因为最近有获取RSS的需求,所以打算开始研究Huginn
复杂的事情简单化,简单的事情标准化,标准的事情流程化,流程的事情自动化
而huginn扮演的事情就是后三步
最初的素材A(或者是等待烧制RSS的网站,或者是摘要RSS),进入Huginn/工厂,通过一个又一个的Agent/车间流水线,在工厂内存在形态是Event,最终变成了我们想要的成品B(全文RSS)。
搭建
当然是使用docker进行搭建了
docker run -itd --name huginn -p 30033:3000 huginn/huginn
如果要使用外链数据库的话
docker run -d --name=huginn \
-p 3000:3000 \
-e MYSQL_PORT_3306_TCP_ADDR="172.17.0.1" \
-e MYSQL_PORT_3306_TCP_PORT="3306" \
-e DATABASE_NAME="huginn_production" \
-e SMTP_USER_NAME="xxx@xxx.com" \
-e SMTP_PASSWORD="your password" \
-e SMTP_SERVER="smtp.exmail.qq.com" \
-e SMTP_PORT="587" \
-e SMTP_AUTHENTICATION="login" \
-e SMTP_ENABLE_STARTTLS_AUTO="true" \
-e SEND_EMAIL_IN_DEVELOPMENT="true" \
-e EMAIL_FROM_ADDRESS="xxx@xxx.com" \
-e SMTP_DOMAIN="exmail.qq.com" \
-e DATABASE_USERNAME="root" \
-e DATABASE_PASSWORD="your password" \
-e DATABASE_HOST="172.17.0.1" \
-e DATABASE_PORT="3306" \
huginn/huginn
外链数据库可能还不急,现在优先了解一下要怎么使用huginn
部署好了后就可以通过端口访问了,默认账号密码为admin/password
功能介绍
Agents
Agent就是一个步骤的代理
抓取数据源、处理数据、输出为RSS
Scenarios
Scenario就是一系列Agent的集合,用于完成一整个功能
Events
每一个Agent执行一次,输出就是Event
某个Agent输出的Event可以给其它Agent使用
“抓取数据源”Agent抓取了网站的原始数据,并输出为Event,“处理数据”Agent对这个Event进行了处理,然后生成一个新的Event给“输出为RSS”这个Agent
Credentials
全局变量,在Agents之中可以直接调用
Credentials里面可以保存常量,在Agents中调用的时候使用{% credential name %}即可调出保存的value
Services
查了一下不知道有啥用,也没有增加的选项
WebAgents各项参数
Schedule
指定该Agent的自动执行频率,一般一系列Agents里只需要指定第一个Agent的Schedule,后面的Agent就能跟着动了。也可以不设定Schedule,利用另一个Schedule Agent来控制自启动。
Controllers
是控制这个Agent的启动、执行、停用等的另一个Agent,一般不用填,当你配置了另一个Agent时会自动填上的。
Keep events
指定Event的保存时长,对于网页抓取Agent的话保存的Events可以帮助它检测网页是否更新。如果后面会配置去重Agent的话这里就不必设置很长的时间。
Sources
是上一个Agent,也就是会把Event传过来的Agent.
Receivers
则是下一个Agent,即本Agent所产生的Event的接受者。在还没有建立别的Agent的时候这两项都可以留空,以后会自动填上的。
Option
mode
on change则只输出更新的条目,
all会输出所有条目,
merge则会跟传入的Event合并。
type
指定文档类型,分别是xml、html、json或者text
,不同类型抓取写法不一样,示例可以看配置页面右边栏。接下来以某个网页为例子,示例如何对网页的结构进行分析。打开要监视的网页,可以看到一个文章列表。现在要做的就是发现文章列表内每条链接的结构,并使用XPath语法表达出来。
WebAgents示例
以我的博客为例吧,先创建一个系列
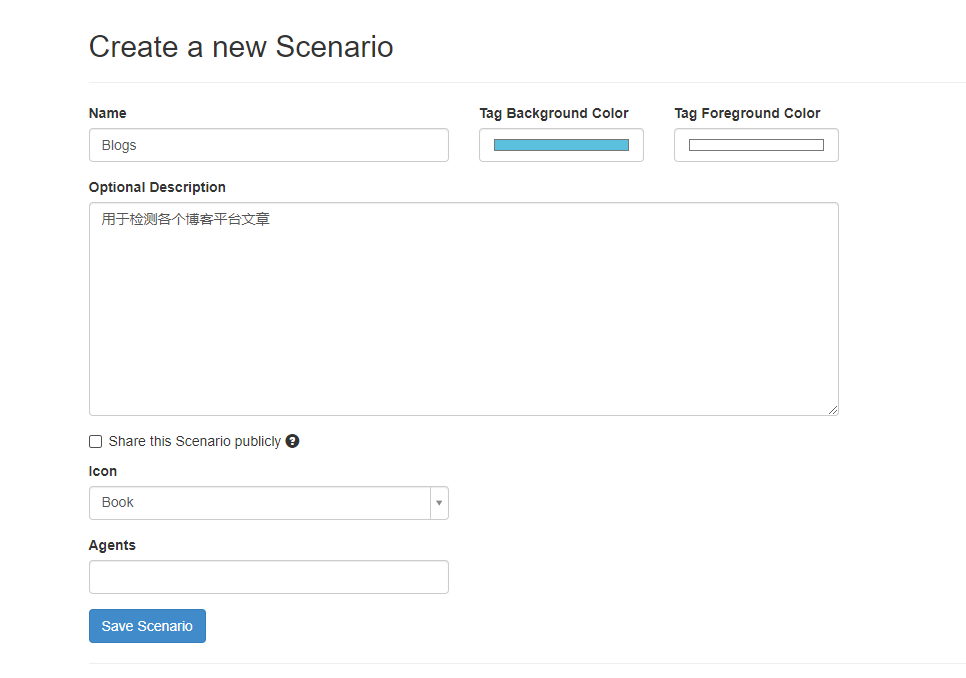
agent留空
创建一个agent
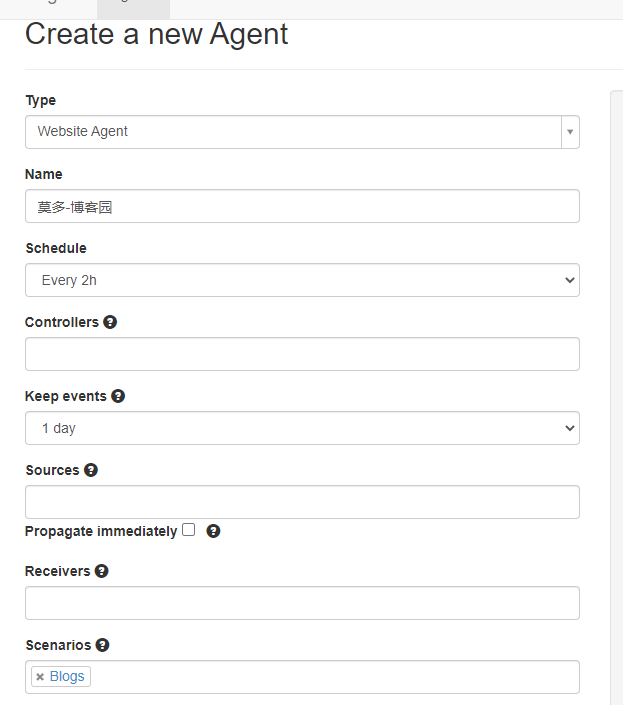
在下面的配置中加入以下内容
使用F12打开控制台
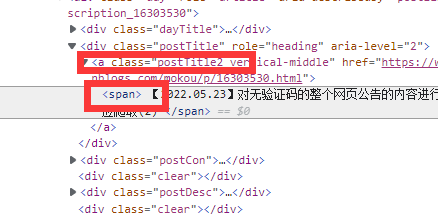
可以看到我要抓的标题在postTitle2 vertical-middle的下面
因此先尝试使用
//*[@class='postTitle2 vertical-middle']
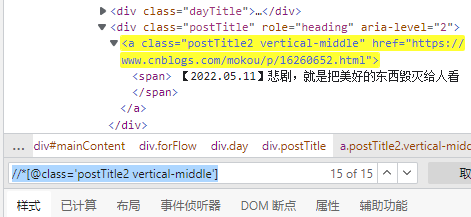
可以得到15个结果,我的首页也只有15个博文,因此这是没有错的
但是我们需要的是a下面span的内容
所以改为
//*[@class='postTitle2 vertical-middle']/span
然后进行Dry Run,看看会得到什么结果
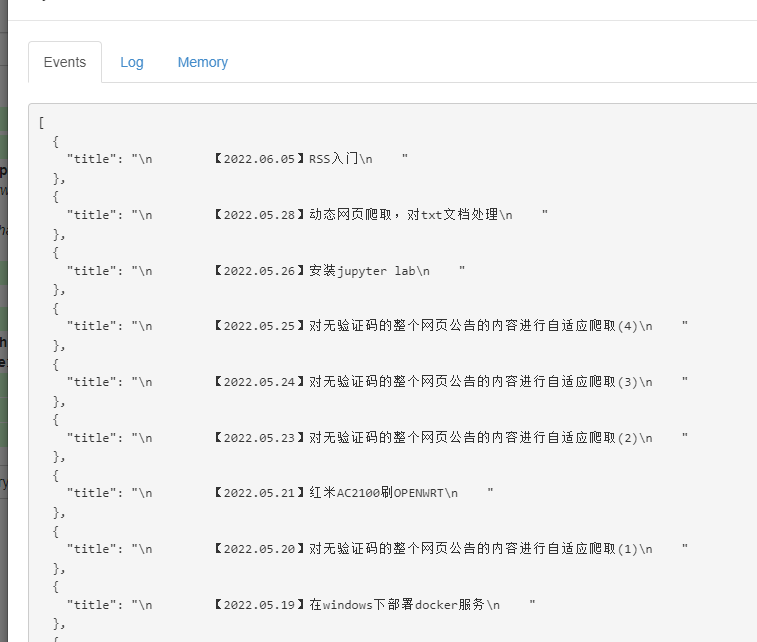
结果不正常,带有回车符号,value的值换为normalize-space(.)就可以了
我们还要抓取href链接
在上上图中我们可以得到href在
//*[@class='postTitle2 vertical-middle']
的属性里面,因此可以得到
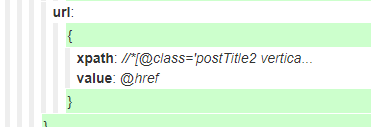
生成以下的json文件
{
"expected_update_period_in_days": "2",
"url": "https://www.cnblogs.com/mokou/",
"type": "html",
"mode": "on_change",
"extract": {
"title": {
"xpath": "//*[@class='postTitle2 vertical-middle']/span",
"value": "normalize-space(.)"
},
"url": {
"xpath": "//*[@class='postTitle2 vertical-middle']",
"value": "@href"
}
}
}
进行save保存后,会在Event中得到如下结果
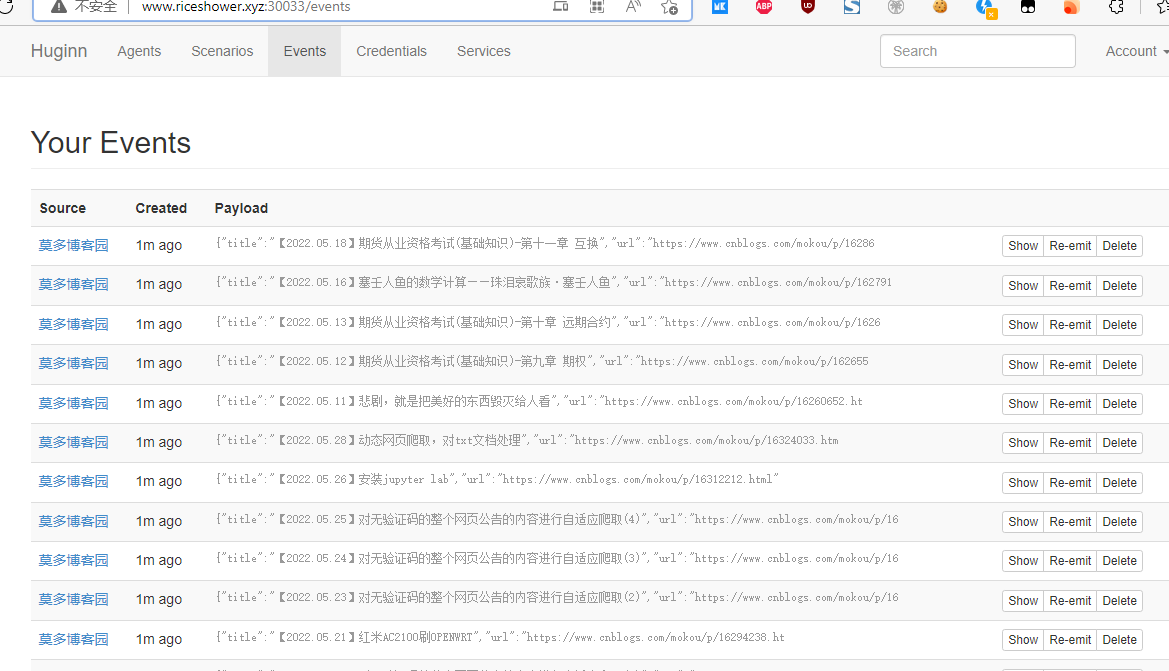
参考链接
Huginn中文指南:搭建自己的iFTTT - 简书 (jianshu.com)
上手huginn的第一篇教程:一个定时监控黄金价格的rss - 知乎 (zhihu.com)
自动化工具 Huginn 入门指南 – Every Little Thing – Medium (360doc.com)