论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
文献地址:https://arxiv.org/pdf/2004.10934.pdf
源码地址:https://github.com/AlexeyAB/darknet

2019年YOLOv3在各个领域都获得了广泛的应用,并获得了不错的效果。上个月YOLOv4的发布,必定会带来一波技术革新的浪潮。然而,YOLOv4实际上是一篇结合了大量前任的研究,通过适当的组合,并适当创新的高水平论文,实现速度和精度上的平衡与再创新高。
文献中作者将前人的工作主要归纳为Bag of freebies和Bag of specials。前者归纳的tricks是指只在训练阶段增加耗时,不影响推理(测试)过程中的时间消耗,称为"赠品";后者归纳的tricks是指会略微增加推理过程的时间消耗,但可以显著的提升模型的性能,称为"特价"。本系列按照paper中编排的顺序,对各种tricks进行庖丁解牛,重在扫盲一些思想。
本节主要针对Bag of freebies中谈到数据增强,分析其思想和核心细节。包含以下tricks:random erasing、 cutout、 hide-and-seek、grid mask、Adversarial Erasing、mixup、cutmix、mosaic、Stylized-ImageNet、label smooth和dropblock。
01 Random Erasing

论文名称:Random erasing data augmentation
文献地址:https://arxiv.org/pdf/1708.04896v2.pdf
源码地址:https://github.com/zhunzhong07/Random-Erasing
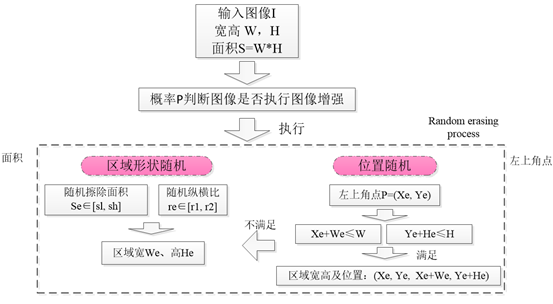
随机擦除数据增强技术是在训练中,随机擦除随机选择图像中的一个矩形区域,并用随机值擦除其像素。效果如下图所示,从随机擦除的效果图上可以看出,该数据增强方式的提出主要针对遮挡问题。通过随机擦除目标的特征模拟遮挡的效果,提高模型的泛化能力,使模型在训练过程中仅通过局部特征对目标进行识别,强化模型对于目标局部特征的认知,弱化模型对于目标全部特征的依赖。模型通过这样的数据进行训练,将会对噪声和遮挡更具鲁棒性。

Random erasing 算法流程如下,主要包含两个部分:
- 区域大小的随机;
- 位置的随机。
主要流程如下:
伪代码如下:

由于random erasing的应用具有图像分类和目标检测两种不同的场景,二者的区别在于是否知道目标所在的位置。对于这两种情形:
-
图像分类
- 在原图中随机选择擦除区域; --- 漫无目的的擦除
-
目标检测
- 在原图中随机选择擦除区域;(IRE)
- 在每个b-box上独立执行random erasing,即此时b-box相对于图像一样成为一个独立的个体;(ORE) --- 由指导的擦除
- 在图像和目标b-box上随机选择擦除区域。(I+ORE)
具体如下图左图所示。
作者还将Random Erasing与Random Croping结合,在随机剪切的图像上添加随机擦除,如下图右图所示。

02 Cutout

论文题目:Improved Regularization of Convolutional Neural Networks with Cutout
文献地址:https://arxiv.org/abs/1708.04552v2
源码地址:https://github.com/uoguelph-mlrg/Cutout
Cutout与random earsing的出发点是一致的,都是针对机器视觉中存在的目标遮挡问题。通过对训练数据模拟遮挡,一方面能解决现实中遮挡的问题,另一方面也能让模型更好的学习利用上下文的信息。
作者描述了两种Cutout的设计理念:
-
开发了一种有针对性的方法,专门从图像的输入中删除图像的重要特征,为了鼓励网络考虑不那么突出的特征。做法为删除最大激活的特征,具体是:在训练的每个epoch过程中,保存每张图片对应的最大激活特征图(输出的最大特征激活点),在下一个训练回合,对每张图片的最大激活图进行上采样到和原图一样大,然后使用阈值划分为二值图,盖在原图上再输入到cnn中进行训练。因此,这样的操作可以有针对性的对目标进行遮挡。如下图所示。
- 对于上述操作的进一步理解:由于网络经过训练后,输出特征的最大激活点会围绕在目标区域中,并且由于有针对性的遮挡,输出的最大激活点的位置(将要遮挡的位置)将不同于本次输入的位置(原先的位置已遮挡,此时不可能被激活),也就是说,在训练的每一代中,可以围绕目标的不同区域进行动态遮挡训练。而不像之前对输入图像进行数据增强,一张图片在整个训练过程只有一种遮挡模式。该操作有些像dropout,每次训练中都随机性的选择参与训练的节点,当然也势必会带来收敛速度的减慢。
- 虽然通过理论感知,这种有针对性的遮挡要比单纯随机遮挡高效,但实际效果区别却差不多,(至于为什么效果区别不大,并不理解,可能受二值化阈值的影响,需要自适应?仍有待继续研究)反而这种增加了更多计算量和内存,得不偿失。

2. 另外一种设计理念与random erasing及其类似,但实施起来要比random erasing简单,具体操作是:选择一个固定大小的正方形区域,然后将该区域填充为0即可,为了避免全0区域对训练的影响,需要对数据中心归一化到0。并且,与random erasing不同的是,其以一定概率(50%)允许擦除区域不完全在原图像中。

03 Hide-and-seek

论文题目:Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
文献地址:https://arxiv.org/pdf/1811.02545.pdf
源码地址:https://github.com/kkanshul/Hide-and-Seek
Hide-and-seek本质上也是通过隐藏一部分区域,迫使网络寻找其他特征辨别物体。与前两种数据增强方式不同的是,Hide-and-seek不再通过随机位置确定patch的位置,而是将原图划分为若干份(划分方式与ROI POOL有类似之处),然后对划分的每一份依概率进行隐藏,并且在每一代中,每一张图片的隐藏区域都是随机的,并且该操作仅添加于训练过程中,这与dropout也有相同之处。如下图所示,狗子的图像在各代中隐藏区域,隐藏数量都不相同。测试过程中,并未添加数据增强。

例如,将224*224*3的图像划分为16份,每个patch为56*56*3,每个patch是否隐藏的概率p=0.5.
作者认为,隐藏区域的替代像素值十分重要,如果简单的将像素值替换为0,暴力填黑,会造成训练和测试数据分布不一致问题。因此,作者采用整个数据集的均值来处理【不是单张图像的均值】。
个人感觉这种操作方式与要识别目标的大小和分割分数有较强的关联,并且这种数据增强方式有极大的可能出现目标区域全部删除或者全部保留的情况。
04 GridMask

论文题目:GridMask Data Augmentation
文献地址:https://arxiv.org/pdf/2001.04086v2.pdf
作者将现有的数据增强方法大致分为三个类别:
-
空间转换spatial transformation
- 随机尺寸
- 裁剪
- 翻转
- 旋转任意角度
-
颜色扭曲color distortion
- 改变亮度
- 改变色调(hue)
-
信息丢弃information dropping
- random erasing
- cutout
- hide-and-seek(HaS)
作者的出发点来源于为了避免连续区域的过度删除和保留的问题,即在删除和保留图像上的区域信息之间达到合理的平衡,Cutout,HaS中依概率对划分区域进行隐藏,很有可能造成目标全部删除或者全部保留的现象,如下图所示。

random erasing中漫无目的擦除的策略也可能导致这一现象的发生。

作者发现了一种与上述方法不同的理念:擦除的区域既不是连续的区域,也不是随机的像素值,而是一系列不连贯的像素集。如下图所示:

从上图中可以看出,不连贯像素集之间是等间距分布,起始位置任意。
不连贯的像素集可以由四个参数确定:

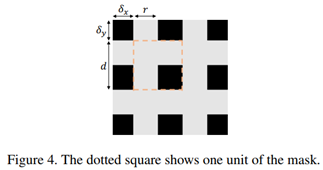
- r是单位中较短的灰边的比值。可以看出,r在一定程度上决定了原图的保留比例,即r越大,原图保留的越多。
- d是一个单元的长度。d在一定程度上决定移除正方形区域的大小。
- δx和δy是第一个完整的单元与图像边界之间的距离。【起点的位置】
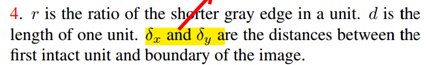
四个参数的选择方式:
- 参数定义:
input image:
掩码二值矩阵M:
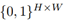
其中,1表示保留原像素,0表示移除原像素。
output image:
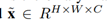
- r的选择
r确定输入图像的保持比。在几何形状中,保留比例可以表示为:
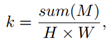
当保留比例过大,数据增强的效果较弱,可能会过拟合;
当保留比例过小,丧失过多信息,会导致欠拟合;
那么,r与k存在的关系可以建立为:
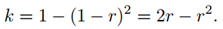
上述关系的公式可以对应上图中的虚线正方形中。
- d的选择
d的长度不影响保持比。但会决定了一个落下的正方形的大小。
当r确定后,正方形的边长l与d的关系为
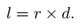
可以很明显的看出,d越大,l越大,也就是黑色块面积越大,相应黑色块的个数就会越少。当d固定后,正方形的边长在训练过程中为固定值,因此,需要对d进行随机处理。
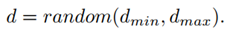
很容易得出结论,一个较小的d可以避免大多数失败的情况。但是最近的一些研究表明,去掉一个非常小的区域对于卷积运算是无用的。
- δx和δy的选择
用于起始块的偏移量。
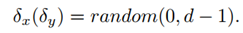
综上所述,算法存在保留比例选择的问题,可以采用固定值或者线性增加的操作,作者认为线性增加会更好。即保留比例由小变大,达到一定比例后固定。

05 Object Region Mining with Adversarial Erasing

论文题目:Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach
文献地址:https://arxiv.org/pdf/1703.08448.pdf
针对弱监督语义分割问题,作者研究了一种利用分类网络逐步挖掘识别目标区域的方法。其操作与Cutout中提出的第一种理念极为相似,也是通过训练的方式通过对激活的部分形成遮挡,而挖掘不同的可区别目标的区域,只不过本文作者在这里将各代激活的区域组合形成分割的结果。
具体来说:每代训练中,对于每张图片都可以得到CAM(Classification Activation Method),将CAM图二值化然后盖在原图上,进行下一次迭代训练,每次迭代都是学习一个不同的可判别区域,而迭代的停止条件是无法完成分类的任务。因为可判别区域理论上会全部被盖住。
如下图所示:
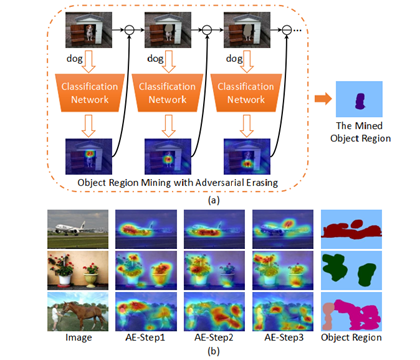
作者在实现这一想法使用了自编码器AE,算法流程如下:

06 Mixup

论文题目:mixup: BEYOND EMPIRICAL RISK MINIMIZATION
文献地址:https://arxiv.org/pdf/1710.09412.pdf
mixup大家应该都很熟悉,其核心就是将两张图像和label采用比例混合,即图像融合。例如下图增加雨滴的特效。
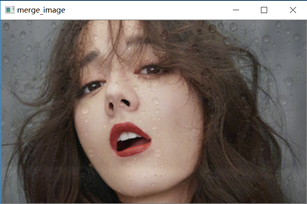
当然,mixup主要是为了图形分类,两张图像线性混合时,label也要线性混合。

作者给出了mixup在pytorch上的部分代码:

对于目标检测如果采用mixup的方式融合,损失函数加权相加外,个人认为标签就不需要进行线性混合了。

07 Cutmix && Mosaic(YOLOv4)

论文题目:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
文献地址:https://arxiv.org/pdf/1905.04899.pdf
源码地址:https://github.com/clovaai/CutMix-PyTorch
从算法名称上来看,cutmix相当于Cutout和mixup的结合版。如下图所示,Cutmix是在Cutout遮挡的位置上添加了其他的图像。
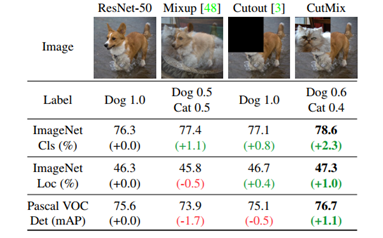
作者认为mixup的问题在于,它们在局部是模糊的、非自然的,因此会使模型混淆。
cutmix和mixup的区别是,混合位置是采用hard 0-1掩码,而不是soft操作,相当于新合成的两张图是来自两张图片的hard结合,而不是Mixup的线性组合。但是其label还是和mixup一样是线性组合
结合操作可以定义为:
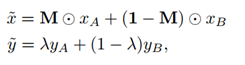
M是与原图大小相同的{0,1}掩码矩阵,λ用于控制标签融合的线性混合度。并且是通过λ参数控制裁剪矩形大小,因为λ本身就是权衡两个图像的比例参数,可以反应到图像的大小上。
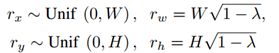
伪代码如下:

Mosaic是YOLOv4中提出的一种数据增强方式,属于Cutmix的扩展。Cutmix是两张图像的混合,即Cutout仅有一块区域,而Mosaic是4张图像的混合,一张图相当于4张图(一节更比六节强...)相当于变相的增加了训练过程中batch的数量,也可以相应减少训练过程中的batch,降低对于硬件的要求。

08 Stylized-ImageNet

论文题目:ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
文献地址:https://arxiv.org/pdf/1811.12231.pdf
源码地址:https://github.com/rgeirhos/texture-vs-shape
通过论文题目就可以看出作者的结论:CNN通过训练学习到的会偏向于纹理特征,而增加对形状偏差可以提高准确性和鲁棒性。这样的结论来源于作者通过ImageNet训练得到的CNN。如下图所示,作者发现CNN会将大象纹理的猫误分为大象相关的类别,而不是猫的类别。
基于此,作者提出了Stylized-ImageNet数据集,即风格化后的ImageNet,通过风格化的数据集与原数据集混合进行训练,可以平衡纹理与形状,使模型即关注纹理,也关注形状。并且发现这样做可以提升目标检测的精度和鲁棒性。

另外,作者准备了六类数据来验证这一观点,分别是:
- 正常图片
- 灰度图片
- 只有轮廓的图片
- 只有边缘的图片
- 只有纹理没有形状的图片
- 纹理与形状不一致的图片
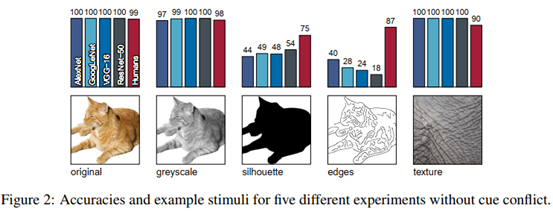
通过这六类图片在4种主流网络上训练,并结合人的主观判断。如下图所示,可以看出:
- 各主流网络在正常图片和灰度图片上具有较高的精度;
- 对于只包含轮廓和只包含边缘的图片准确率则显著降低;
- 对于仅包含纹理不含形状的图片却具有极高的准确率。
可见,CNN在识别物体时,主要参考的是纹理信息,而不是形状。并且形状似乎没有那么重要。
ImageNet简称为IN,Stylized-ImageNet简称为SIN
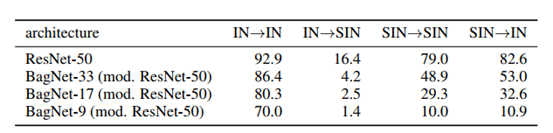
如上表所示,作者通过不同训练-测试组合进行进一步实验,从第一行可以看出,通过IN训练的图像不能适应失去纹理特征的SIN图像(IN-SIN);而通过SIN训练的图像精度(SIN-SIN)不如(IN-IN),说明失去纹理特征的图像对于模型而言训练难度较大;而SIN-IN的测试效果却比SIN-SIN的要好。
后三行是通过限制ResNet-50网络深度,从而限制感受野进行分析,(感受野分别为33*33/17*17 /9*9)当感受野降低时,通过失去纹理SIN训练的模型精度显著下降,说明SIN训练的模型中主要通过形状shape识别目标,由于感受野的降低,失去了目标shape的信息,从而导致进度的骤降;而IN-IN模型的精度虽然有所下降,但影响并不大,可见,由IN训练的图像主要通过纹理捕捉信息,而通过SIN训练的图像主要通过形状捕捉信息。
基于上述实验,确实验证了CNN在训练过程中,主要依靠纹理捕捉信息,当纹理信息丧失后,主要依靠形状捕捉信息。但还不能证明通过纹理与形状的平衡能够提升模型的精度。

上表的实验结果表明,将SIN与IN数据集混合训练可以提升模型的精度。并且,使用SIN与IN数据集混合训练后的模型再使用IN进行微调,可以进一步提升模型的性能。
综上所述:CNN训练学习过程中主要依赖于纹理特征,而不是形状特征。但是这是不好的,为了突出形状bias,作者采用SIN做法进行数据增强,SIN与原始数据混合训练就可以实现纹理与形状的平衡,提升模型的精度和鲁棒性。但可能对于小目标物体的识别效果并不大。
09 label smooth

论文题目:Rethinking the Inception Architecture for Computer Vision
文献地址:https://arxiv.org/pdf/1512.00567.pdf

label smooth名为标签平滑,是一种针对分类问题(多分类)的正则化技术,优化对象为Label。也是针对分类问题中错误标注的解决办法之一。
对于多分类问题,通常将类别真值表示为one-hot vector(独热编码)。
简而言之,one-hot就是将离散的类别编号表示为类别长度的向量,该向量中仅有一个数字为1,其余均为0,并且1的位置可以独立的表示各个类别。例如对于包含0,1,2,3四个类的多分类问题,2的独热编码表示为[0,0,1,0];同理,3的独热编码表示为[0,0,0,1]。
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
- 1)无法保证模型的泛化能力,容易造成过拟合;
- 2) 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难适应。会造成模型过于相信预测的类别。
label smoothing的操作就是针对one hot编码,对one hot编码采取平滑处理:
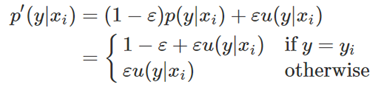
其中,ε∈[0, 1],而μ(y|xi)服从噪声分布,相当于对one hot编码添加了正则项。
由于one-hot发生了改变,因此,在使用one hot和softmax后的预测概率构成的交叉损失函数也将发生相应的变化,具体来说:
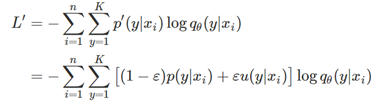
具体的推导过程可以参考:
https://leimao.github.io/blog/Label-Smoothing/
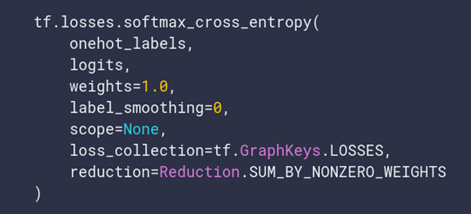
If label_smoothing is nonzero, smooth the labels towards 1/num_classes:
new_onehot_labels = onehot_labels * (1 - label_smoothing) + label_smoothing / num_classes
What does this mean?
Well, say you were training a model for binary classification. Your labels would be 0 — cat, 1 — not cat.
Now, say you label_smoothing = 0.2
Using the equation above, we get:
new_onehot_labels = [0 1] * (1 — 0.2) + 0.2 / 2 =[0 1]*(0.8) + 0.1
new_onehot_labels =[0.9 0.1]
参考:https://towardsdatascience.com/label-smoothing-making-model-robust-to-incorrect-labels-2fae037ffbd0
总而言之:label smoothing就是一种正则化的方法而已,让分类之间的cluster更加紧凑,增加类间距离,减少类内距离,避免over high confidence的adversarial examples。
10 DropBlock

论文题目:DropBlock: A regularization method for convolutional networks
文献地址:https://arxiv.org/pdf/1810.12890.pdf
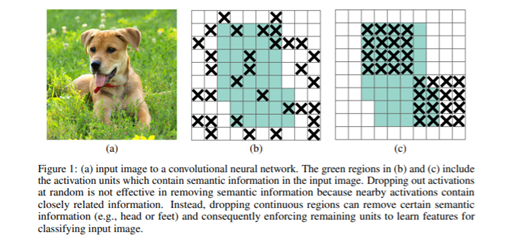
论文提出了一种针对卷积层的正则化方法DropBlock,该方法在输入层针对图像与之前谈到的Random Erasing、CutOut、GridMask等方法是相同的,但DropBlock还可以作用于网络处理过程中的feature map。
从方法名称上可以看出,DropBlock "Drop"的是block,而不单个像素点。如下图(b)和下图(c)所示:
DropBlock在实现中设置了两个主要参数:
-
block_size: 被丢弃区块的大小
- 该参数设置为固定值;
- 当block_size=1时,就是传统的dropout;
- 可以设置为3,5,7等。
-
γ:drop过程中的概率
- 服从伯努利公式
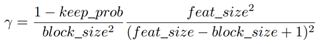
其中,keep_prob可以被解释为和传统的dropout中一样,保留一个单元的概率。有效区域的大小为
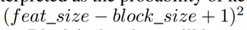
DropBlock的主要区别是在被删除的块中会有一些重叠,所以上面的方程只是一个近似值。keep_prob在0.75和0.95之间。
作者在做实验时候发现,block_size设置为7*7效果最好,对于所有的feature map都一样,γ通过一个公式来控制,keep_prob则是一个线性衰减过程,从最初的1到设定的阈值(具体实现是dropout率从0增加到指定值为止),而固定keep_prob效果不好。