果然想直接进入实战还是太快了,有些概念还是必须要搞清楚的
这次的学习资料来源是廖星宇的《深度学习入门之PyTorch》
关于这部分的视频学习内容来自于:https://www.bilibili.com/video/BV1dp4y1U7mD
(刚好这个老师的系统是使用macOS,太好了TuT
Tensor(张量)
PyTorch 里面处理的最基本的操作对象就是Tensor
Tensor是张量的英文,表示的是一个多维的矩阵,比如零维就是一个点,一维就是向量,二维就是一般的矩阵,多维就相当于一个多维的数组,这和numpy是对应的,而且PyTorch的Tensor可以和numpy的ndarray相互转换,唯一不同的是PyTorch可以在GPU上运行,而numpy的ndarray只能在CPU上运行。
(macOS就只能运行在CPU上
以下内容来自参考链接:https://blog.csdn.net/qq_24407657/article/details/81835614
张量基础
张量有以下的相关概念
scalar(标量/0维张量):一个数值
vector(向量):一维数组/张量
matrix(矩阵):二维数组/张量 例:[[2,3],[4,5]]
tensor(张量):大于二维的数组,即多维数组
在新文件里先建立一个数组,检查是否为tensor对象
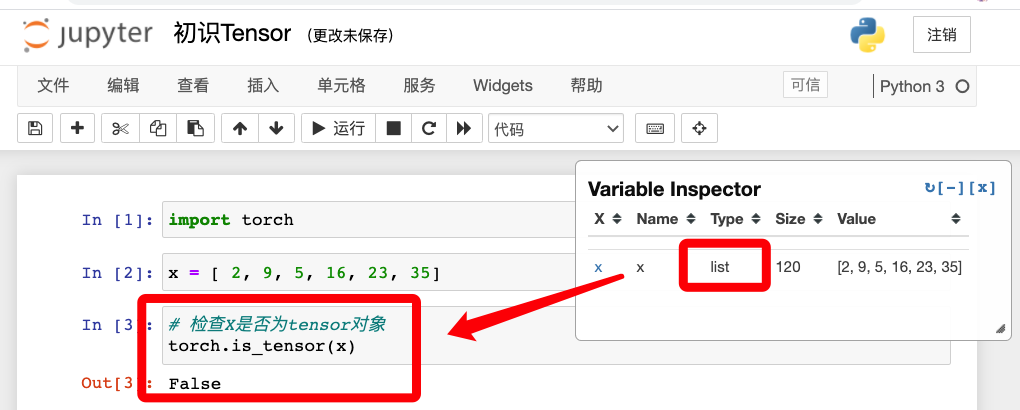
输出false,说明简单的数组并不能作为一个tensor对象
使用torch的函数去生成一个tensor对象
这里的rand后面的参数意思为一行两列的意思
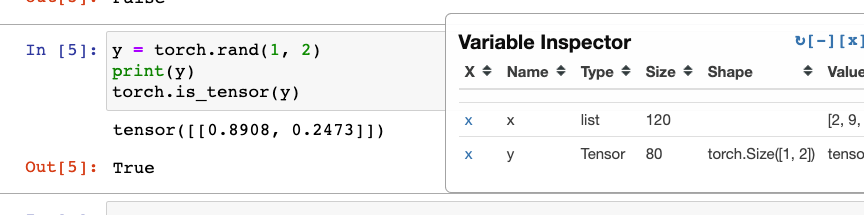
可以看到y就是一个tensor类型的数据
将numpy转化为tensor类型
numpy也很常用,要用Pytorch的话,要转为tensor类型
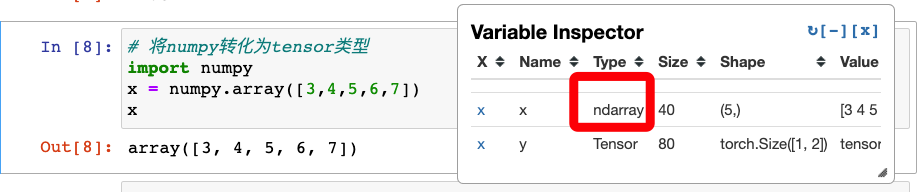
使用torch.from_numpy()函数后,变为tensor类型

随机抽样类函数
torch.manual_seed(seed)
设定生成随机数的种子,并返回一个torch._C.Generator对象
参数:seed(int or long)种子
torch.initial_seed()
返回生成随机数的原始种子(pathon long)
torch.get_rng_state()
返回随机生成器状态(Byte Tensor)
torch.set_rng_state(new_state)
设定随机生成器状态
参数:new_state(torch.Byte Tensor)-期望的状态
torch.default_generator=<torch._C.Generator object>
torch.bernoulli(input,out=None)->Tensor
从伯努利分布中抽取二元随机数(0 or 1)
输入张量需包含用于抽取上述二元随机值的概率。因此,输入中的所有值都必须在[0,1]区间。
输出张量的第i个元素值,将会以输入张量的第i个概率值等于1.
返回值将会是与输入相同大小的张量,每个值为0或者1
input(Tensor)---伯努利分布的概率值
out(Tensor, optional)---张量
例子:
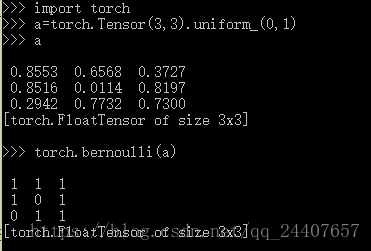
uniform_(0,1)使得产生的矩阵规范在[0,1]区间内
torch.mutinomial(input,num_samples,replacement=False,out=None)->Long Tensor
返回一个张量,每行包含从input相应行中定义的多项分布中抽取的num_samples个样本。
注意:input每行的值不需要总和为1,但必须非负且总和不能为0
当抽取样本时,依次从左到右排列(第一个样本对应第一列)
如果input是一个向量时,out也是一个相同长度num_samples的向量
如果input是一个矩阵,out对应是矩阵
如果replacement=True,则样本抽取可以重复。否则一个样本在每行不能被重复抽取。
num_samples必须小于input的长度
参数:input(Tensor)---包含概率的张量
num_samples(int)---抽取的样本数
replacement(bool,optional)
out(Tensor,optional)
例子:

torch.normal(means,std,out=None)
返回一个张量,包含从给定参数means,std,的离散正态分布中抽取随机数
参数:
means(Tensor)----包含每个输出元素相关的正态分布的均值
std(Tensor)---包含每个输出元素相关的正态分布的标准差
均值和标准差的形状不须匹配,但每个张量的元素个数须相同。
例子:

注意:当means或std 为标量时,则共享
索引,切片,连接,换位
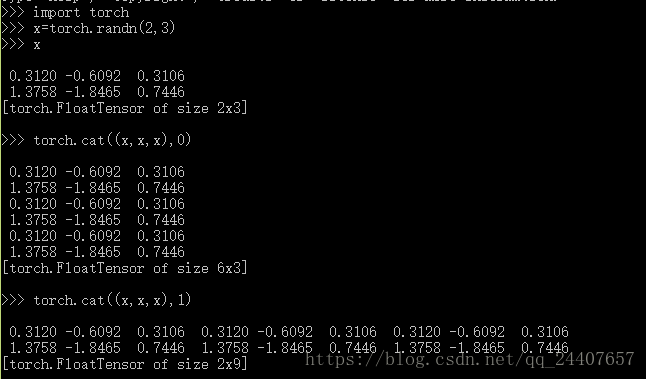
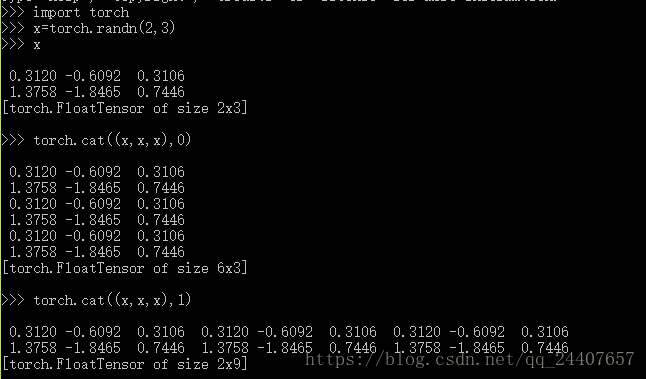
torch.cat(inputs,dimension=0)->tensor
在给定维度上对输入的张量序列进行连接操作
参数:
inputs(sequence of Tensors)---可以是任意相同Tensor类型的python序列
dimension(int,optional)---沿此维连接张量序列
例子:
torch.squeeze(inout,dim=None,out=None)
将输入张量形状中的1去除并返回
给定维时,只在给定维度上挤压
注意:返回张量和输入张量共享内存,改变其中一个的内容会改变另一个
例子:

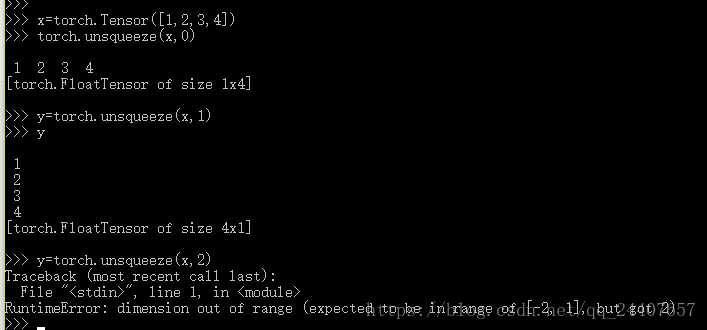
torch.unsqueeze(input,dim,out=None)
类似2
例子:
创建操作
torch.eye(n,m=None,out=None)
返回一个2维张量,对角线位置全为1,其他位置全0
参数:
n(int)----行数
m(int,optional)---列数,如果为None默认为n
out(Tensor,optional)
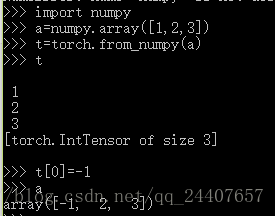
torch.from_numpy(ndarray)--->Tensor
Numpy桥,将numpy.ndarray转换为pytorch的Tensor
返回的张量tensor和numpy的ndarray共享同一内存空间。修改一个会导致另外一个也被修改,返回的张量不能改变大小
例子:
torch.linspace(start,end,steps=100,out=None)--->Tensor
返回一个一维张量,包含区间start和end上均匀间隔的steps个点。
输出1维张量的长度为steps
参数:略
例子:

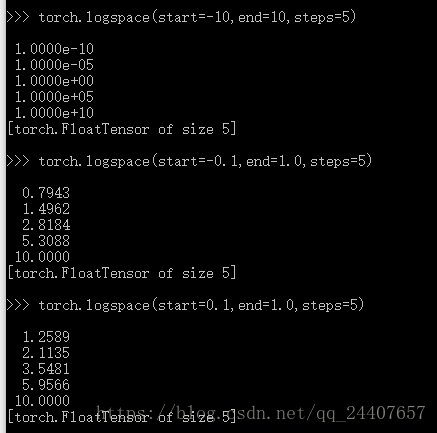
torch.logspace(start,end,steps=100.out=None)--->Tensor
设置的区间为常用对数,输出的值为其对应的真数
其余的同2
例子:
torch.ones(*sizes,out=None)--->Tensor
例子:

torch.rand(*sizes,out=None)--->Tensor
(0,1)区间均匀分布随机抽取
例子:
torch.randn(*sizes,out=None)--->Tensor
标准正态分布(均值0方差1,即高白噪声)中随机抽取
同上
torch.randperm(n,out=None)--->Long Tensor
给定参数n,返回一个从0到n-1的随机整数排列
torch.arange(start,end,step=1,out=None)--->Tensor
参数:
start(float)-------序列起始点
end(float)--------序列终止点
step(float)------相邻点的间隔大小
out(Tensor,optional)
例子:

torch.range(start,end,step=1,out=None)--->Tensor
例子:
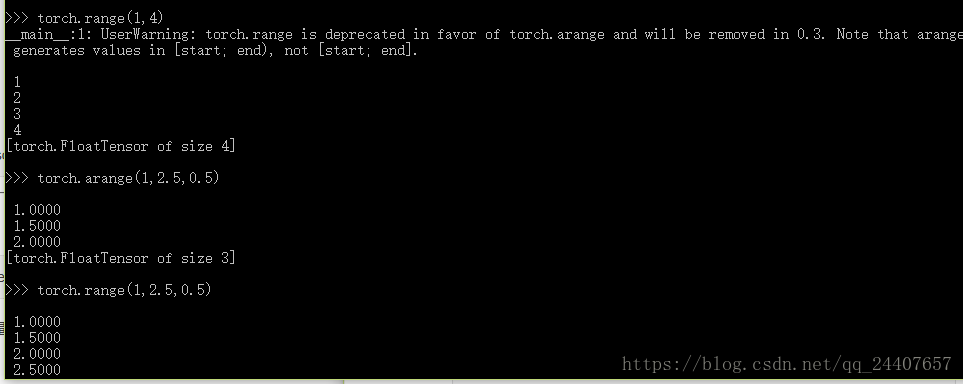
建议使用torch.arange
torch.zeros(*sizes,out=None)--->Tensor
类似于torch.ones()
比较操作
torch.max(input,dim,max=None,max_indices=None)--->(Tensor,LongTensor)
返回输入张量给定维度上每行的最大值,并同时返回每个最大值的位置索引
输出形状中,将dim维设为1,其他与输入型状保持一致
参数:
input (Tensor) – 输入张量
dim (int) – 指定的维度
max (Tensor, optional) – 结果张量,包含给定维度上的最大值
max_indices (LongTensor, optional) – 结果张量,包含给定维度上每个最大值的位置索引
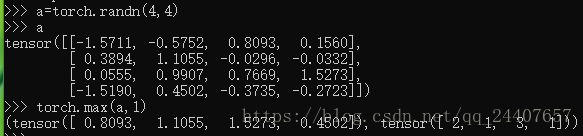
如果只有一个输入,返回所有元素中的最大值
如果输入两个相同形状的张量,返回的张量形状不变,每个位置两个向量中的最大值
Variable(变量)
前向传播、反向传播:https://blog.csdn.net/bitcarmanlee/article/details/78819025
前向传播、反向传播、自动求导:https://zhuanlan.zhihu.com/p/51385110
Variable是PyTorch特有概念,是numpy里所没有的
Variable和Tensor本质上没有区别,不过Variable会被放入一个计算图中,然后进行前向传播,反向传播,自动求导
构建深度学习模型的基本流程就是:搭建计算图,求得损失函数,然后计算损失函数对模型参数的导数,再利用梯度下降法等方法来更新参数。
搭建计算图的过程,称为“正向传播”,这个是需要我们自己动手的,因为我们需要设计我们模型的结构。
由损失函数求导的过程,称为“反向传播”
variable三个重要组成属性
分别为data、grad、grad_fn
通过data可以取出Variable里面的tensor数值,grad_fn表示的是得到这个Variable的操作,比如通过加减还是乘除来得到的,最后grad是这个Variabel的反向传播梯度
Variable在torch.autograd.Variable中,要将一个tensor变成Variable也非常简单,比如想让一个tensora变成Variable,只需要variable(a)就可以了
Dataset(数据集)
Dataset是数据的读取和预处理的过程
torch.utils.data.Dataset是代表这一数据的抽象类,你可以自己定义你的数据类继承和重写这个抽象类,非常简单,只需要定义__len__和__getitem__这两个函数
之前有接触一些:https://www.cnblogs.com/mokou/p/14397478.html
Module(模组)
在PyTorch里面编写神经网络,所有的层结构和损失函数都来自于torch.nn,所有的模型构建都是从这个基类nn.Module继承的
torch.optim(优化)
在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化(或最大化),优化算法就是一种调整模型参数更新的策略。