论文题目: Searching for MobileNetV3
文献地址:https://arxiv.org/pdf/1905.02244v5.pdf
源码地址:
(1)PyTorch实现1:https://github.com/xiaolai-sqlai/mobilenetv3
(2)PyTorch实现2:https://github.com/kuan-wang/pytorch-mobilenet-v3
(3)PyTorch实现3:https://github.com/leaderj1001/MobileNetV3-Pytorch
(4)TensorFlow实现1:https://github.com/Bisonai/mobilenetv3-tensorflow (推荐)
(5)TensorFlow实现2:https://github.com/tensorflow/models/tree/master/research/object_detection
MobileNet V3实验结果

作者在classification、detection、segmentation三个方面测试验证了MobileNet V3的性能。
1. classification
ImageNet分类实验结果:
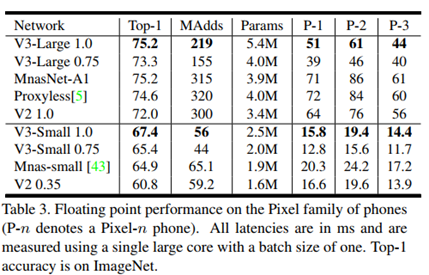
与V2对比
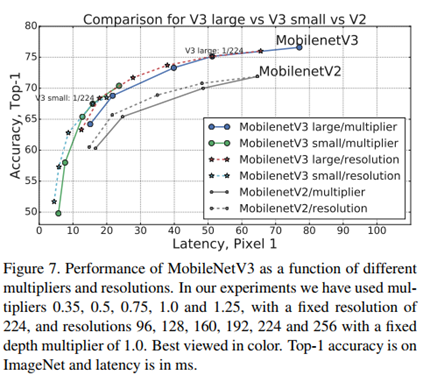
2. detection
SSDLite(COCO数据集)目标检测结果

3. segementation
用于语义分割的轻量级的head:
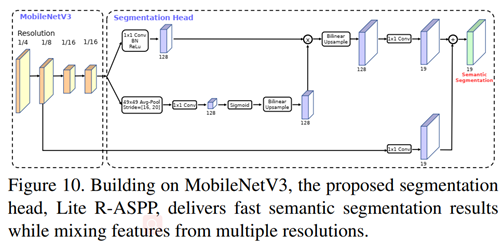
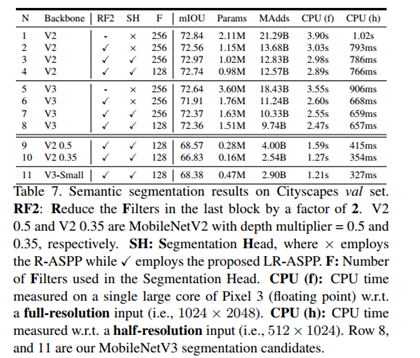
Cityscapes数据集语义分割结果
移动端神经网络现状
高效的神经网络在移动应用程序中变得无处不在,使全新的设备体验成为可能。它们也是个人隐私的关键推动者,允许用户获得神经网络的好处,而不需要将数据发送到服务器进行评估。神经网络高效的发展,不仅由于高精度和低延迟提升了用户的体验,而且有助于通过降低功耗来保护电池的寿命。
从SqueezeNet大量使用1*1卷积进行压缩-扩张模型起,开始关注于模型参数量的减少。而最近的工作将聚焦点从减少模型的参数量转换到了减少模型的计算量(MAdds)。MobileNetV1利用深度可分离卷积提高了卷积的计算效率;MobileNetV2加入了线性bottlenecks和反向残差模块构成了高效的模块;ShuffleNet利用组卷积和通道洗牌操作进一步较少了计算量;CondenseNet在训练阶段学习组卷积,以保持层之间有用的密集连接,以便特性重用;ShiftNet利用shift操作和逐点卷积代替了昂贵的空间卷积。

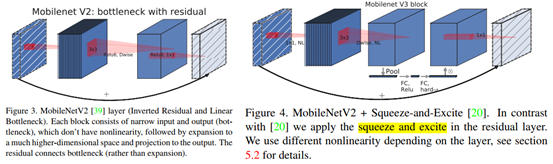
上图中,左图为MobileNet V2的网络块结构;右图为MobileNet V3的网络块结构。可以看出,MobileNet V3中结合了三种思想:
1. MobileNet V1: 深度可分离卷积(depthwise separable convolutions)
2. MobileNet V2: 具有瓶颈的反向残差结构(the inverted residual with linear bottleneck)
3. MnasNet : 基于Squeeze and excitation 结构的轻量级注意力模型 (源于SENet),相当于在feature map 的每一通道上乘以对应的缩放因子。下图是SE Block的结构示意图。

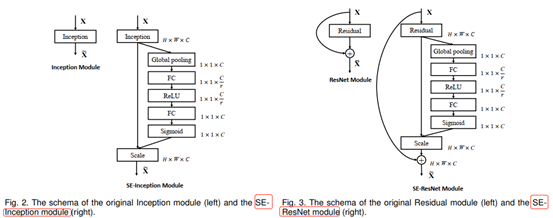
上图中,左图是SE Block与Inception结构相结合;右图是SE Block与ResNet结构相结合。当然其还可以和ResXNet结合。
论文贡献
1. 使用硬件感知网络架构搜索(hardware-aware network architecture search, NAS)与NetAdapt算法相结合自动搜索网络结构;NAS执行模块级搜索,NetAdapt执行层级搜索(局部搜索)。
2. 网络结构改进:将最后一步的平均池化层前移并移除最后一个卷积层,引入h-swish激活函数。
网络搜索
1. 基于模块级搜索Block-wise Search: NAS
通过优化每一个网络模块来搜索全局网络结构。
与MnasNet思路一样,首先通过一种平台感知的神经结构方法来寻找全局网络结构。并且,也使用了基于RNN的控制器和想通过的分级搜索空间。并且复用了MnasNet-A1,并在该模型的基础上使用了NetAdapt。此处的多目标函数的设定与MnasNet中一致(如下式所示)。作者在这里使用w = -0.15代替了MnasNet中w=-0.07,可以为不同的延迟补偿较大精度的改变。可以理解为当w值变大,不同延迟作用到ACC上,对于目标函数的影响更大(即分母大于1 与小于1的情况讨论)。
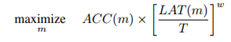
作者使用新的权重因子w重新搜索新的网络架构,并利用NetAdapt和其他优化方式获得最终的MobileNetV3-small模型。
2. 基于层级搜索Layer-wise Search: NetAdapt
搜索每一层卷积核的个数,相当于对确定的各个模块的每一层进行微调的工作。可以作为NAS的互补。
过程大致如下:

NetAdapt选择△ACC / |△latency| 最大的建议。
网络提升
除了网络搜索,还为模型引入了新的组件:
1. 在模型网络的开始和结尾开销大的层进行重新设计;这些修改是超出搜索空间的,也就是说,这部分的修改应该不是自动完成的。

MobileNetV2模型中使用反向残差结构,利用1*1卷积将feature map恢复到高维的空间,虽然有利于丰富特征并进行预测,但却引入了额外的计算开销和延迟。作者选择移除平均池化Avg-Pool前的层,并使用1*1卷积计算计算特征图,会减少7ms的开销,减少30百万的运算量。值得庆幸的是没有精度的损失。
MobileNetV2模型中反向残差结构和变体利用1*1卷积来构建最后层,以便于拓展到高维特征空间。虽然对于提取丰富特征进行预测十分重要,但却引入了额外的计算开销与延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少10ms的开销,在提速15%的同时减小了30m的操作数。
另一个开销较大层是最初的卷积核,当前使用的是32个3*3卷积,作者通过选择不同的激活函数和减少卷积核的个数方式降低模型的冗余。选择hard swish激活函数,并且减少卷积核个数到16,这又节省了2毫秒和1000万madd
2. 引入了一个新的非线性激活函数h-swish。
作者发现swish激活函数可以显著提高神经网络的准确性,可作为ReLU的替代,swish激活函数如下所示:
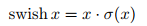
但swish激活函数中的sigmoid运算再移动端会消耗较多的计算资源。因此,作者提出了h-swish激活函数。使用ReLU6代替sigmoid运算:
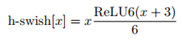
h-swish函数曲线如下图所示。

MobileNet V3网络(自动生成)
MobileNetV3包含high resource 和 low resource两种场景的模型,具体结构如下所示,MobileNet V3 -Large 和 MobileNet V3 - small,其中,SE是SENet提出的一种结构squeeze and excitation;HS表示h-swish,RE表示ReLU 。

总结
MobileNet V3与MnasNet一样,都是自动优化生成的模型,在得知网络结构后,将其应用在某移动设备难度并不大,值得了解的是如何在指定的移动设备上进行网络结构的生成。这一过程将会在一定程度上实现移动设备资源的高效利用。