异常处理:
我们平时编写代码是难免会遇到各种各样的错误,我们可以对这些错误分为两种:
1.语法错误:语法错误是解释器对代码进行语法的检测过程,也就是我们在执行代码之前就需要解决的错误问题;
2.逻辑错误:是我们的写代码时的逻辑过程出现的错误举例说明:
int('asdf') ''' 错误信息 Traceback (most recent call last): File "F:/Python全栈开发之路/py_fullstack/Day35/test1.py", line 1, in <module> int('asdf') ValueError: invalid literal for int() with base 10: 'asdf' '''
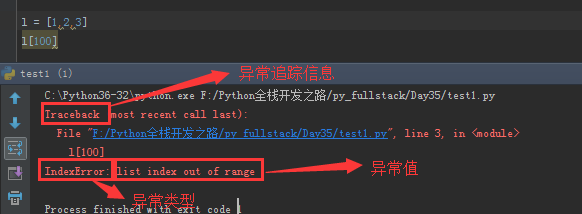
l = [1,2,3] l[100] ''' 错误信息: Traceback (most recent call last): File "F:/Python全栈开发之路/py_fullstack/Day35/test1.py", line 3, in <module> l[100] IndexError: list index out of range '''
异常的内容包括哪些:
异常的作用:
发生异常后,会中断后面代码的执行,如果加上相应类型异常的try...except后后面的代码可以正常执行:

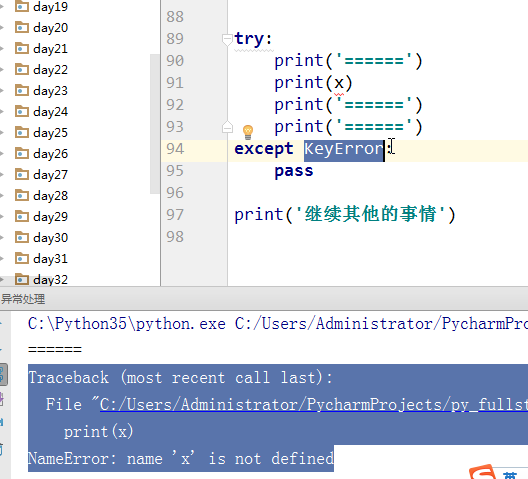
我们可以看出,后面的代码正常执行了,如果捕捉的异常类型不匹配的话,还是会抛出来异常信息的:
我们可以给捕捉的异常值起个别名:

在抛出不同异常来处理不同异常的时候,我们可以利用多分枝来处理异常:
try: d = {'a':1} d['b'] except IndexError as e: print(e) except ValueError as e: print(e) ''' 异常信息: Traceback (most recent call last): File "F:/Python全栈开发之路/py_fullstack/Day35/test1.py", line 3, in <module> d['b'] KeyError: 'b' '''
这时候我们如果加上KeyError异常的话:
try: d = {'a':1} d['b'] except IndexError as e: print(e) except ValueError as e: print(e) except KeyError as e: print(e)

但是我们在处理异常的时候,总不能把所有的异常类型都写一遍,所以我们可以利用万能异常来解决,当我们监控一段代码的时候,不用管程序会抛出什么异常,都只用一种方式去处理异常:

我们也可以单独处理某几个异常,意想不到或者不想单独处理的异常,我们可以这样写:
try: d = {'a':1} d['b'] except IndexError as e: print(e) except ValueError as e: print(e) except KeyError as e: print(e) except Exception as e: print(e)
finally:无论代码是否异常,都会执行该模块里面的内容,通常是用来写清理工作的代码


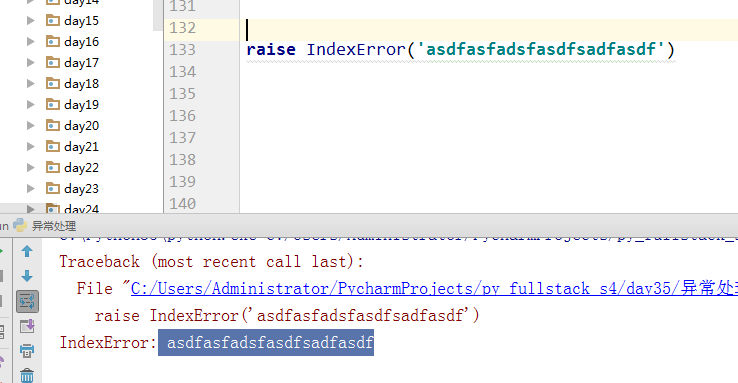
raise:主动触发异常:
自定义异常:

断言:asssert:
asssert后面跟的条件成立的时候,后面的程序能继续往后执行。

模块:

我们可以通过:sys.modules来查看系统导入模块都有哪些
也可以用from...import导入模块

每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突。
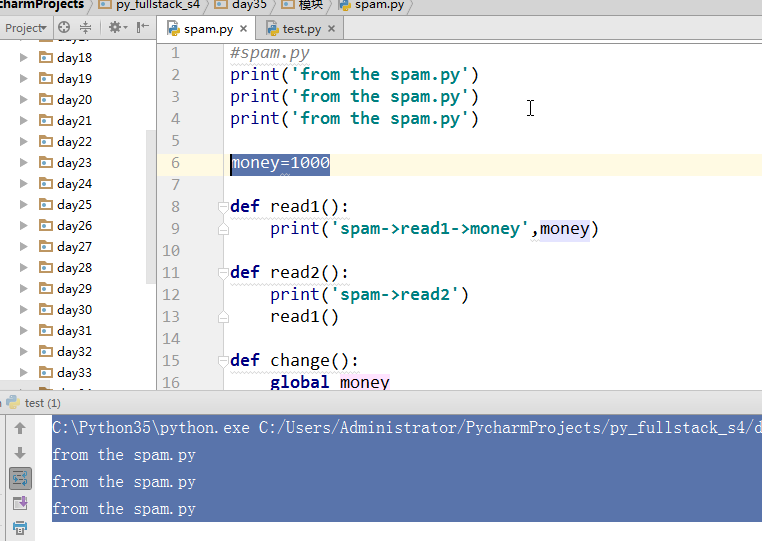
from spam import read1
也可以起个别名:
from spam import read1 as read
这样后面我们就可以直接调用money这个变量了
还可以导入多个变量和函数:
from spam import money,read1,read2
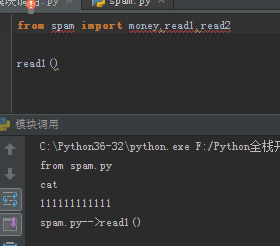
这时我们再直接调用名字就可以直接执行,但是如果在执行文件中有相同的名字,我们导入模块的内容将会被覆盖掉。

__all__这个变量有特殊的意义
我们在导入模块的时候可以用*导入内容,这里的__all__是一个列表,它里面的值也就是*代表的所有值,我们在以这种方式导入spam的时候,可用变量或者函数只被限定为列表中的名字,并且在被调用模块中也要初始化列表中的每一个名字:
我们在spam.py中写入:
print("from spam.py") __all__ = ['a','b'] money = 111111111111 def read1(): print('spam.py-->read1()') def read2(): print('spam.py-->read2()') read1()
在其他文件中调用的时候,我们发现报错了:

我们在执行某个代码文件的过程中,不支持模块的重新导入:
我们在执行过程中,将模块spam.py这个文件删除,解释器仍然不会报错。

测试模块是否为__main__
使用:if __name__ == '__main__':
这段代码常用在某个模块测试的时候使用,如果打印结果放入if下面的内部,就可以测试模块功能是否正常,并且,我们在其他地方调用这个模块使用的时候不会执行if下面内部的代码。
这样我们可以把一个模块当做脚本使用。




再从内建找

注:不要建与内建模块和第三方重名的.py文件


包:
Packages are a way of structuring Python’s module namespace by using “dotted module names”
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
包的本质就是一个包含__init__.py文件的目录。
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
glance/ #Top-level package ├── __init__.py #Initialize the glance package ├── api #Subpackage for api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd #Subpackage for cmd │ ├── __init__.py │ └── manage.py └── db #Subpackage for db ├── __init__.py └── models.py
#文件内容 #policy.py def get(): print('from policy.py') #versions.py def create_resource(conf): print('from version.py: ',conf) #manage.py def main(): print('from manage.py') #models.py def register_models(engine): print('from models.py: ',engine)
注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。

这种导入方式是正确的:

3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
包下面有一个__init__.py,每次导入这个包的时候会执行__init__.py这个文件
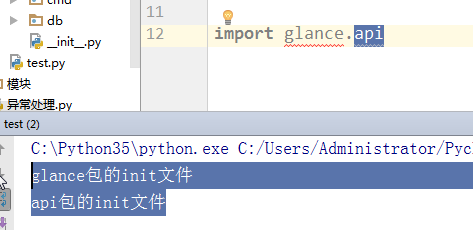
更改导入后:

绝对导入和相对导入:
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py

1 在glance/api/version.py 2 3 #绝对导入 4 from glance.cmd import manage 5 manage.main() 6 7 #相对导入 8 from ..cmd import manage 9 manage.main()
测试结果:注意一定要在于glance同级的文件中测试
1 from glance.api import versions
注意:在使用pycharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,一定要回到命令行去执行,模拟我们生产环境,你总不能拿着pycharm去上线代码吧!!!
特别需要注意的是:可以用import导入内置或者第三方模块,但是要绝对避免使用import来导入自定义包的子模块,应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,十分开心的就去做了,它直接这么做
1 #在version.py中 2 3 import policy 4 policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance同级下的一个test.py文件中导入version.py,如下
1 from glance.api import versions 2 3 ''' 4 执行结果: 5 ImportError: No module named 'policy' 6 ''' 7 8 ''' 9 分析: 10 此时我们导入versions在versions.py中执行 11 import policy需要找从sys.path也就是从当前目录找policy.py, 12 这必然是找不到的 13 '''
单独导入包名称时不会导入包中所有包含的所有子模块,如
#在与glance同级的test.py中 import glance glance.cmd.manage.main() ''' 执行结果: AttributeError: module 'glance' has no attribute 'cmd' '''
解决方法:
1 #glance/__init__.py 2 from . import cmd 3 4 #glance/cmd/__init__.py 5 from . import manage
执行:
1 #在于glance同级的test.py中 2 import glance 3 glance.cmd.manage.main()