论文题目:EfficientDet: Scalable and Efficient Object Detection
文献地址:https://arxiv.org/pdf/1911.09070v1.pdf
(非官方)源码地址:
(1) Pytorch版:https://github.com/toandaominh1997/EfficientDet.Pytorch
(2) Keras&&TensorFlow版:https://github.com/xuannianz/EfficientDet
官方源码地址:https://github.com/google/automl
在机器视觉领域,模型效率的重要性越来越高。近日,谷歌大脑团队系统性的选择了目标检测神经网络结构的设计,并提出了能够提升模型效率的几项关键优化。首先,提出了一种加权的双向特征金字塔(weighted bi-directional feature pyramid network, BiRPN),可以轻松,快速的实现多尺度特征融合。其次,提出了一种复合缩放(compound scaling)的方法,该方法可以对所有的主干网络(back bone)、特征网络、边界框/类别预测网络的分辨率、深度、宽度进行统一缩放。基于这些优化,提出了新型的目标检测器EfficientDet,在广泛的资源限制范围内,EfficientDet始终比现有模型的效率高一个数量级。具体来说,在COCO数据集上,EfficientDet-D7仅使用了52M参数和326B FLOPS,并且获得了最优的51.0mAP。 准确率比现有最好的检测器+0.3% mAP。
EfficientDet在COCO数据集上的效果
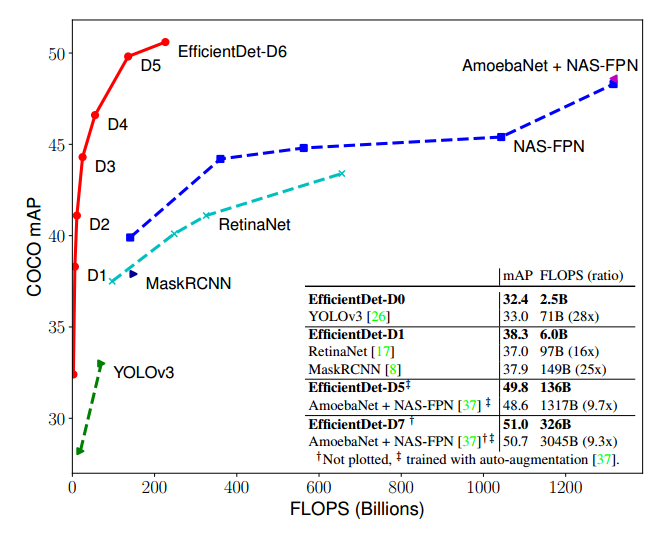
作者为不同资源受限的设备(from 3B to 300B FLOPS)设计了一个可伸缩的模型,如下图所示,EfficientDet-D0到EfficientDet-D6,与YOLOv3、MaskRCNN、NAS-FPN等模型的对比,在准确率和运算量上EfficientDet均是一枝独秀。
一般而言,one-stage的检测器,诸如YOLO,SSD等,检测速度快,实时性好,但检测准确性不如Mask-RCNN,RetinaNet等two-stage的检测器。但从下图中可以看到,EfficientDet在FLOPS和mAP之间进行了很好突破,是目前既准确又快速的检测器。
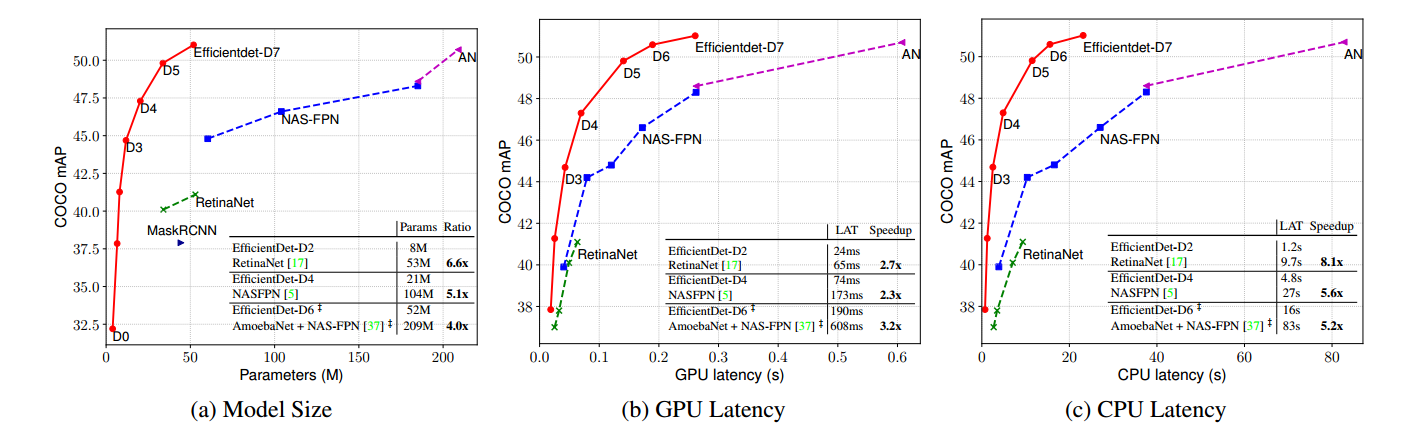
作者还在模型尺寸(参数量)、GPU延迟、CPU延迟三个方面与现有模型在准确率上进行对比,如下图所示,无论在哪一方面,EfficientDet(D0-D6)的结果相对于其他模型都处于在非劣解前沿的位置。
目标检测的现状
近年来,目标检测在结果取得更精确的方向上取得了大量进展。然而,先进的目标检测器的成本也变得越来越高。例如,近期提出的基于AmoebaNet的NAS-FPN检测器包含167M的参数量和3045 B的FLOPS(是RetainNet的30倍),在这样高昂的成本下才获得了目前最优的准确率。大规模尺度和昂贵的计算成本都会由于延迟和资源受限等原因,限制这些算法模型在现实世界中的应用,例如机器人和自动驾驶。由于现实世界资源受限的问题,考虑目标检测模型的效率的重要性正在与日俱增。
在此之前已经有许多致力于开发更高效的检测器结构的研究成果,例如一些one-stage模型(SSD/ YOLOv3/YOLO9000. etc),不需要锚框(anchor-free)的检测器(CornerNet.etc),或者压缩现有模型(YOLO-Lite.etc)。尽管这样的方法会实现更好的效率,但通常是以牺牲精度为代价的。并且,以往的研究大多都关注于某个特定的资源需求条件下,从移动设备到数据中心,经常会有不同的资源限制。
那么,一个自然而然的问题是:构建一个同时具有高精度、高效率的可扩展检测架构,以应对不同的资源约束(3B to 300B FLOPS)是否可行?
作者基于one-stage检测器的范例,对主干网络、特征融合方式、边界框/类别预测网络等几个方面的设计进行选择,发现两大挑战:
Challenge 1: 高效的多尺度特征融合。关于不同输入特征的融合,之前的大多数研究都是不进行区分,简单的汇总加和起来。然而,这些不同的输入特征往往是不来自于不同分辨率下的,它们对于输出特征的贡献程度应该是不相等的。
基于此,作者提出了一种简单而高效的加权双向特征金字塔网络BiFPN,该模型引入了可学习的权重,用于学习不同输入特征的重要性,同时重复使用自下而上(bottom-up)和自上而下(top-down)的多尺度特征融合。 ---- 引入权重的思想与SENet有些像。
Challenge 2:模型缩放。为了获得高准确率,之前的研究主要依赖于比较大的主干网络(back bone network)和尺寸较大的输入图像。作者注意到,考虑到准确性和效率,扩展特征网络和边界框/类预测网络也很关键。
基于此,作者对于目标检测的问题提出了一种混合缩放的方法,该方法可以对网络主干backbone 、特征网络、边界框/类别预测网络的分辨率、深度、宽度进行统一缩放。
最后,作者还发现最近提出的文献EfficientNet相较于之前普遍使用的ResNets、ResNetXt和AmoebaNet等主干结构更加高效。因此,作者将提出的BiFPN和混合缩放与EfficientNet结构相结合,命名为EfficientDet。
网络结构的改进
作者首次将多尺度融合的问题公式化,然后提出了BiFPN提出的两种思路:
- 有效的双向跨尺度连接
- 加权特征融合
1. FPN公式化
多尺度特征融合意在将不同分辨率下的特征进行聚合。对于一系列不同尺度的特征:
![]()
l1,l2,...,li 表示不同的层级,即模型网络的不同深度。随着层级i的加深,特征的分辨率通常以1/2^i的速率减少。例如,输入一个640*640分辨率的特征,经过三次转化,分辨率会降维640/2^3=80(80*80的分辨率)。多尺度特征融合的目标就是找到一个可以有效的将一些列不同尺度的特征转化为一个输出的 变换,如下所示:
![]()
如下图所示,左图为传统的FPN,其仅包含自上而下的特征融合(如下图a所示)。可以联想YOLO v3的的网络结构(如下图右侧所示),13*13分辨率的特征通过上采样与26*26分辨率的特征进行融合,26*26分辨率的特征通过上采样与52*52分辨率的特征融合。可以看出,融合的过程仅包括从低分辨率到高分辨率的融合,即从网络深的特征到网络浅的特征融合,也就是论文中描述的top-down模式。

自上而下模式特征融合的FPN可以公式化为如下形式,其中Resize通常为上采样(或降采样)的操作,用于分辨率的匹配;Conv为常规的卷积操作。"+"表示特征在channel上的堆叠。

2. 跨尺度连接(Cross-Scale Connections)
传统的自上而下的FPN在本质上受到单向信息流的限制。PANet添加了一条自下而上的途径,如下左图所示;NAS-FPN利用神经网络结构搜索,寻找不规则的跨尺度特征网络拓扑,如下右图所示。
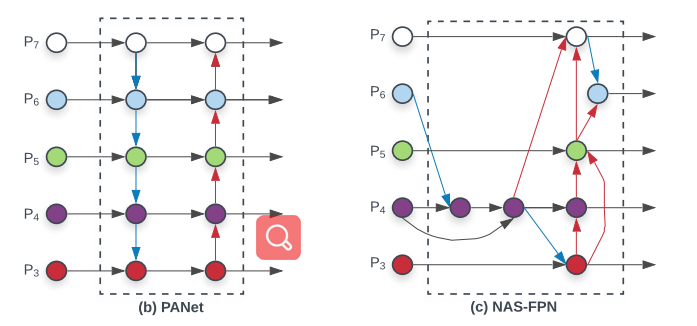
为了提高模型的表现的效率,谷歌大脑研究团队针对跨尺度连接结构提出了一些优化:
- 首先,将仅具有一个输入的节点移除,其灵感比较简单,一个节点如果仅包含一个输入,并没有进行特征融合,那么它对于特征网络的贡献是极小的。这样可以生成一个简化的PANet (Sim ple PANet),如下图左侧所示,相较于PANet,可以很明显的看出省略了仅有一个输入的节点。
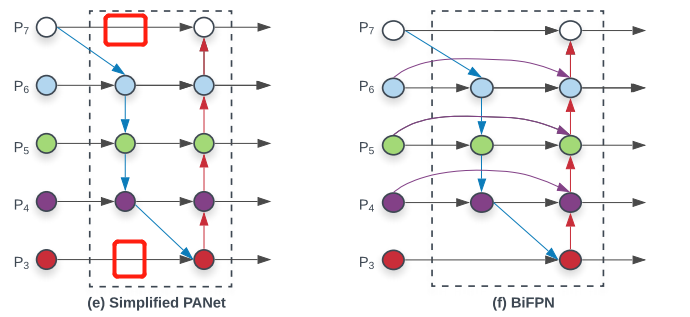
- 其次,针对同一层级,添加了一条从起始输入到输出的连接,如上图右侧紫色连线。这样可以在不增加任何参数的同时,融合更多特征。
- 最后,与只有一条自上而下和自下而上路径的 PANet 不同,研究者将每个双向路径(自上而下和自下而上)作为一个特征网络层,并多次重复同一个层,以实现更高级的特征融合。形成最终的BiFPN。
3. 加权特征融合
融合多个不同分辨率特征的常规方式是先将分辨率调整一致,再对其进行加和或者堆叠。金字塔注意力网络(pyramid attention network)引入了全局自注意力上采样来恢复像素定位。
之前的特征融合思想对于输入的不同特征一视同仁,然而不同分辨率的特征对于输出特征的贡献是不同的。为解决该问题,研究者提出在特征融合过程中为每一个输入添加额外的权重,再让网络学习每个输入特征的重要性。
最后一届ImageNet的冠军SENet,也意识到了这样的问题,下图为SE-block的结构,通过全连接的方式,让网络学习每个尺度特征的贡献度:
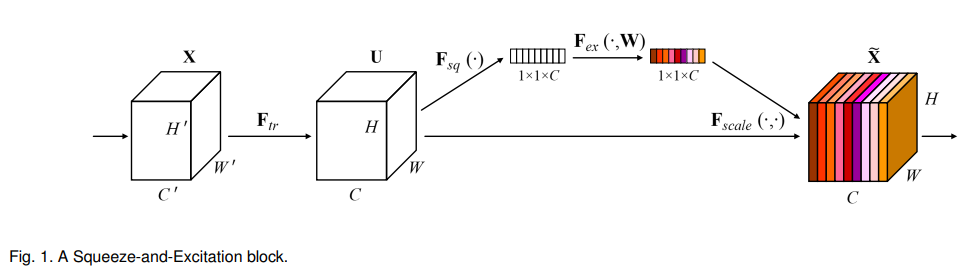
作者提出了三种加权融合的方式:
- Unbounded fusion:
![]()
其中,wi是学习的权重,这个权重可以是针对每个feature的(per-feature),也可以是针对通道的(per-channel),还可以是针对像素的(per-pixel)。由于权值不受限,会造成训练的不稳定。因此,采用权值归一化的方式限定每个权重的范围。
- softmax-based fusion:
![]()
这种方式实际上也是通过softmax的方式对权重值的范围进行限定。但是,softmax的操作对硬件GPU不是很友好,会降低运算速度(yolov3中都不使用softmax做分类)。
- Fast normalized fusion:
![]()
这种方式在某种程度上是为了避免softmax操作的资源消耗。权重wi都使用ReLu激活函数,以保证wi≥0。避免数值的不稳定,采用一个很小的值ε = 0.0001。同样,经过这样的处理,最终的加权值将会归一化到0到1。对于BiFPN的结构,加权操作如下式所示:

其中,P6td表示P6级的中间节点的输出特征。作者为了提升效率,使用深度可分离卷积(Mobile Net)减少参数量和运算量。
从下表中可以看出,使用BiFPN的EfficientNet-B3要比使用FPN在准确度上提高了4个点,参数量和运算量也极大缩小。

EfficientDet
1. 网络结构
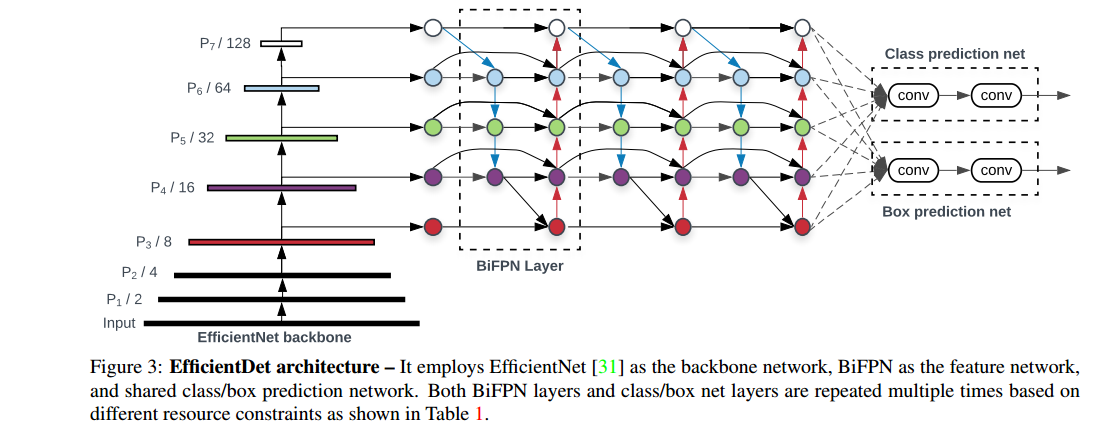
下图显示了EfficientDet网络结构,大致采用了one-stage检测器的范例。采用EfficientNet作为网络的backbone;BiFPN作为特征网络;将从backbone网络出来的特征{P3,P4,P5,P6,P7}反复使用BiFPN进行自上而下和自下而上的特征融合。反复使用的特征通过class prediction net和box prediction net 对检测类别和检测框分别进行预测。
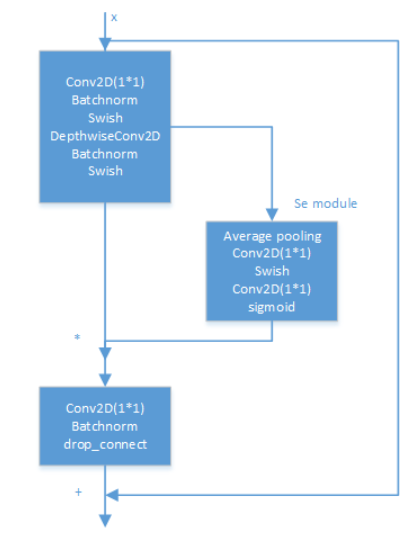
EfficientNet - B0结构:

其中,MBConv为取反的bootlenet单元,即mobilev2的瓶颈单元,并将shortcut部分改为SE-block。
2. 复合缩放
为了优化准确性和效率,作者想要开发一系列的模型来满足广泛的资源约束。
以前的工作主要是通过使用更大的主干网络来扩展基线检测器(e.g. ResNeXt),使用较大的输入图片或者堆叠更多的FPN层。这样的做法往往不够高效。
研究者提出一种目标检测复合缩放方法,它使用简单的复合系数 φ 统一扩大主干网络、BiFPN 网络、边界框/类别预测网络的所有维度。

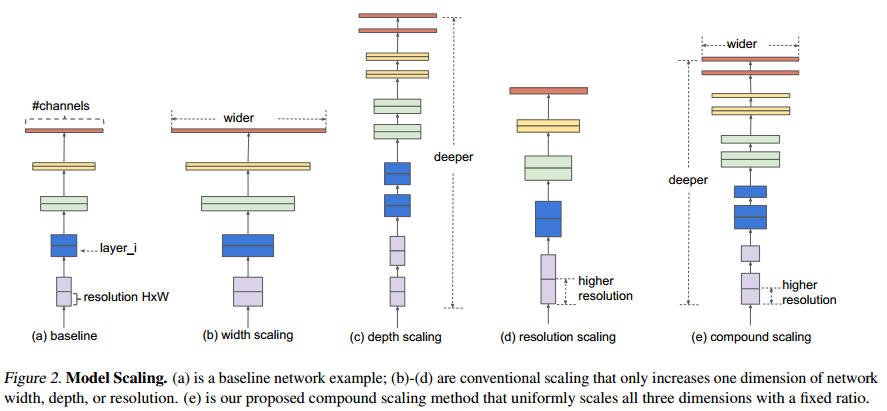
如果没有研读过EfficientNet,将会很难理解复合缩放的含义。对EfficientNet的思想进行简要描述。
下图为模型缩放的示意图,其中图a描述了一个基础的网络结构,图b-图d为分别对网络宽度、网络深度、分辨率进行扩大。图e为对网络宽度、深度、分辨率统一扩大。
对于一个卷积层,其操作可以定义为一个函数:
![]()
其中,F表示卷积操作,Yi是输出张量,Xi为输入张量。
那么,一个ConvNet N就可以表示为一个递归的操作:

卷积神经网络N可以定义为(考虑Inception的存在)
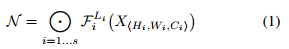
Fi^Li:表示第i层卷积操作重复的次数。【Inception 操作,在一层会进行多次卷积操作】
H:表示输入特征高度
W:表示输入特征宽度
C: 表示输入特征通道数量
X: 表示输入张量
因此,在运算量、资源受限的环境下,一个优化问题可以定义为:

简单来说,就是在运算量、资源允许的情况下,通过优化网络深度d,宽度w,分辨率r,使得准确度最大的优化问题。
对于一个优化问题,需要限制优化变量的取值范围,否则优化的搜索空间过大,难以寻到最优。因此,设定一个变量准则,如下所示。

其中,α,β,γ为常量;φ为用户定义的尺度变化参数;
将网络的深度d加倍,将会使得计算量变为原来的2倍,将网络的通道宽度w和分辨率r加倍将会使得计算量变为原来的4倍。因此,设置α · β^2 · γ^2 ≈ 2,最终的计算量FLOAPS数目为2φ。