本次的学习来源:https://www.bilibili.com/video/BV1WT4y177SA
加载库
nn、F、optim都是使用pytorch时候的常用简写
# 加载库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
定义超参数
# 定义超参数
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 决定是CPU还是GPU,像我用的macOS就只能使用CPU
EPOCHS = 100 # 训练数据集的轮数
图像处理
# 构建pipeline,对图像做处理
pipeline = transforms.Compose([
transforms.ToTensor(), # 将图片转换成tensor
transforms.Normalize((0.1307,),(0.3081,)) # 正则化,模型出现过拟合现象时,降低模型复杂度
# 过拟合:在数据集中可以判断,但是在测试集中无法实现
])
下载数据集
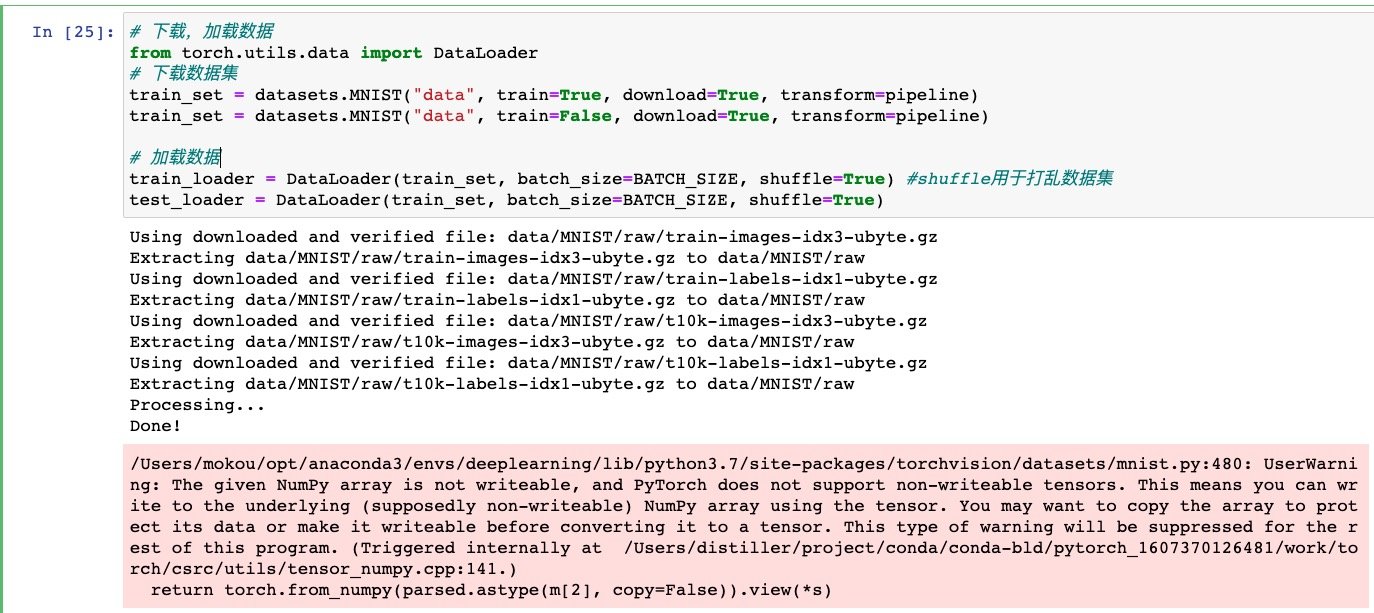
# 下载,加载数据
from torch.utils.data import DataLoader
# 下载数据集
train_set = datasets.MNIST("data", train=True, download=True, transform=pipeline)
train_set = datasets.MNIST("data", train=False, download=True, transform=pipeline)
# 加载数据
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) #shuffle用于打乱数据集
test_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
因为使用代码下载有可能下载失败或者超时
因此去官网下载数据集:http://yann.lecun.com/exdb/mnist/
一共有四个数据包,并上传到jupyter的文件夹中
或者是在使用下载命令时,查看它的下载目录
train_set = datasets.MNIST("data", train=True, download=True)
在当前目录下创建一个data文件夹,下载训练集,它会告诉你它所要下载的文件夹路径
将这四个压缩包拖到下载目录中,重新运行该代码会显示下面的结果
查看下载的数据集图片
需要用到opencv,先在虚拟环境的终端中下载安装opencv
pip install opencv-python
再重新启动jupiter notebook
OpenCv作用:OpenCV是一个开源的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。提供了Python、Ruby、MATLAB等语言的接口,并且实现了图像处理和计算机视觉方面的很多通用算法,可以给开发者调用。
Numpy:提供和处理N维数组对象Array的方法
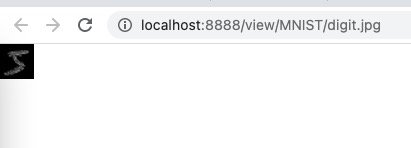
安装好后,使用这一段代码,可以在当前目录生成一张照片
# 显示MNIST的图片
with open("./data/MNIST/raw/train-images-idx3-ubyte","rb") as f:
file = f.read()
image1 = [int(str(item).encode('ascii'), 16) for item in file[16 : 16+784]] #28*28=784,这个784是这么来的
import cv2
import numpy as np
image1_np = np.array(image1,dtype=np.uint8).reshape(28,28,1)
print(image1_np.shape)
cv2.imwrite("digit.jpg", image1_np)
然后就可以看到这一张照片了
(这段代码说是不用搞懂,MNIST的数据结构在官网里面也有详细说明了
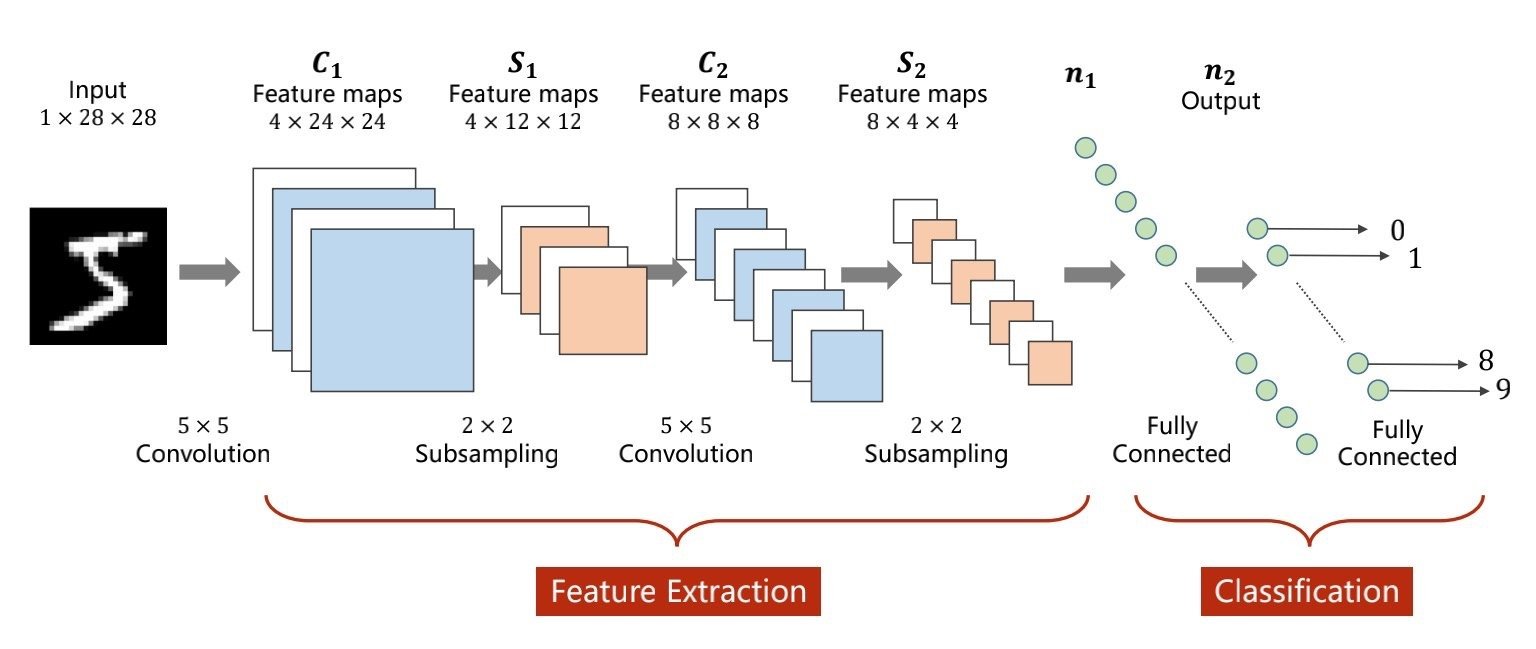
构建网络模型
这里有的词语不了解,可以到这个链接里面看:https://www.cnblogs.com/mokou/p/14446820.html
# 构建网络模型
class Digit(nn.Module): # 继承Moudle类
def __init__(self):
super().__init__()
# 卷积层作用:保留空间特征、空间结构、空间信息
self.conv1 = nn.Conv2d(1, 10, 5)# 因为是单通道的图片,因此输入通道是1,10是输出通道,5是卷积核
self.conv2 = nn.Conv2d(10, 20, 3)
# 全联接层,任意两个节点间,每个输入节点都要参与到输出节点的计算上
self.fc1 = nn.Linear(20*10*10, 500) # 20*10*10是输入通道,500是输出通道
self.fc2 = nn.Linear(500, 10) # 500是输入通道,10是输出通道
def forward(self,x):
input_size = x.size(0) # 张量格式:batch_size * 1 * 28 * 28,因此.size(0)取到batch_size
x = self.conv1(x) # 看上面__init__()的函数定义
# 这一步的执行结果。输入:batch_size * 1 * 28 * 28 输出:batch_size * 10 * 24 * 24(24的来源:28-5+1)
x = F.relu(x) # 激活函数,使得输出变为非线性函数,表达能力更加强大
# 保持输出不变,仍然为 输出:batch_size * 10 * 24 * 24
x = F.max_pool2d(x, 2, 2) # 池化层,作用:下采样/降采样
# 输入:batch_size * 10 * 24 * 24 输出:batch_size * 10 * 12 * 12
x = self.conv2(x) # 输入:batch_size * 10 * 12 * 12 输出:batch_size * 20 * 10 * 10(10的来源:12-3+1)
x = F.relu(x) # 输出格式不变
x = view(input_size, -1)
# 拉平(拉成一个2000*1的向量),-1的参数意思为“自动计算维度”,20*10*10=2000
x = self.fc1(x) # 输入:batch*2000 输出:batch*500
x = F.relu(x) # 输出格式不变
x = self.fc2(x) # 输入:batch*500 输出:batch*10
output = F.log_softmax(x, dim=1) #多分类后,每个数字的概率值
#softmax层,映射到和为1的概率分布上
return output
卷积和下采样的在前面的特征提取部分
拉直的效果(全联接):从S2到n1的效果
最后的softmax层,就是概率分布