1.从官网下载安装包,并通过Xftp5上传到机器集群上
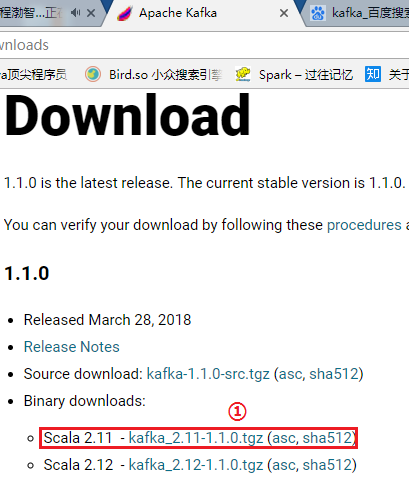
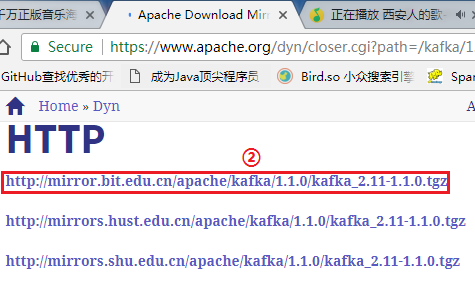
下载kafka_2.11-1.1.0.tgz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:
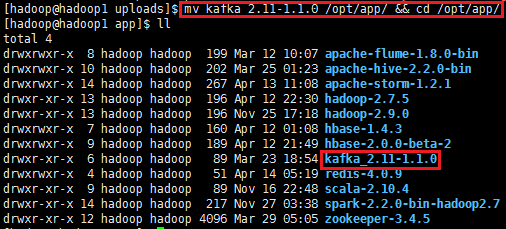
2、解压kafka_2.11-1.1.0.tgz,并把解压的安装包移动到/opt/app/目录上
tar zxvf kafka_2.11-1.1.0.tgz

mv kafka_2.11-1.1.0 /opt/app/ && cd /opt/app/
3、修改环境变量(每台机器都要执行),编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
添加如下内容:
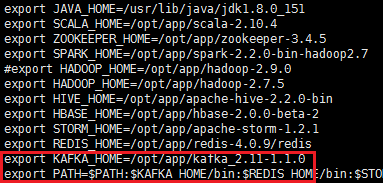
export KAFKA_HOME=/opt/app/kafka_2.11-1.1.0
export PATH=:PATH:PATH:KAFKA_HOME/bin
使环境变量生效:source /etc/profile
4、zookeeper集群安装搭建
zookeeper可以使用kafka_2.11-1.1.0内置的,也可以从zookeeper官网下载一个安装部署集群,差别不大。
安装部署及配置详情请看https://www.cnblogs.com/swordfall/p/8667409.html 第六节点。
这里独立安装zookeeper,不使用kafka内置的。
5、修改配置文件server.properties
进入kafka配置文件的目录,cd /opt/app/kafka_2.11-1.1.0/config/
修改server.properties文件 vi server.properties,将以下内容写入到server.properties文件中
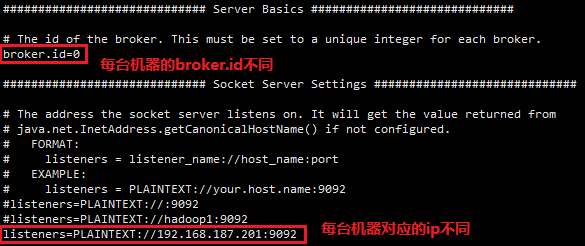
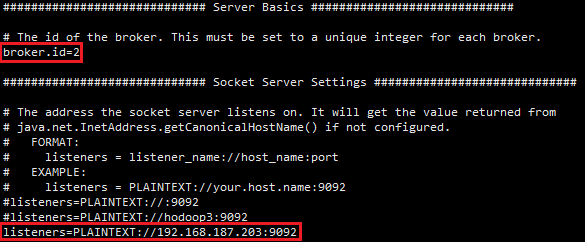
# broker id就是指各台服务器对应的id,所以各台服务器值不同
broker.id=0
# kafka端口号,无需改变
listeners=PLAINTEXT://192.168.187.201:9092
# 日志目录
log.dirs=/opt/app/kafka_2.11-1.1.0/logs
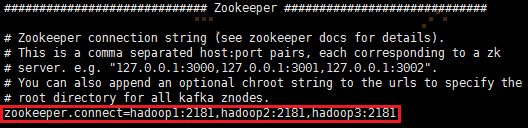
# Zookeeper集群的ip和端口号
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181

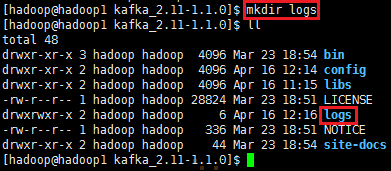
在/opt/app/kafka_2.11-1.1.0/logs目录下创建logs目录,mkdir logs目录
6. 把kafka的安装包发送到其他节点机器hadoop2和hadoop3
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop2:/opt/app/
scp -r /opt/app/kafka_2.11-1.1.0/ hadoop@hadoop3:/opt/app/
然后hadoop2、hadoop3分别重复第3步骤,修改环境变量
7. 分别在hadoop2、hadoop3机器节点上修改broker.id和listeners
hadoop2机器节点上修改kafka的server.properties配置文件

hadoop3机器节点上修改kafka的server.properties配置文件
8. 启动zookeeper和kafka
在每台机器上先分别通过命令zkServer.sh start启动zookeeper,再分别启动kafka为后台进程:
kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties &

或者通过kafka-server-start.sh /opt/app/kafka_2.11-1.1.0/config/server.properties > /dev/null 2>&1 & 启动kafka
注:"> /dev/null" 表示把日志写入/dev/null,"2>&1"表示错误日志和标准输出日志合并写入一个文件,"&"表示后台运行
通过jps命令可以查看到每台机器上是否都启动了zookeeper和kafka
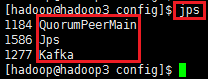
至此kafka集群部署成功。
9. 注意点
kafka安装包根目录下config/server.properties文件如果listeners配置的是hostname主机名,而不是ip,那么需要格外配置一项:
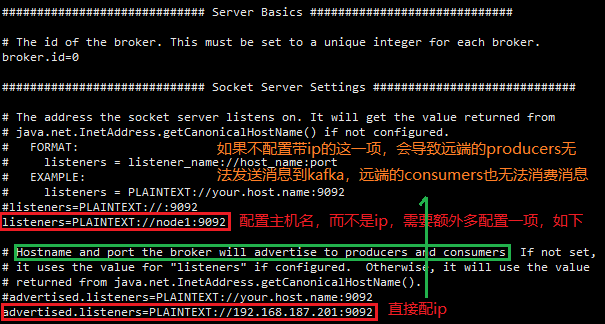
listeners的两种配置方法,可以二选一,一般选第一种。