技术关注更多的是"场景文本识别",表示在复杂的环境中进行字符识别.如下图所示的两种环境:

复杂场景的字符识别的操作主要包含两步:文本检测和文本识别.CTPN便是一种效果不错的提取场景文本的算法,它可以检测文本信息在自然环境中的位置.
在选择图像中的位置信息时,很容易想到用于目标检测的R-CNN模型(从一副图中寻找RoI).毕竟,近几年中,谈起图像处理,人们会想到CNN.
基于这种处理方式,可以将"字符位置"进行标记,然后将截取的图片放入CNN模型中进行处理? 然而,现实并非如此. 大量文本信息的文本、字体、位置等各种情况直接对R-CNN方法造成了干扰,造成了严重偏差。鉴于这种情况,CTPN便是通过结合CNN的优点,针对环境文本信息做出反应的模型.
CTPN 网络结构
文本信息的字符是一个序列,是一个由"字符、部分字符、多字符"组成的序列。如下图所示,待检测的文本信息具备"序列"这样的特征. 很显然,基于这样的特征,文本检测识别的目标不同于一般的目标检测,可以独立的针对各个目标进行检测.同时,基于"序列"的特征,会比较容易的想到利用上下文的语境,利用上下文确定文本的位置. 这自然会想到RNN系列的模型.

值得注意的是,作者认为预测文本水平方向的位置要比预测文本垂直方向的位置困难得多。
因此,在检测过程中,可以引入数学上类似的"微分"思想。首先检测一个固定宽度的小文本段。在后处理部分,将这些小文本段连接起来,得到一条文本行,如下图所示。

通过将CNN和RNN,以及数学上"微分"的思想作用于处理文本。CTPN的网络结构如下图所示:
绘制结构图:http://ethereon.github.io/netscope/#/editor
结构代码:https://github.com/tianzhi0549/CTPN/blob/master/models/deploy.prototxt
具体操作可以划分为5步:
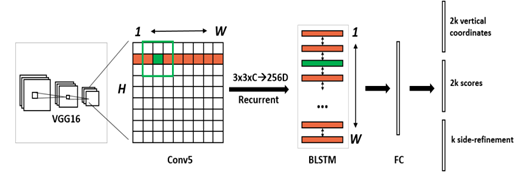
1. 首先,使用VGG-16模型中的前5个Conv获得feature map,大小为N*C*W*H。VGG网络结构如下图所示,使用的网络结构如红色框体内。由于红色框体内共包含4个池化操作,因此,此时输出的feature map 为原图的1/16。

2. 利用3*3滑动窗口从上一步得到的feature map中提取特征,生成3*3*C的特征向量。输出N*9C*H*W的feature map。并利用这些特征预测多个anchor。这里anchor的定义与Faster-Rcnn中的相同。
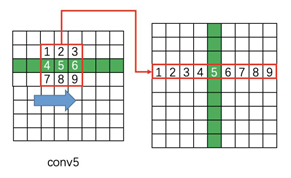
3*3滑动窗口的操作如下图所示,即提取每个点附近的9个临近点,每行都如此处理,也就使得特征提取前后分辨率不发生变化。即feature map维度的变化如下:
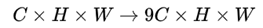
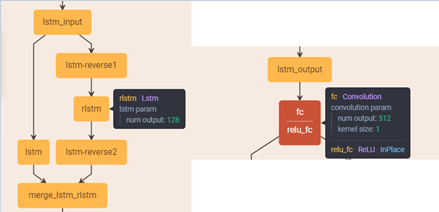
3. 将上一步得到的特征输入到Bi-LSTM中,输出W*256的结果(128双向整合结果),再将结果输入到512维全连接层(FC)中。结构输出节点数量可参照下图。
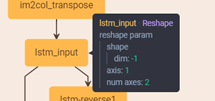
这里会有一个转换,就是如何将图像形状(N*9C*H*W)转化为LSTM可以输入的向量(一维向量)?如下图im2col_transpose操作所示,将feature map(N*9C*H*W)进行reshape操作。

reshape的具体操作如下所示:
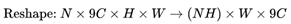
基于此,作者以NH=Batch,W作为LSTM的最大时间长度,9C作为LSTM网络输入节点的个数。此时,数据维度符合LSTM输入的要求。
4. 最后,通过分类或回归得到的输出主要分为三个部分。根据网络结构图,从上到下依次为:
- vertical coordinates(2k):锚框的高度和中心点y轴坐标;
- scores (2k):锚框的类别得分,即表示当前锚框中包含的内容为是否是一个字符的得分。
- side-refinement (k):表示水平偏移量。
其中,k表示锚框的数量。在实验中,锚框的水平宽度为16 像素,
这一部分是通过Faster R-CNN中的RPN网络获得text proposals,也就是上述三部分的过程。

5. 获得text proposals后,使用文本构造算法,将得到的细长矩形合并到一个文本序列框中。

细节补充
01. Detecting Text in Fine-scale proposals
CTPN与RPN和Faster R-CNN主要区别在于引入了"微分"思想,即将候选区域切割成细小的条状进行处理。其采用了一组(10个)等宽度的anchor,高度从11到283变化(by ÷0.7 each time)。宽、高可以清晰的表示为:
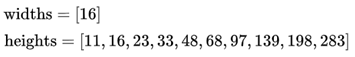
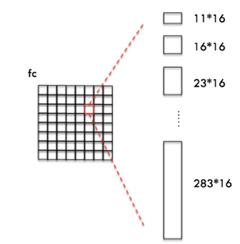
RPN与Fine-scale text proposals对比结果如下所示:

文献中返回y轴坐标的方法如下所示,其中,*表示真实值;vc, vh表示预测的中心y坐标和高度,vc*,vh*表示Ground Truth;cya,ha表示anchor的中心y坐标和高度(pre-computed)。cy和h表示预测的中心y坐标和高度。
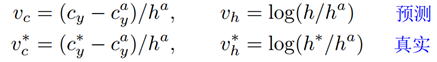
02. Recurrent Connectionist Text Proposals
该方法对应于前一个过程中"Bi-LSTM"的细节,上下文信息用于文本位置的定位。Bi-LSTM具有128个隐含层节点,输入是由3*3的滑动窗口构成的3*3*C的特征,由于是双向,最终形成256的输出。如下图所示:

使用RNN和不使用RNN的对比结果如下图所示,第一行是不使用RNN的CTPN;第二行是使用RNN的CTPN。

03. side-refinement
side-refinement是最后的优化过程,通过合并和汇总已定位的"小矩形",得到所需文本信息的位置信息。即合并下图中的红色小矩形,最后生成一个黄色大矩形。"小矩形"是否保留直接通过有无文本信息的得分是否大于0.7来判断。

对于将一系列红色小矩形合并成最终的黄色大矩形的方法遵循以下规则(下面简称文本线构造方法):

因为它指定返回框的宽度为固定的16像素,所以它将导致一些位置错误。定义公式如下:
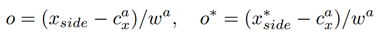
其中,*表示GroundTruth;Xside表示回归的左/右边界,cxa表示锚点中心的横坐标,wa为16像素的固定宽度。所以O的定义相当于一个缩放比例,这有助于我们对回归后的方框结果进行拉伸,从而更好地匹配实际文本的位置。对比图如下,红色方框为使用side-refinement,黄色方框为未使用side-refinement的结果:

04. Model outputs and loss function
输出一共包含三个部分:
- 是否有文本的得分 2k
- 纵坐标 vc,vh 2k
- side-refinement的偏移量(o)k
因此,损失函数也包含三部分,一个分类损失,两个回归损失:
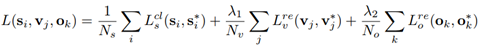
- anchor softmax loss: 针对每个anchor中是否包含文本。si*={0,1};
- anchor y坐标回归损失: 针对包含文本的anchor y方向的偏移量;
- anchor x坐标回归损失: 针对包含文本的anchor x方向的偏移量。
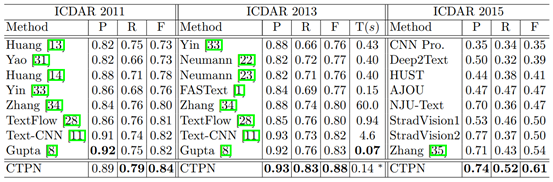
在整个过程中,该方法最大的两点也是将RNN引入到文本检测中,利用"微分"的思想来减少被检测的误差,以及使用定宽锚检测多块分割。最后一个合并序列是需要检测的文本区域。CNN和RNN之间高效无缝的连接大大提高了准确率。实验对比如下表所示: