内容来自网络:
https://www.cnblogs.com/luxiaojun/p/6567132.html
在平常的工作中几乎有一半的功能模块都需要定时任务来推动,例如项目中有一个定时统计程序,定时爬出网站的URL程序,定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题,第一时间想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然这样也可以,但是总觉得不是那么的专业,^_^所以就找到了python的定时任务模块APScheduler:
APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个python定时任务系统。
Apscheduler
Apscheduler基于Quartz的一个python定时任务框架,实现Quart的所有功能,相关的接口调用起来比较方便,目前其提供了基于日期、固定时间间隔以及corntab类型的任务,并且同时可进行持久化任务;同时它提供了多种不同的调用器,方便开发者根据自己的需求进行使用,也方便与数据库等第三方的外部持久化储存机制进行协同工作,非常强大。
基本原理
总的来说,主要是利用python threading Event和Lock锁来写的。scheduler在主循环(main_loop)中,反复检查是否有需要执行的任务,完成任务的检查函数为 _process_jobs,主要有那个几个步骤:
1、询问储存的每个 jobStore,是否有到期要执行的任务。

2、due_jobs不为空,则计算这些jobs中每个job需要运行的时间点,时间一到就提交给submit作任务调度。
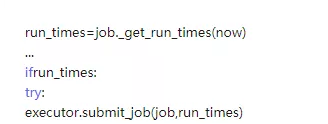
3、在主循环中,如果不间断地调用,而实际上没有要执行的job,这会造成资源浪费。因此在程序中,如果每次掉用 _process_jobs后,进行了预先判断,判断下一次要执行的job(离现在最近的)还要多长时间,作为返回值告诉main_loop, 这时主循环就可以去睡一觉,等大约这么长时间后再唤醒,执行下一次 _process_jobs。
安装
1、可以直接使用pip进行安装
pip install apscheduler
2、源码安装
(https://pypi.python.org/pypi/APScheduler/)
可以到官网下载包,然后执行命令安装 python setup.py install
### 基础概念
在Apscheduler中主要有以下几个非常重要的概念,主要如下:
-
触发器(trigger):
某一个工作到来时引发的事件,包含调度的逻辑,每一个作业都有它自己的触发器,用于决定哪个作业任务会执行,除了它们初始化配置之外,其完全是无状态的。总的来说就是一个任务应该在什么时候执行
-
执行器(executor):
主要是处理作业的运行,它将要执行的作业放在新的线程或者线程池中运行。执行完毕之后,再通知调度器。基于线程池的操作,可以针对不同类型的作业任务,更为高效的使用CPU的计算资源。
-
作业存储(job stores)
保存要调度的任务,其中除了默认的作业存储是把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据将在保存在持久化的作业存储之前,会对作业执行序列化操作,当重新读取作业时,再执行反序列化操作。同时,调度器不能分享同一个作业存储。作业存储支持主流的存储机制:如redis,mongodb,关系型数据库,内存等等。
-
调度器(scheduler):
负责将上面几个组件联系在一起,一般在应用中只有一个调度器,程序开发者不会直接操作触发器、作业存储或执行器,而是利用调度器提供了处理这些合适的接口,作业存储和执行器的配置都是通过在调度器中完成的。
在我们的使用过程中,选择合适的调度器是根据我们的开发环境以及实际应用来决定的,根据IO模型的不同,主要有下面一些常见的调度器:
-
BlockingScheduler:适合于只在进程中运行单个任务的情况
-
BackgroundScheduler: 适合于不运行使用其他框架时,并希望在程序后台执行的情况
-
AsyncIOScheduler:适合于使用asyncio框架的情况
-
GeventScheduler: 适合于使用gevent框架的情况
-
TornadoScheduler: 适合于使用Tornado框架的应用
-
TwistedScheduler: 适合使用Twisted框架的应用
-
QtScheduler: 适合使用QT的情况
而对于作业存储,如果是非持久性作业,使用默认的MemoryStore就行了,若是持久性任务,那么就需要根据应用环境来进行选择。
大多数情况下,执行器选择ThreadPoolExecutor就够用了,但如果涉及到比较消耗CPU的作业,就可以选择ProcessPoolExecutor* ,以充分利用多核CPU。当然也可以同时配置使用两个执行器,将进程池ProcessPoolExecutor调度器作为你的第二个执行器。
配置调度器
Apscheduler框架提供了许多调度器的配置方法,既可以使用配置字典,也可以直接传递配置参数给调度器使用; 同时支持先初始化调度器,添加完作业任务后,再来配置调度器等。
说了这么多,我们可以来先举个简单的例子:

上面的代码生成一个默认的调度器,默认使用名为 default 的 MemoryJobStore,以及使用默认名为 default 的 ThreadPoolExecutor ,最大线程数为10 。
下面进行一个复杂的配置,同时使用两个作业存储和两个执行器,在这个配置中,修改默认的配置参数,jobstored指的是job持久化,默认job运行在内存中,可持久化在数据库,指定为mongo的MongoDBJobStore或者是使用sqlite的SQLAlchemyJobStore,同时可指定多种jobstore。
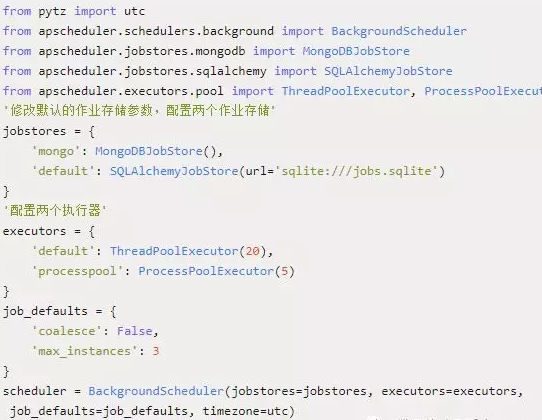
-
coalesce:当由于某种原因导致某个job积攒了好几次没有实际运行(比如说系统挂了5分钟后恢复,有一个任务是每分钟跑一次的,按道理说这5分钟内本来是“计划”运行5次的,但实际没有执行),如果coalesce为True,下次这个job被submit给executor时,只会执行1次,也就是最后这次,如果为False,那么会执行5次(不一定,因为还有其他条件,看后面misfiregracetime的解释)。 -
max_instance:每个job在同一时刻能够运行的最大实例数,默认情况下为1个,可以指定为更大值,这样即使上个job还没运行完同一个job又被调度的话也能够再开一个线程执行。 -
misfire_grace_time:单位为秒,假设有这么一种情况,当某一job被调度时刚好线程池都被占满,调度器会选择将该job排队不运行,misfiregracetime参数则是在线程池有可用线程时会比对该job的应调度时间跟当前时间的差值,如果差值<misfiregracetime时,调度器会再次调度该job.反之该job的执行状态为EVENTJOBMISSED了,即错过运行.</misfire。
启动/关闭调度器
使用 start() 方法来启动调度器,其中须注意的是 BlockingScheduler 需要在初始化之后才能执行 start() ,对于其他的调度器,调用 start() 方法都会直接返回,然后可以继续执行后面的初始化操作。同时,调度器启动之后,就不能再更改它的配置了。
在默认情况下,调度器会等所有的作业任务完成后,自动关闭所有的调度器及作业存储。若在使用过程中不想等待,可以将 wait参数选项设为 False,则表示直接关闭
sched.shutdown()
sched.shutdown(wait=False)
调度器监听事件
可以给调度器添加事件监听器,调度器事件只有在某些情况下才会被触发,并且可以携带某些有用的信息。通过给 add_listener()传递合适的 mask参数,可以只监听几种特定的事件类型,具体类型可看源码中的 event.exception或者 event.code值来做识别判断。

作业及作业存储
jobstore提供给scheduler一个序列化jobs的统一抽象,提供对scheduler中job的增删改查接口,根据存储backend的不同,分以下几种:
-
MemoryJobStore:没有序列化,jobs就存在内存里,增删改查也都是在内存中操作 -
SQLAlchemyJobStore:所有sqlalchemy支持的数据库都可以做为backend,增删改查操作转化为对应backend的sql语句 -
MongoDBJobStore:用mongodb作backend -
RedisJobStore: 用redis作backend
Job是框架承接目前需要执行的工作和任务,我们可以在系统运行过程中进行动态的增加、修改、删除、查询等操作。
1、添加作业
上面是通过 add_job() 来添加作业,另外还有一种方式是通过修饰器 scheduled_job来动态装饰 Job 的实际函数
1 import time 2 from apscheduler.schedulers.blocking import BlockingScheduler 3 4 sched = BlockingScheduler() 5 6 @sched.scheduled_job('interval', seconds=5) 7 def my_job(): 8 print time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) 9 10 sched.start()
2、移除作业
1 job = scheduler.add_job(myfunc, 'interval', minutes=2) 2 job.remove() 3 #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效 4 sched.add_job(myfunc, 'interval', minutes=2, id='my_job_id') 5 sched.remove_job('my_job_id')
 3、暂停作业
3、暂停作业

4、恢复作业

5、获取Job列表
获得调度作业的列表,可以使用 get_jobs()来完成,它会返回所有的job实例,同时也可使用 print_jobs()来输出所有格式化的作业列表。也可以利用 get_job(任务ID)获取指定任务的作业列表
1 job = sched.add_job(my_job, 'interval', seconds=2 ,id='123') 2 print sched.get_job(job_id='123') 3 print sched.get_jobs()
作业运行控制(trigger)
add_job()方法的第二个参数是trigger,它管理着作业任务的调度方式,它可以被设置为 data、 interval、 corn三种类别。对于不同的设置类别,对应的参数也有所不同,具体如下:
1、corn 定时调度,即规定在某一时刻执行,使用例子:
(int|str) 表示参数既可以是int类型,也可以是str类型 (datetime | str) 表示参数既可以是datetime类型,也可以是str类型 year (int|str) – 4-digit year -(表示四位数的年份,如2008年) month (int|str) – month (1-12) -(表示取值范围为1-12月) day (int|str) – day of the (1-31) -(表示取值范围为1-31日) week (int|str) – ISO week (1-53) -(格里历2006年12月31日可以写成2006年-W52-7(扩展形式)或2006W527(紧凑形式)) day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) - (表示一周中的第几天,既可以用0-6表示也可以用其英语缩写表示) hour (int|str) – hour (0-23) - (表示取值范围为0-23时) minute (int|str) – minute (0-59) - (表示取值范围为0-59分) second (int|str) – second (0-59) - (表示取值范围为0-59秒) start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) - (表示开始时间) end_date (datetime|str) – latest possible date/time to trigger on (inclusive) - (表示结束时间) timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示时区取值)
参数的取值格式:
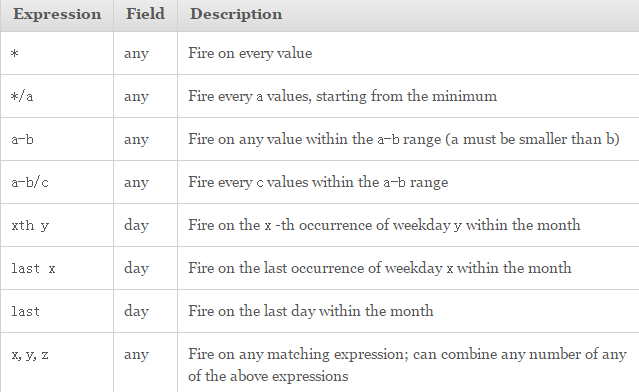
例子:
1 #表示2017年3月22日17时19分07秒执行该程序 2 sched.add_job(my_job, 'cron', year=2017,month = 03,day = 22,hour = 17,minute = 19,second = 07) 3 4 #表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序 5 sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3') 6 7 #表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00 8 sched.add_job(my_job(), 'cron', day_of_week='mon-fri', hour=5, minute=30,end_date='2014-05-30') 9 10 #表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5 11 sched.add_job(my_job, 'cron',second = '*/5')
2、interval间隔调度,即每隔多久执行一次
1 weeks (int) – number of weeks to wait 2 days (int) – number of days to wait 3 hours (int) – number of hours to wait 4 minutes (int) – number of minutes to wait 5 seconds (int) – number of seconds to wait 6 start_date (datetime|str) – starting point for the interval calculation 7 end_date (datetime|str) – latest possible date/time to trigger on 8 timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations
例子:
1 #表示每隔3天17时19分07秒执行一次任务 2 sched.add_job(my_job, 'interval',days = 03,hours = 17,minutes = 19,seconds = 07)
3、data定时调度,即设置后作业只会执行一次,是最基本的调度模式
run_date (datetime|str) – the date/time to run the job at -(任务开始的时间) timezone (datetime.tzinfo|str) – time zone for run_date if it doesn’t have one already
例子:
1 # The job will be executed on November 6th, 2009 2 sched.add_job(my_job, 'date', run_date=date(2009, 11, 6), args=['text']) 3 # The job will be executed on November 6th, 2009 at 16:30:05 4 sched.add_job(my_job, 'date', run_date=datetime(2009, 11, 6, 16, 30, 5), args=['text'])