前面我们介绍了线性情况下的支持向量机,它通过寻找一个线性的超平面来达到对数据进行分类的目的。不过,由于是线性方法,所以对非线性的数据就没有办法处理了。例如图中的两类数据,分别分布为两个圆圈的形状,不论是任何高级的分类器,只要它是线性的,就没法处理,SVM 也不行。因为这样的数据本身就是线性不可分的。
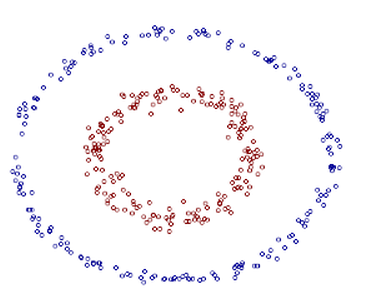
对于这个数据集,我可以悄悄透露一下:我生成它的时候就是用两个半径不同的圆圈加上了少量的噪音得到的,所以,一个理想的分界应该是一个“圆圈”而不是一条线(超平面)。如果用 X1 和 X2 来表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:

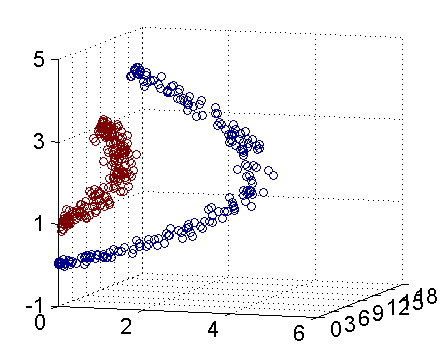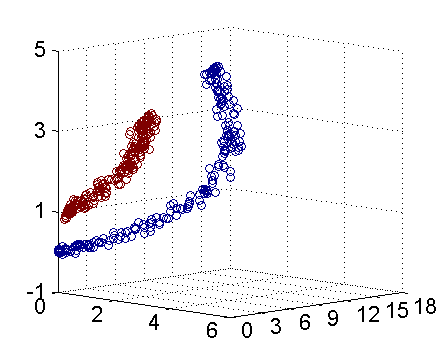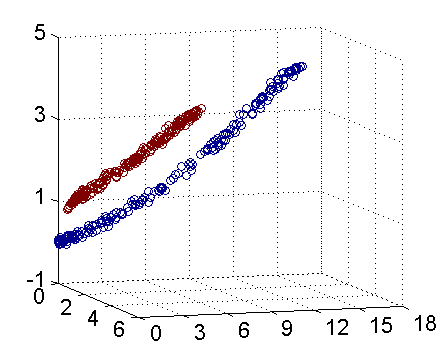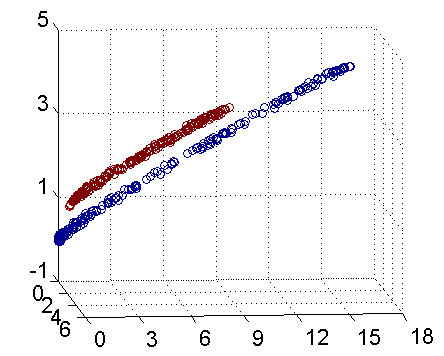
现在让我们再回到 SVM 的情形,假设原始的数据时非线性的,我们通过一个映射 ϕ(⋅) 将其映射到一个高维空间中,数据变得线性可分了,这个时候,我们就可以使用原来的推导来进行计算,只是所有的推导现在是在新的空间,而不是原始空间中进行。当然,推导过程也并不是可以简单地直接类比的,例如,原本我们要求超平面的法向量 w ,但是如果映射之后得到的新空间的维度是无穷维的(确实会出现这样的情况,比如后面会提到的 Gaussian Kernel ),要表示一个无穷维的向量描述起来就比较麻烦。于是我们不妨先忽略过这些细节,直接从最终的结论来分析,回忆一下,我们上一次得到的最终的分类函数是这样的:



最后,总结一下:对于非线性的情况,SVM 的处理方法是选择一个核函数 κ(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。由于核函数的优良品质,这样的非线性扩展在计算量上并没有比原来复杂多少,这一点是非常难得的。当然,这要归功于核方法——除了 SVM 之外,任何将计算表示为数据点的内积的方法,都可以使用核方法进行非线性扩展。
此外,略微提一下,也有不少工作试图自动构造专门针对特定数据的分布结构的核函数,感兴趣的同学可以参考,比如 NIPS 2003 的 Cluster Kernels for Semi-Supervised Learning 和 ICML 2005 的 Beyond the point cloud: from transductive to semisupervised learning 等。