论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
文献地址:https://arxiv.org/pdf/2004.10934.pdf
源码地址:https://github.com/AlexeyAB/darknet
YOLOv3在2019年的应用可谓是如火如荼,并获得了很好的效果。几天前(2020-04-23),Alex AB发布了YOLOv4,在开篇中,作者就谈到了一个很实际的问题:这几年深度学习的发展中,有大量的方式可以提升CNN的准确性,需要在大型数据集上对这些特性的组合进行实际测试,并对结果进行理论验证。因为有些特性只能作用于特定的模型,而有些特性只能作用于特定的问题。
该论文提出了五大improvements,二十多个实验的trick,具有很好的指导意义。
YOLOv4在目标检测中的效果
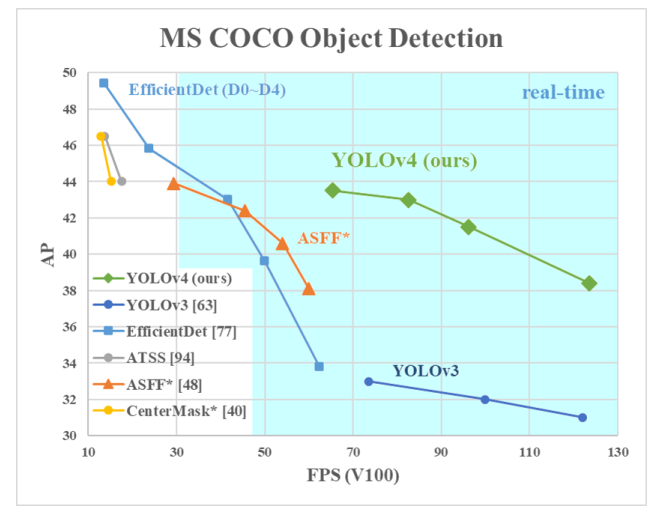
从上图中可以看出,YOLOv4相对于YOLOv3有很大的提升(mAP 提升 10个点,速度提升12%)。
以下视频为YOLO v4 在自动驾驶环境的测试结果:
https://www.youtube.com/watch/?v=VK2XnppfD\_o
作者的灵感
作者希望建立的模型更加容易使用:
- 只需要一块GPU便可以进行模型的训练;
- 测试可以具有实时、高质量和令人信服的目标检测结果。
作者总结的三大贡献:
- 设计了高效、强大的目标检测模型。重要的是可以使用一块1080Ti或者2080Ti GPU便可以满足训练这一模型的要求。
- 验证了对目标检测训练过程有影响的一些技巧。作者将对训练有影响,能够提升模型性能的技巧划分为两大类,其一称为Bag-of-Freebies,意在表示这类训练技巧只在训练阶段增加耗时,不影响推理(测试)过程中的时间消耗;其二称为Bag-of-specials,意在表示这类训练技巧会略微增加推理过程的时间消耗,但可以显著的提升模型的性能。
- 修改了一些方法CBN、PAN、SAM,使得这些方法在单个GPU上训练更加高效。
者对比了近几年one stage和two stage目标检测网络结构的差异,如下图所示,two stage的检测网络相当于在one stage的密集检测上增加了一个稀疏预测,或者说,one stage网络是two stage的RPN部分。
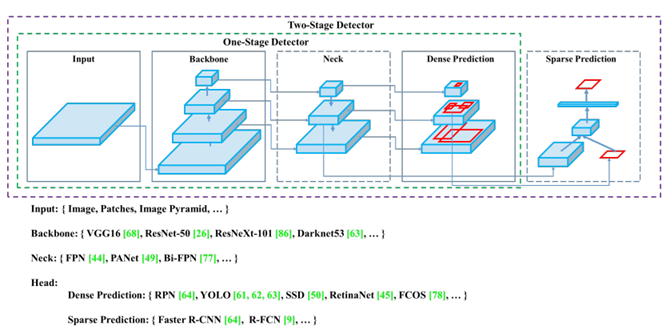
Object detection model
近几年的研究中,一个检测器通常由两部分构成:
- 通过ImageNet预训练的backbone
-
- GPU platform
-
-
- VGG
- ResNet
- ResXNet
- DenseNet
-
-
- CPU platform
-
-
- SqueezeNet
- MobileNet
- ShuffleNet
-
用于预测类别的b-box的head
-
- one stage object detector
-
-
- YOLO
- SSD
- RetinaNet
- anchor-free one stage object detectors
- CenterNet
- CornerNet
- FCOS
-
-
- two stage object detector
-
-
- R-CNN系列(fast R-CNN faster R-CNN R-FCN Libra R-CNN)
- anchor-free object detector
- RepPoints
-
-
- Path Aggregation Network
-
-
- FPN
- BiFPN
- NAS-FPN
-
-
- Additional blocks
-
-
- SPP
- ASPP
- RFB
- SAM
-
如下图所示:

Bag of freebies -- 赠品系列【不在推理时增加时间消耗的方法】
由于目标检测模型的训练通常是离线的状态。因此,研究员们会利用这一特性,在训练过程中增添某种trick,获得精度更高的模型,而不增加推理时的损耗。作者将这一类trick称之为赠品Bag of freebies。
-
数据增强 - 增加输入图像的可变性,对于不同环境的数据输入将会有鲁棒性。
-
光度扭曲
- 在处理光度失真时,我们调整图像的亮度、对比度、色调、饱和度和噪声。
-
几何扭曲
- 添加随机缩放、剪切、翻转和旋转
-
以上的方法均为像素级的处理。下面的方式是针对遮挡问题的数据增强处理:
-
选择图像中的矩形区域,填入一个随机的或互补的零值
- random erase
- CutOut
-
随机或均匀地选择图像中的多个矩形区域,并将其替换为所有零。
- hide-and-seek

用一句话来总结,就是在训练集的图像中打矩形补丁,从而在训练数据集中形成遮挡的分布形式。
上述的方式是在数据中进行特征的空洞处理。而在特征中,通常会使用Dropout,DropCon nect, DropBlock等方式,细思之后,Dropout这类方法确实与遮挡问题的处理方式有相似之处。GAN也通常用于数据增强。
-
BBox回归的损失函数
-
MSE (传统的目标检测方法)
- 中心点坐标和宽、高
- 左上角点坐标和右下角点坐标
-
偏移量 (基于anchor的方法)
- 中心点x,y偏移量 宽,高偏移量
- 左上角点x,y偏移量,右下角点x,y偏移量
-
IoU损失
- GIoU损失
- DIoU损失
- CIoU损失
-
Bag of specials -- 特价系列【在推理时增加少量时间消耗,但对模型效果提升显著】
作者将只增加少量的推理成本,但可以显著提高目标检测的准确性的模型插件和后处理方法称为特价"bag of specials"。这些模型插件往往用于增强模型特定的属性,例如:
-
增大感受野的技巧:
- SPP
- ASPP
- RFB
-
引入注意力机制
- Squeeze-and-Excitation(SE) 增加2%的计算量,增加10%的推理时间;
- patial Attention Module(SAM) 增加0.1%的计算量。
上述两种机制只增加CPU上的推理时间,对于GPU没有任何影响。
-
增强特征融合的能力
- FPN
- SFAM
- ASFF
- BiFPN(EfficientDet中)
-
激活函数
- ReLU
- LReLU、PReLU,ReLU6,
- SELU
- Swish
- hard-Swish
- Mish
-
后处理方法
-
NMS
- soft NMS
- DIoU NMS
-
YOLO v4
其基本目标是在生产系统和并行计算优化中提高神经网络的运行速度,而不是低计算量理论指标(BFLOP)。
作者提出了两种实时性神经网络的选项:
- 对于GPU,在卷积层中使用少量的组(1-8): CDPResNeXt50 / CSPDarknet53
- 对于VPU,使用grouped-convolution,但不适用SE-block,包含:EfficientNet-lite / MixNet / GhostNet / MobileNet v3
网络结构
作者提到,
CSPResNeX50 > CSPDarknet -- 分类精度
CSPResNeX50 < CSPDarknet -- 检测精度
对分类最优的参考模型不一定对检测器最优。与分类器相比,检测器需要满足以下条件:
- 分辨率更大的输入网络 -- 检测多个小型物体
- 更多层 -- 获得更大的感受野
- 更多参数 -- 检测多个不同尺寸的物体
下表中罗列了三种backbone模型的输入分辨率、感受野尺寸以及参数量。

作者认为CSPDarknet53是作为检测器最佳的模型。
作者在CSPDarknet53 增加了SPP block,因为这样可以显著增加感受野,并且分离出最重要的上下文特性,几乎不会降低网络运行速度。
作者使用PANet作为集成不同层参数的方法,而不是像YOLOv3中使用FPN。
综上所示,YOLOv4的构成包含:
- backbone: CSPDarknet53
- additional module: SPP
- neck: PAN
- head: YOLOv3
作者并未使用Cross-GPU Batch Normalization这类计算代价较高的方法。
在训练过程中可以选择的BoF和BoS

PReLU和SELU在训练过程中会造成难以训练,而ReLU6是专门为量化网络设计的,因此我们将上述激活函数从候选列表中删除。
Additional improvements
为了使设计的检测器更适合于单GPU上的训练,还做了以下额外的设计和改进:
- 一种新的数据增强的方式: mosaic和子对抗训练(self-Adversarial Training, SAT)
- 使用遗传算法进行超参数优化
- 改进的SAM和PAN,以及CmBN(cross mini-batch Nornalization)
mosaic和SAT
mosaic方法是将4张图像进行融合而形成一张图像的数据增强方式,如下图所示。通过这样的方式可以显著的减小mini-batch的大小。

SAT也展示了一种新的数据增强的技术。
- 在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自己执行一种对抗性攻击,改变原始图像,以制造图像上没有期望对象的假象。
- 在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
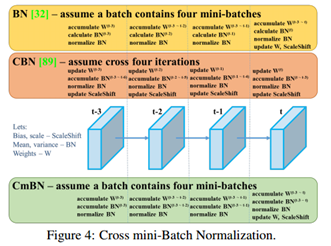
CmBN
CmBN是CBN的改进版本,收集一个batch内多个mini-batch内的统计数据。BN、CBN、CmBN的区别如下图所示。
此外,作者还将 SAM的空间注意力改为逐点注意力,并将 PAN的快捷连接的相加改为拼接(concatenation)。
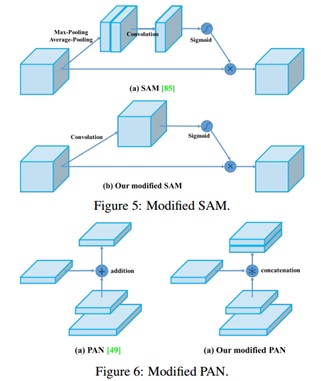
YOLOv4一览
除了之前介绍的关于YOLOv4 backbone,neck,head外,YOLOv4还包含:
-
BOF
-
backbone
- CutMix && Mosaic
- DropBlock 正则化
- 类标签平滑
-
detector
- CIoU-loss
- CmBN
- DropBlock
-
-
BOS
-
backbone
- Mish激活函数
- Cross-stage partial connections(CSP)
- 多输入权值残差连接(MiWRC)
- detector
- Mish 激活函数
- SPP-block
- SAM-block
- PAN
- DIoU-NMS
-

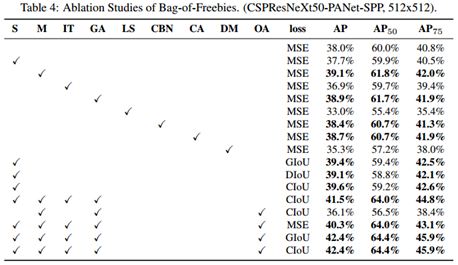
不同BoF在CSPResNeXt-50与CSPDarknet-53上的作用效果对比:


作者使用的多个技巧,在检测任务上的对比结果如下(这里需要参照文献4.3中各符号的含义):
网络结构解剖
NETRON网址:https://lutzroeder.github.io/netron/
使用Netron通过cfg文件绘制得到网络结构图如下图所示, 并对其结构细节进行标注,读者可以一部分一部分的对YOLOv4框架结构有所了解.主要可以划分为CSPDarknet Block(5个) - SPPNet - PAN -YOLO head四大部分.每个CSPDarknet Block(CSRResNet)包含ResNet的数量依次为1,2,8,8,4. 结构拆分后, YOLOv4的结构便不会再像结构图一样,看着令人眼晕!
由于使用的是PANNet进行的特征融合,在yolo层的生成是由大尺度到小尺度.即在下图中输入尺寸为608*608的情况下,yolo层依次是76*76*18 - 38*38*18 - 19*19*18.[一个类的情况]
这与使用FPN进行特征融合的YOLOv3正好相反(13*13*18 - 26*26*18 - 52*52*18)[一个类的情况].

总结
YOLOv4中包含多种模型提升的trick,信息量较大,需要对其中各个trick逐个剖析。可以作为目标检测的前沿综述,亦可作为当下目标检测的葵花宝典。