
数据集准备:
使用的是网上公开的widerface数据集(从事图像标注的人都是专业的呀)(http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/index.html),

需要下载前四个文件,包括训练集、验证集、测试集和人脸标注的txt文件(并没有原始的xml文件)。
训练集、验证集、测试集的数据如下图所示:

其中每一个数据集中都包含60种不同场景下人的图像。(该数据集包含不同类型的场景,场景比较丰富)如下图所示:

标注文件(txt/mat):

标注文件中包含上述6个(3类)文件,分别适用于不同的环境。其中包含的标注信息如下图所示:
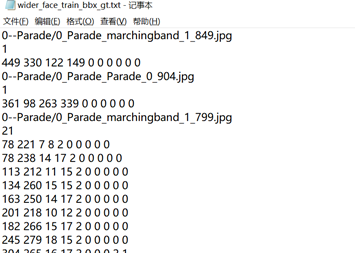
其格式和linux环境下需要的txt文件有所不同。
因此,参考博客https://blog.csdn.net/u010397980/article/details/86764637将给定的标注文件重新转化成xml文件。之后按照linux环境下数据集和文件格式的要求(如下图所示),将不同场景下的图像、xml文件放在一个文件夹下。

下述是上面介绍的将给定的标注文件txt转化为xml文件的代码,在使用过程中,只需要更改标注文件的路径txt_label和标注文件对应图像的路径img_path。
需要注意的是,通过下述代码生成的xml文件与图片一起分布在不同的场景当中,后续使用的时候需要提取。
1 # -*- coding: utf-8 -*- 2 # @Time : 2019/9/25 20:11 3 # @Author : smw 4 # @Email : monologuesmw@163.com 5 # @File : txt2xml.py 6 # @Software: PyCharm 7 # 将txt生成xml文件 8 import os 9 import cv2 10 11 from xml_writer import PascalVocWriter 12 13 # txt_label = "wider_face_val_bbx_gt.txt" 14 # img_path = "WIDER_val/images" 15 16 txt_label = "wider_face_train_bbx_gt.txt" # 修改train/val自带的标注txt文件的名称 17 img_path = "WIDER_train/WIDER_train/images" # 修改对应的train/val图片的地址 18 19 20 def write_xml(img, res): 21 # 22 img_dir = os.path.join(img_path, img) 23 print(img_dir) 24 img = cv2.imread(img_dir) 25 shape = img.shape 26 img_h, img_w = shape[0], shape[1] 27 writer = PascalVocWriter("./", img_dir, (img_h, img_w, 3), localImgPath="./", usrname="wider_face") 28 for r in res: 29 r = r.strip().split(" ")[:4] 30 print(r) 31 x_min, y_min = int(r[0]), int(r[1]) 32 x_max, y_max = x_min + int(r[2]), y_min + int(r[3]) 33 writer.verified = True 34 writer.addBndBox(x_min, y_min, x_max, y_max, 'face', 0) 35 writer.save(targetFile=img_dir[:-4] + '.xml') 36 37 38 with open(txt_label, "r") as f: 39 line_list = f.readlines() # 打开并读取标注文件 40 for index, line in enumerate(line_list): 41 line = line.strip() 42 if line[-4:] == ".jpg": 43 print("----------------------") 44 # print index, line 45 label_number = int(line_list[index + 1].strip()) 46 print("label number:", label_number) 47 # print line_list[index: index + 2 + label_number] 48 write_xml(line_list[index].strip(), line_list[index + 2: index + 2 + label_number]) # 写xml
Main文件夹下txt的生成
由于linux环境下的test.py会对所有的数据集重新进行训练集和验证集的划分,生成Main文件夹中的train.txt,val.txt(其中记录的是参与训练和验证数据的名称(不带后缀))。而本数据集已经划分好了训练集和验证集,如果将所有的数据重新放置在一起重新划分,未免有些傻用test.py的感觉。而且可能会丢失掉之前数据集划分的依据。因此,我们将训练数据集的xml文件放在一起,验证数据集的xml文件放置在一起,在windows10下对test.py文件进行改写,生成指定xml文件对应的txt(生成txt的过程只需要xml文件,不需要图像数据文件。因此,训练、验证数据是直接放在一起的)。然后,便可以将生成的txt文件移植到linux环境下的Main文件夹下。
整个过程的流程大致可以分为以下两步:
1. 将不同场景文件夹下的数据放置在一个文件夹中。(训练、验证的图像数据集直接放在一起)
2. 将不同场景文件夹下,生成的xml文件分别放置在train_xml和val_xml两个文件夹下(用于后续生成Linux下对应的txt文件) ---- 上述两部均同时人工进行
数据整理 (两个人,大概耗时1.5小时)
A. 图像数据集: 包含所有的训练、验证数据集
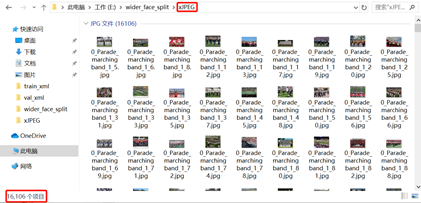
将给定数据集的 WIDER_train、WIDER_val中不同场景下的图像数据均放置在同一个文件夹xJPEG下。由下图所示,训练、验证数据共包含16106份。
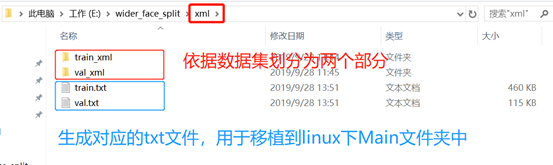
B. xml数据集:
将给定数据集的WIDER_train、WIDER_val中,生成的xml文件放置到train_xml和val_xml文件夹中。分为训练集的xml 和 测试集的xml 用于生成指定的txt(train.txt 和 val.txt)。
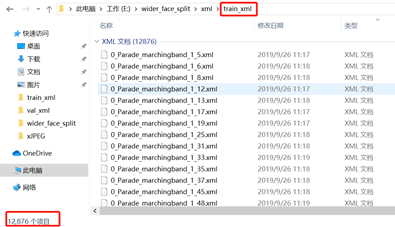
生成指定xml文件的txt [Main中的txt] (test.py的改写)
执行下述代码将会生成上述的train.txt 和 val.txt,然后移植到linux环境下的Main文件夹中。
1 # 根据指定训练集和测试集的xml文件生成txt 2 import os 3 import random 4 train_xmlfilepath = 'xml/train_xml' 5 val_xmlfilepath = 'xml/val_xml' # 获取训练、验证xml文件夹的路径 6 txtsavepath = 'xml' 7 total_train_xml = os.listdir(train_xmlfilepath) 8 total_val_xml = os.listdir(val_xmlfilepath) # 获取文件夹下所有文件的列表 9 10 num_train = len(total_train_xml) 11 list_train = range(num_train) 12 num_val = len(total_val_xml) 13 list_val = range(num_val) 14 15 ftrain = open('xml/train.txt', 'w') 16 fval = open('xml/val.txt', 'w') # 打开两个待生成的txt文件 17 18 # train 的txt的书写 19 for i in list_train: 20 name = total_train_xml[i][:-4] + ' ' 21 ftrain.write(name) 22 ftrain.close() 23 24 # val 的txt的书写 25 for j in list_val: 26 name = total_val_xml[j][:-4] + ' ' 27 fval.write(name) 28 fval.close()
生成txt文件后,就可以将train文件夹和val文件夹下的xml文件合并在一起,移植到linux下的Annotations文件夹下。 【合并xml,移植linux Annotations文件夹下】
Linux下lables文件夹下txt生成
voc_labels.py修改
在linux下,对voc_labels.py文件中的下述部分进行修改。
sets中更改文件夹设定的年份,以及Main文件夹中包含的txt数据集类型。修改类别名称。

part 2.2 在linux终端上执行
在darknet文件夹下打开终端,执行下述指令。便会在labels文件夹下生成每一张图像的
python --version
python voc_labels.py
至此,数据集的准备便已完成。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
前期的准备工作和yolo v3中是一样的。
需要修改的配置文件有voc.data、voc.names、 yolov3-tiny.cfg文件
- voc.names中修改训练数据集中包含有哪些类标签,一行一类标签;这里改为了face
- voc.data中修改类别的数量;voc_labels.py生成的txt的路径,包括训练和验证两部分;其余两项一般不需要修改,默认的就可以。详情如下:
1 classes = 1 2 train = /home/vtstar/yolo/darknet/2019_train.txt 3 valid = /home/vtstar/yolo/darknet/2019_val.txt 4 names = data/voc.names 5 backup = backup
-
yolov3-tiny.cfg中需要修改内容如下:
- [net]下 batch 和subdivisions参数(根据PC的性能)
- [convolutional]([yolo]层的前一层),fitters的数量,根据类别的数量进行修改(5+class_num)*3
- [yolo] anchors修改为K-Means生成的锚框(采用默认的也可以);classes数量
Makefile文件除了修改GPU,CUDNN,OPENCV的配置参数外,还需要根据电脑的配置,修改一些关于nvcc的参数。
下载yolo v3-tiny的权重测试:
wget https://pjreddie.com/media/files/yolov3_tiny.weights
下载卷积层的权重
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.13 13
模型训练
1 ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15 -gpus 0,1
gpus后的0,1,2,...根据服务器中GPU的数量选择。
初始锚框的生成:(win10) 用于修改yolov3-tiny中的锚框信息
使用keras版本的K-Means生成人脸检测的锚框宽高:
6,8, 10,13, 15,19, 24,30, 42,54, 106,140
重复了十几次,选择了精度最高的一组(72.98%)
初始锚框生成的步骤:
使用Keras版本的darknet源码中的voc_annotation.py文件放置到下载的数据集中,修改一些文件的路径:
1 in_file = open('xml/train_xml/%s.xml' % image_id) 2 ... 3 image_ids = open('xml/%s.txt' % image_set).read().strip().split() 4 list_file = open('%s.txt' % image_set, 'w') 5 ... 6 list_file.write('%s/xJPEG/%s.jpg'%(wd, image_id))
voc_annotation.py 代码如下所示,可对应上述需要改动的内容。该程序的执行实际上不需要将xml文件、图像文件放置在标准的文件夹下。
下述代码主要的作用是将图像的路径+名称.jpg 和 xml文件中标注框的信息写到txt中。需要的文件:
1. 没有后缀的图像名称,也就是上述给Main文件夹中放置的txt。
2. 不需要图像文件,但需要图像的路径,用于写到txt中,第三行的2007没有用,trian将作为生成的txt的名称。【标注文件中图片的路径不能作为写到txt的路径,标注文中总如果包含中文路径,则in_file=open()中需要添加encoding= "utf-8" , 否则会报错,默认gbk】
1 import xml.etree.ElementTree as ET 2 from os import getcwd 3 sets = [('2007', 'train')] 4 5 classes = ["face"] # 不需要使用 6 def convert_annotation(year, image_id, list_file): # 将xml转化为txt 7 in_file = open('xml/train_xml/%s.xml' % image_id) # xml的地址,需要图像名称作为xml名称(二者名称是一致的) 8 tree=ET.parse(in_file) # 此处,如果在标注时,存储地址包含中文路径,会报错,需要将上一行代码添加encoding="utf-8" 9 root = tree.getroot() 10 11 for obj in root.iter('object'): 12 difficult = obj.find('difficult').text 13 cls = obj.find('name').text 14 if cls not in classes or int(difficult)==1: 15 continue 16 cls_id = classes.index(cls) 17 xmlbox = obj.find('bndbox') 18 b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text)) 19 list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id)) 20 21 wd = getcwd() 22 23 for year, image_set in sets: 24 image_ids = open('xml/%s.txt' % image_set).read().strip().split() # 只包含图像名称的txt, 也是给Main文件夹中的txt 25 list_file = open('%s.txt' % image_set, 'w') # 要生成txt文件的路径,名称这里使用了第3行代码中的train 26 for image_id in image_ids: 27 list_file.write('%s/xJPEG/%s.jpg'%(wd, image_id)) # 修改图像所在的路径,当然实际上不需要图像,只是把路径当做字符串写到txt中 28 convert_annotation(year, image_id, list_file) 29 list_file.write(' ') 30 list_file.close()
通过文件,便可以生成python中的train.txt的模式(即路径+框信息),如下图所示:

然后将生成train.txt放置到K-Means.py文件夹中,修改K-Means中的一些路径,如下图所示:

在这里,我们将train.txt的名称修改为train_2019.txt,避免和之前文件的重合。由于在yolo v3-tiny中进行训练,网络中只包含两个尺度的输出,相应锚框的数量为6,所以在此处聚类个数修改为6.
至此训练前的修改完成,可以在终端下通过命令进行训练。
对于缺陷检测、海底物体识别、无人机识别、字符识别等都可以通过这样的方式进行操作。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参数调优
更深度了解配置文件的参数:

subdivision可以减轻显卡的压力。
训练过程中出现nan的现象:
- 如果运行中出现了nan, 是正常现象;
- 但如果全部都是nan的话,这就是训练过程出了问题
一般而言,出现nan 是梯度爆炸、分母为0、log取到0或负值的情况。
改小batch/增大subdivisions,或者关闭多尺度训练random = 0. random设置为1,会增加检测的精度。
Makefile中arch架构与自己显卡架构不匹配
多GPU训练有可能会出现训练开始一段时间后 loss = nan、 IOU=nan,其他参数全为0的情况。
确保cfg文件是train模式时,batch、subdivisions不全为1
增加input图像的尺寸,例如在.cfg文件中设置(height=608,width=608)以上(看之前uav的配置文件 确实有608的设置),可以增加检测的精度。
random=1,可以增加模型精度。
训练中参数的意义

- 迭代次数
- 总体的Loss损失
- 平均的loss损失,期望该值越小越好,一般来说当这个数值低于0.060730 avg就可以终止训练了。
- 当前的学习率,是在.cfg文件中设定的
- 当前批次训练花费的总时长
- 这个数值是9798*64的大小,表示到目前为止,参与训练的图片的总量

(1) Region Avg IOU:平均的IOU,代表着预测的Bounding Box和Ground truth的交集与并集之比,(batch/subdivision)期望该值趋近于1。
(2) Class:是标注物体的概率,期望该值趋近于1。
(3) Obj:期望该值趋近于1。
(4) No Obj:期望该值越来越小,但不为0。
(5) AvgRecall:期望该值趋近于1,召回率比较高说明效果较好
包含.5R和.75R,分别表示IOU取0.5和0.75时模型的召回率;
(6) count表示输出有多少个目标总和

这里的region 16和23 表示yolo v3-tiny 中两个尺度的输出,16卷积层为最大尺度的输出,使用较大的mask,适合预测较小的物体;23卷积层为最小尺度的输出,使用较小的mask,适合预测较大的物体。