论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
文献地址:https://arxiv.org/pdf/2004.10934.pdf
源码地址:https://github.com/AlexeyAB/darknet

今天,使用YOLOv4对无人机进行目标检测,将自己的训练过程记录下来,总的来说,和之前Darknet的YOLOv3版本的操作完全相同。
环境
Ubuntu 16.04
Python: 3.6.4
OPENCV:3.4.0
CUDA: 10.0
GPU: RTX2080Ti
首先下载代码:
1 git clone https://github.com/AlexeyAB/darknet.git
由于都是AlexeyAB大神的杰作,在使用上与YOLOv3使用过程几乎相同,因此,使用起来较为熟悉。
1. 编译make
如果硬件设备包含GPU加速,需要对makefile文件进行修改,修改后如下图所示。
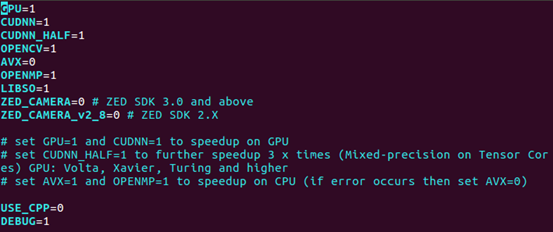
然后在终端进行编译:
1 # cd到darknet文件夹下: 2 make # 或make -j8
2. 下载开源权重,并测试:
yolov4.weights: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
yolov4.conv.137: https://drive.google.com/open?id=1JKF-bdIklxOOVy-2Cr5qdvjgGpmGfcbp
使用与训练的权重进行测试:
1 ./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg

3. 训练自己的数据集
构建与YOLOv3相同的数据文件夹(此处仍以YOLOv3的方式构建):
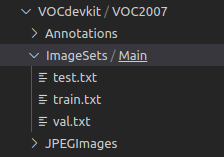
先按照上面的格式准备好数据。其中:
- Anontations用于存放标签xml文件
- JPEGImage用于存放图像
- ImageSets内的Main文件夹用于存放生成的图片名字,例如:

4. 准备YOLOv4需要的label和txt
首先,从路径为"/home/vtstar/yolov4/darknet/scripts"下的voc_label.py复制到项目根目录下(darknet),并对其内容进行修改。

其中,#后为注释掉的为原先的,未被注释掉的是修改后的,sets中为年份(VOC后的数字,例如VOC2007中的2007)和包含的数据集(Main文件夹中划分数据集的txt的种类),classes中填写标注文件中包含的待识别物体的类别标签。

由于是将voc_label.py复制到项目的根目录下,所以不需要对相关文件的路径进行修改。
执行voc_label.py,在根目录下将会生成训练需要的文件,即各个训练集中包含图像的路径。

5. 修改配置文件
这里同yolov3的使用是一致的,需要修改的配置文件包含三个部分:
-
cfg目录下:
-
voc.data / coco.data (二选一即可,本篇使用voc.data)
- 存放相关文件的路径:
-

- 类别的数量
- 训练过程中训练数据和验证数据的txt文件(voc_label.py生成的)
- 类别标签名称
- 存放权重的路径
-
yolov4-custom.cfg
-
yolov4训练参数和相关网络结构的修改:
-
输入图像大小和训练测试阶段中batch的数量和划分次数;
- 图像的大小可以是32的倍数。
-
-

-
训练代数;
- github中给出了max_batches的基本设置方法,2000 × classes。当然,设置的大一些也是可以的,只不过后期基本上在某一值附近震荡
- 值得注意的是,steps的设置是max_batches × 80% 和 max_batches × 90%/。
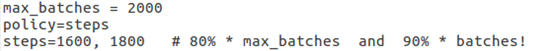
-
网络结构;
-
根据待测目标类别的数量更改YOLO层(3个)和YOLO层前一层的卷积层(3个)
- 包含YOLO前一层卷积层的卷积核个数:(classes + 5)*3
- YOLO层的类别数classes。
- 锚框(可选,kmeans聚类)
-

-
data目录下:
- voc.names / coco.names (二选一即可, 多个类别隔行输入即可,本篇修改voc.names)
6. 开始训练
训练指令(与yolov3依旧相同):
1 ./darknet detector train cfg/voc.data cfg/yolov4-custom.cfg yolov4.conv.137 -gpus 0
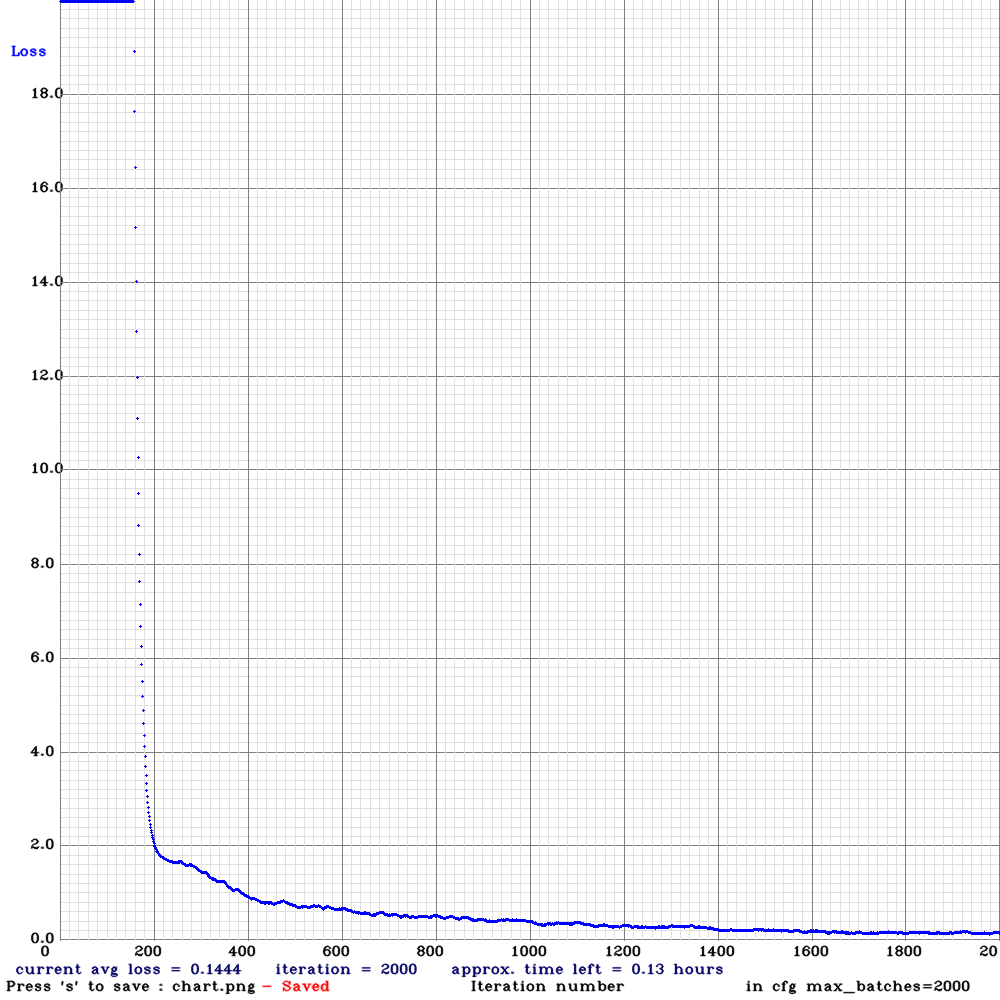
在训练过程中,与之前yolov3不同的是yolov4在训练过程中会弹出训练过程中的loss的实时图像,如下图所示,会动态的显示每一代的损失,当前代数和预计剩余时间。
对于下图,值得一提的是起初loss在图像上看到的是平的,并不是意味着损失不下降,只是loss相对与18.0而言都太大了,在固定坐标的图像上难以显示,因此可视化的是平的。
7. 预测
预测指令:
1 ./darknet detector test cfg/voc.data cfg/yolov4-custom.cfg yolov4-custom_xxxx.weights
然后在提示的Enter Path中输入待测图像的路径。如下图所示。

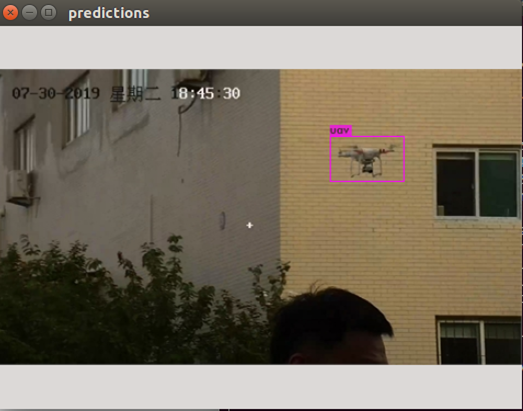
或者直接在预测指令后添加图像的路径。
这是单张图像的测试方式。
总的来说,和之前yolov3的操作完全相同,可以很好的迁移!