半监督生成对抗网络
一、SGAN简介
半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使用任何标签)不同,半监督学习只为训练数据集的一小部分提供类别标签。通过内化数据中的隐藏结构,半监督学习努力从标注数据点的小子集中归纳,以有效地对从未见过的新样本进行分类,要使半监督学习有效,标签数据和无标签数据必须来自相同的基本分布。
缺少标签数据集是机器学习研究和实际应用中的主要瓶颈之一,尽管无标签数据非常丰富(互联网实际上就是无标签图像、视频和文本的无限来源),但为它们分配类别标签通常非常昂贵、不切实际且耗时。在ImageNet中手工标注320万张图像用了两年半的时间,ImageNet是一个标签图像的数据库,在过去的十年中对于图像处理和计算机视觉取得的许多进步均有帮助。
训练需要大量标签数据是监督学习的致命弱点。目前,工业中的人工智能应用绝大多数使用监督学习。缺乏大型标签数据集的一个领域是医学,医学上获取数据(如来自临床试验的结果)通常需要耗费大量的精力和开支,更别说会面临道德伦理和隐私等更严重的问题了,因此,提高算法从越来越少的标注样本中学习的能力具有巨大的实际意义。
有趣的是,半监督学习可能也是最接近人类学习方式的机器学习方式之一,小学生学习阅读和书写时,老师不必带他们出门旅行,让他们在路上看到成干上万个字母和数字的样本以后,再根据需要纠正他们一就像监督学习算法的运作方式一样。相反,只需要一组样本可供孩子学习字母和数字,然后不管何种字体、大小、角度、照明条件和许多其他条件下,他们能够识别出来。半监督学习旨在按照这种有效的方式教会机器。
作为可用于训练的附加信息的来源,生成模型己被证明有助于提高半监督模型的准确性。
1. 什么是SGAN
半监督生成对抗网络(Semi-Supervised GAN, SGAN)是一种生成对抗网络,其判别器是多分类器。这里的判别器不只是区分两个类(真和假),而是学会区分N+1类,其中N是训练数据集中的类数,生成器生成的伪样本增加了一个类。
例如,MNIST手写数字数据集有10个标签(每个数字一个标签,从0到9),因此在此数据集上训练的SGAN鉴别器将预测10+1=11个类。在我们的实现中,SGAN判别器的输出将表示为10个类别的概率(之和为1.0)加上另一个表示图像是真还是假的概率的向量。将判别器从二分类器转变为多分类器看似是一个微不足道的变化,但其含义比乍看之下更为深远。我们从下图所示的SGAN架构开始解释。(此SGAN中,生成器输入随机噪声向量z并生成伪样本\(x^*\)。判别器接收3种数据输入:来自生成器的伪数据、真实的无标签数据样本X和真实的标签数据样本(x,y),其中y是给定样本对应的标签;然后判别器输出分类,以区分伪样本与真实样本区,并为真实样本确定正确的类别。注意,标签数据比无标签数据少得多。实际情况中,这一对比甚至比本图所显示的更明显,标签数据仅占训练数据的一小部分(通常低至1%~2%))
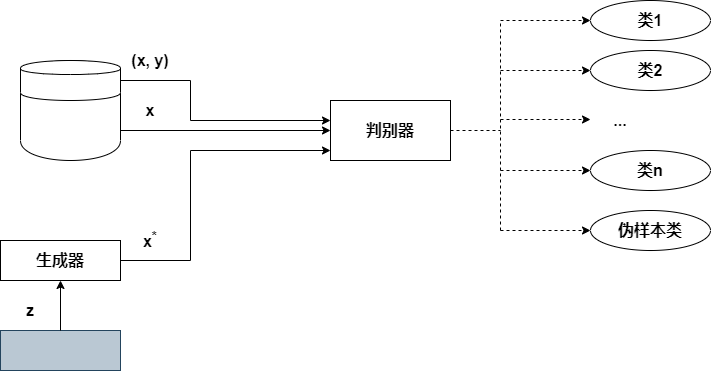
与传统GAN相此,区分多个类的任务不仅影响了判别器本身,还增加了SGAN架构、训练过程和训练目标的复杂性。
SGAN生成器的目的与原始GAN相同:接收一个随机数向量并生成伪样本,力求使伪样本与训练数据集别无二致。
但是,SGAN判别器与原始GAN实现有很大不同。它接收3种输入:生成器生成的伪样本(x)、训热数据集中无标签的真实样本(x)和有标签的真实样本(x,y),其中y表示给定样本x的标签。
SGAN判别器的目标不是二分类,而是在输入样本为真的情况下,将其正确分类到相应的类中,或将样本作为假的(可以认为是特殊的附加类)排除。
有关SGAN子网络的要点见下表。
| 生成器 | 判别器 | |
|---|---|---|
| 输入 | 一个随机数向量(z) | 判别器接收3种输入:训练数据集中无标签的真实样本(x);训练数据集中有标签的真实样本(x,y);生成器生成的伪样本(\(x^*\)) |
| 输出 | 尽可能令人相信的伪样本(\(x^*\)) | 表示输入样本属于N个真实类别中的某一个或属于伪样本类别的可能性 |
| 目标 | 生成与训练数据集别无二致的伪样本,以欺骗判别器,使之将伪样本分到真实类别 | 学会将正确的类别标签分配给真实的样本,同时将来自生成器的所有样本判别为假 |
3. 训练过程
回想一下,常规GAN通过计算\(D(x)和D(x^*)\)的损失并反向传播总损失来更新判别器的可训练参数,以使损失最小,从而训练判别器。生成器通过反向传播判别器损失\(D(x^*)\)并寻求使其最大化来进行训练,以便让判别器将合成的伪样本错误地分类为真。
为了训练SGAN,除了\(D(x)和D(x^*)\),我们还必须计算有监督训练样本的损失:\(D((x, y))\)。些损失与SGAN判别器必须达到的双重目标相对应:区分真伪样本;学习将真实样本正分类。用论文中的术语来说,双重目标对应于两种损夫:有监督损失(suprvised loss)和无监督损失(unsupervised loss)。
4. 训练过程
到目前为止,我们看到的GAN变体都是生成模型。它们的目标是生成逼真的数据样本,正因如此,人们最感兴趣的一直是生成器,判别器网络的主要目的是帮助生成器提高生成图像的质量。在训练结束时,我们通常会忽略判别器,仅使用训练好的生成器来创建逼真的台成数据。
在SGAN中主要关心的反而是判别器,训练过程的目标是使该网络成为仅使用一小部分标签数据的半监督分类器,其准确率尽可能接近全监督的分类器(其训练数据集中的每个样本都有标签),生成器的目标是通过提供附加信息(它生成的伪数据)来帮助判别器学习数据中的相关模式,从而提高其分类准确率,训练结束时,生成器将被丢弃,而训练有素的判别器将被用作分类器。
二、SGAN的实现
我们将实现一个SGAN模型。该模型仅使用I00个训练样本即可对MNIST数据集中的手写数字进行分类。最后,我们将模型的分类准确率与其对应的全监督模型进行了比较,看看半监督学习所取得的进步。
1. 架构图
本教程中实现的SGAN模型的高级示意如下图所示,(生成器将随机噪声转换为伪样本;判别器输入有标签的真实图像(x,y)、无标签的真实图像(x)和生成器生成的伪图像\((x^*)\)。为了区分真实样本和伪样本,判别器使用了sigmoid函数;为了区分真实标签的分类,判别器使用了softmax函数)它比开头介绍的一般概念图要复杂一些。关键在于实现细节。
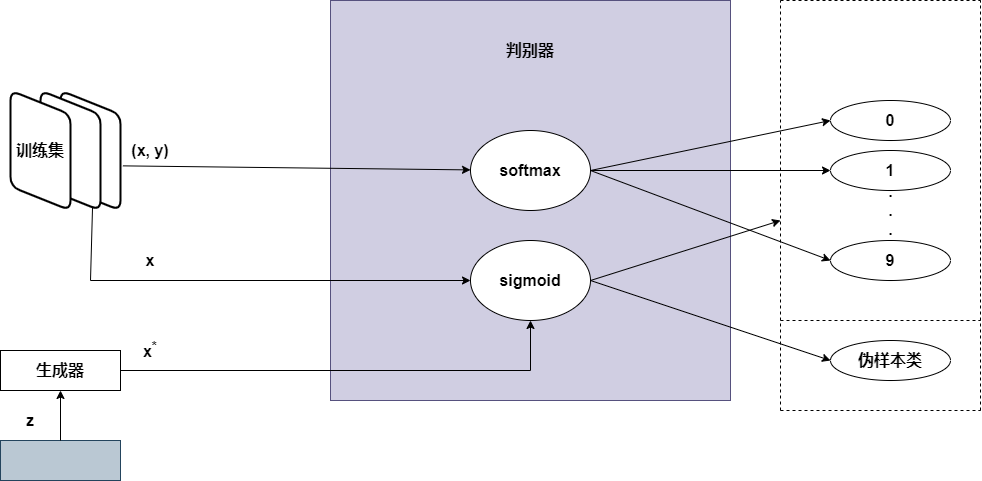
为了解决区分真实标签的多分类问题,判别器使用了softmax函数,该函数给出了在给定数量的类别(本例中为10类)上的概率分布,给一个给定类别标签分配的概率越高,判别器就越确信该样本属于这一给定的类,为了计算分类误差,我们使用了交叉熵损失,以测量输出概率与目标独热编码标签之间的差异。
为了输出样本是真还是假的概率,判别器使用了sigmoid激活函数,并通过反向传播二元交叉熵损失来训练其参数。
2. 设置
首先导入运行模型需要的所有模块和库,指定输入图像的大小、噪声向量z的大小以及半监督分类的真实类别的数量(判别器将学习识别每个数字对应的类)。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import (
Activation, BatchNormalization, Concatenate, Dense,
Dropout, Flatten, Input, Lambda, Reshape
)
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.layers import Conv2D, Conv2DTranspose
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import backend as K
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
#模型输入维度
img_rows = 28
img_cols = 28
channels = 1
img_shape = (img_rows, img_cols, channels)#输入图像的维度
z_dim = 100#噪声向量的大小
num_classes = 10#数据集中类别的数量
3. 数据集
尽管MNIST训练数据集里有50000个有标签的训练图像,但我们仅将其中的一小部分(由num_labeled参数决定)用于训练,并假设其余图像都是无标签的。我们这样来实现这一点:取批量有标签数据时仅从前num_labeled个图像采样,而在取批量无标签数据时从其余(50000-num_labeled)个图像中采样。
Dataset对象提供了返回所有num_labeled训练样本及其标签的函数,以及能返回MNIST数据集中所有10000个带标签的测试图像的函数。训练后,我们将使用测试集来评估模型的分类在多大程度上可以推广到以前未见过的样本。
class Dataset:
def __init__(self, num_labeled):
self.num_labeled = num_labeled#训练集中使用的有标签图像的数量
(self.x_train, self.y_train), (self.x_test, self.y_test) = mnist.load_data()
def preprocess_imgs(x):
x = (x.astype(np.float32) - 127.5) / 127.5#灰度像素值从[0, 255]缩放到[-1, 1]
x = np.expand_dims(x, axis=3)#将图像尺寸扩展到宽x高x通道数
return x
def preprocess_labels(y):
return y.reshape(-1, 1)#将元素转换成一列
#训练
self.x_train = preprocess_imgs(self.x_train)
self.y_train = preprocess_labels(self.y_train)
#测试
self.x_test = preprocess_imgs(self.x_test)
self.y_test = preprocess_labels(self.y_test)
def batch_labeled(self, batch_size):
#获取随机批量的有标签图像及其标签
idx = np.random.randint(0, self.num_labeled, batch_size)
imgs = self.x_train[idx]
labels = self.y_train[idx]
return imgs, labels
def batch_unlabeled(self, batch_size):
#获取随机批量的无标签图像
idx = np.random.randint(self.num_labeled, self.x_train.shape[0], batch_size)
imgs = self.x_train[idx]
return imgs
def training_set(self):
x_train = self.x_train[range(self.num_labeled)]
y_train = self.y_train[range(self.num_labeled)]
return x_train, y_train
def test_set(self):
return self.x_test, self.y_test
num_labeled = 100#要使用的有标签样本的数量(其余作为无标签样本使用)
dataset = Dataset(num_labeled)
4. 生成器
def build_generator(z_dim):
model = Sequential()
model.add(Dense(256 * 7 * 7, input_dim=z_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(Reshape((7, 7, 256)))
model.add(Conv2DTranspose(128, 3, 2, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(128, 3, 2, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(1, 3, 1, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(1, 7, padding='same'))
model.add(Activation('tanh'))
return model
5. 判别器
判别器是SGAN模型中最复杂的部分,它有如下双重目标。
- 区分真实样本和伪样本。为此,SGAN判别器使用了sigmoid函数,输出用于二元分类的概率。
- 对于真实样本,还要对其标签准确分类。为此,SGAN判别器使用了softmax函数,输出概率向量——每个目标类别对应一个。
1. 核心判别器网络
我们先来定义核心判别器网络。SGAN判别器模型与DCGAN中实现的基于ConvNet的判别器相似。实际上,直到3×3×128卷积层,它的批归一化和LeakyReLU激活与之前的一直是完全相同的。
在该层之后添加了一个Dropout,这是一种正则化技术,通过在训练过程中随机丢弃神经元及其与网络的连接来防止过拟合。这就迫使剩余的神经元减少它们之间的相互依赖,并得到对基础数据更一般的表示形式。随机丢弃的神经元比例由比例参数指定,在本实现中将其设置为0.5,即mode1.add(Dropout(0.5))。由于SGAN分类任务的复杂性增加,我们使用了Dropout,以提高模型从只有100个有标签的样本中归纳的能力。
def build_discriminator_net(img_shape):
model = Sequential()
model.add(Conv2D(128,kernel_size=3,strides=2,input_shape=img_shape,padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(128,kernel_size=3,strides=2,input_shape=img_shape,padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(128,kernel_size=3,strides=2,input_shape=img_shape,padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Flatten())
model.add(Dropout(0.4))
model.add(Dense(num_classes))
return model
注意,Dropout层是在批归一化之后添加的。出于这两种技不之间的相互作用,这种方法已显示出优越的性能。
另外,请注意前面的网络以一个具有10个神经元的全连接层结束,接下来,我们需要定义从这些神经元计算出的两个判别器输出:一个用于有监督的多分类(使用softmax),另一个用于无监督的二分类(使用sigmoid)。
2.有监督的鉴别器
def build_discriminator_supervised(discriminator_net):
model = Sequential()
model.add(discriminator_net)
model.add(Activation('softmax'))
return model
3. 无监督的判别器
predict(x)这个函数将10个神经元(来自核心判别器网络)的输出转换成一个二分类的真假预测。
def build_discriminator_unsupervised(discriminator_net):
model = Sequential()
model.add(discriminator_net)
def predict(x):
prediction = 1.0 - (1.0 / (K.sum(K.exp(x), axis=-1, keepdims=True) + 1.0))#将真实类别的分布转换为二元真-假率
return prediction
model.add(Lambda(predict))#之前定义的真假输出元
return model
6. 搭建整个模型
接下来,我们将构建并编译判别器模型和生成器模型。注意,有监督损失和无监督损失分别使用categorical_crossentropy和binary_crossentropy损失函数。
def build_sgan(generator, discriminator):
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
discriminator_net = build_discriminator_net(img_shape)#核心判别器网络:这些层在有监督和无监督训练中共享
#构建并编译有监督训练判别器
discriminator_supervised = build_discriminator_supervised(discriminator_net)
discriminator_supervised.compile(
loss='categorical_crossentropy',
metrics=['accuracy'],
optimizer=Adam(lr=0.0002, beta_1=0.5)
)
#构建并编译无监督训练判别器
discriminator_unsupervised = build_discriminator_unsupervised(discriminator_net)
discriminator_unsupervised.compile(
loss='binary_crossentropy',
optimizer=Adam(lr=0.0002, beta_1=0.5)
)
#构建生成器
generator = build_generator(z_dim)
discriminator_unsupervised.trainable = False#生成器训练时,判别器参数保持不变
#构建并编译判别器固定的GAN模型,以训练生成器(判别器使用无监督版本)
sgan = build_sgan(generator, discriminator_unsupervised)
sgan.compile(
loss='binary_crossentropy',
optimizer=Adam(lr=0.0002, beta_1=0.5)
)
7. 训练
以下伪代码概述了SGAN的训练算法。
SGAN训练算法
对每次训练选代,执行以下操作。
- 训练判别器(有监督)。
- 随机取小批量有标签的真实样本(x, y)
- 计算给定小批量的D((x, y))并反向传播多分类损失更新\(\theta^{(D)}\),以使损失最小化。
- 训练判别器(无监督)。
- 随机取小批量无标签的真实样本x。
- 计算给定小批量的D(x)并反向传播二元分类损失更新\(\theta^{(D)}\),以使损失最小化。
- 随机取小批量的随机噪声z生成一小批量伪样本:G(z)=\(x^*\)。
- 计算给定小批量的\(D(x^*)\)并反向传播二元分类损失更新\(\theta^{(D)}\)以使损失最小化。
- 训练生成器。
- 随机取小批量的随机噪声z生成一小批量伪样本:G(z)=\(x^*\)。
- 计算给定小批量的D(\(x^*\))并反向传播二元分类损失更新\(\theta^{(G)}\)以使损失最大化。
结束
supervised_losses = []
iteration_checkpoints = []
def train(iterations, batch_size, sample_interval):
real = np.ones((batch_size, 1))#真实图像的标签:全为1
fake = np.zeros((batch_size, 1))#伪图像的标签:全为0
for iteration in range(iterations):
imgs, labels = dataset.batch_labeled(batch_size)#获取有标签样本
labels = to_categorical(labels, num_classes=num_classes)#独热编码标签
imgs_unlabeled = dataset.batch_unlabeled(batch_size)#获取无标签样本
#生成一批伪图像
z = np.random.normal(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict(z)
#训练有标签的真实样本
d_loss_supervised, accuracy = discriminator_supervised.train_on_batch(imgs, labels)
#训练无标签的真实样本
d_loss_real = discriminator_unsupervised.train_on_batch(imgs_unlabeled, real)
#训练伪样本
d_loss_fake = discriminator_unsupervised.train_on_batch(gen_imgs, fake)
d_loss_unsupervised = 0.5 * np.add(d_loss_real, d_loss_fake)
#生成一批伪样本
z = np.random.normal(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict(z)
#训练生成器
g_loss = sgan.train_on_batch(z, np.ones((batch_size, 1)))
if(iteration + 1) % sample_interval == 0:
#保存判别器的有监督分类损失,以便绘制损失曲线
supervised_losses.append(d_loss_supervised)
iteration_checkpoints.append(iteration + 1)
print("%d [D loss supervised: %.4f, acc.: %.2f%%] [D loss unsupervised: %.4f] [G loss: %f]"
% (iteration + 1, d_loss_supervised, 100 * accuracy, d_loss_unsupervised, g_loss))
sample_image(generator)#输出生成图像的采样
1. 生成图像
def sample_image(generator, image_grid_rows=4, image_grid_columns=4):
z = np.random.normal(0, 1, (image_grid_rows * image_grid_columns, 100))#随机噪声采样
gen_imgs = generator.predict(z)#从随机噪声生成图像
gen_imgs = 0.5 * gen_imgs + 0.5#图像缩放到[0, 1]:[-1, 1]--->[0, 1]
fig, axs = plt.subplots(
image_grid_rows,
image_grid_columns,
figsize=(4, 4),
sharex=True,
sharey=True
)
cnt = 0
for i in range(image_grid_rows):
for j in range(image_grid_columns):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
充分训练后的SGAN的生成器生成的手写数字如下图左所示,为了便于同时比较,DCGAN生成的数字样本如下图右所示。我们可以看到,SGAN生成数字样本明显优于DCGAN生成的数字样本。

2. 训练模型
之所以使用较小的批量,是因为只有100个有标签的训练样本。我们通过反复试验确定迭代次数:不断增加次数,直到判别器的有监督损失趋于平稳,但不要超过稳定点太远(以降低过拟合的风险)。
iterations = 20000
batch_size = 32
sample_interval = 2000
train(iterations, batch_size, sample_interval)
3. 模型训练和测试准确率
在训练过程中,SGAN达到了100%的有监督准确率。尽管这看似很好,但请记住只有100个有标签的样本用于有监督训练——也许模型只是记住了训练数据集。分类器能在多大程度上泛化到训练集中未见过的数据上才是重要的。
x, y = dataset.test_set()
y = to_categorical(y, num_classes=num_classes)
_, acc = discriminator_supervised.evaluate(x, y)
print('Test accuracy: %.2f%%' % (100 * acc))

SGAN能够准确分类测试集中大约93%的样本,为了解这有多了不起,我们对比一下SGAN和全监督分类器的性能。
三、与全监督分类器的对比
为了使比较尽可能公平,我们让全监督分类器使用与训练有监督判别器相同的网络结构。这样做的意图在于,这将能突显出半监督学习GAN对分类器泛化能力的提提高。
#有着与SGAN判别器相同网络结构的全监督分类器
mnist_classifier = build_discriminator_supervised(
build_discriminator_net(img_shape)
)
mnist_classifier.compile(
loss='categorical_crossentropy',
metrics=['acc'],
optimizer=Adam(lr=0.0002, beta_1=0.5)
)
imgs, labels = dataset.training_set()
labels = to_categorical(labels, num_classes=num_classes)
history = mnist_classifier.fit(
imgs,
labels,
batch_size=batch_size,
epochs=30
)
train_result = history.history
trian_loss = train_result['loss']
train_acc = train_result['acc']
epochs = range(1, len(loss) + 1)
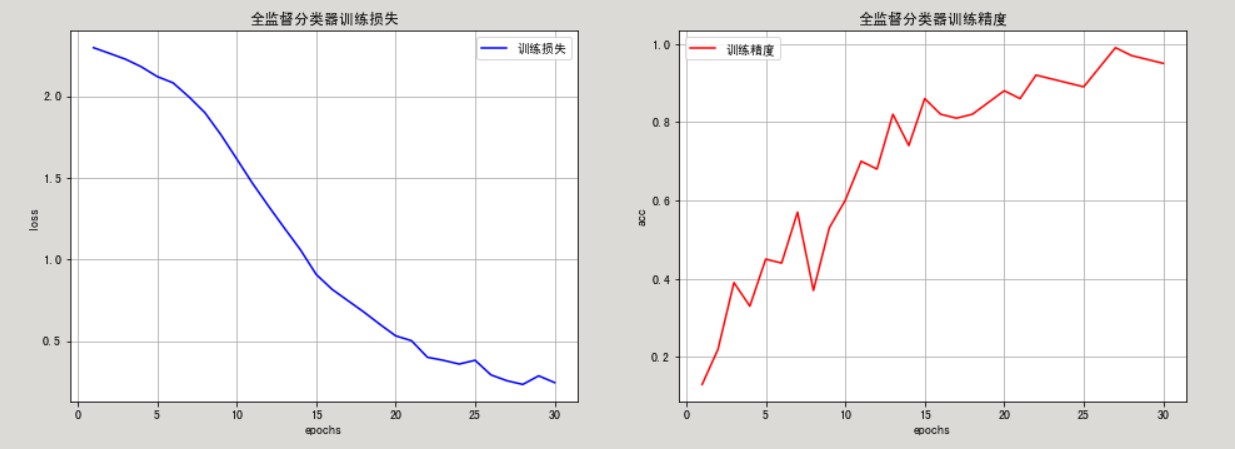
plt.figure(figsize=(16, 12))
plt.subplot(221)
plt.grid()
plt.title('全监督分类器训练损失')
plt.plot(epochs, loss, 'b', label='训练损失')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend(loc='best')
plt.subplot(222)
plt.grid()
plt.title('全监督分类器训练精度')
plt.plot(epochs, acc, 'r', label='训练精度')
plt.xlabel('epochs')
plt.ylabel('acc')
plt.legend(loc='best')
mnist_classifier.evaluate(x, y)

与SGAN的判别器一样,全监督分类器在训练数据集上达到了接近100%的准确率。但是在测试集上它只能正确分类大约70%的样本,比SGAN差了约20个百分点。换句话说,SGAN将训练准确率提高了近30个百分点!
随着训练数据的增加,全监督分类器的泛化能力显著提高。使用相同的设置和训练,使用10000个有标签样本(是最初使用样本的100倍)训练的全监督分类器,可以达到约98%的准确率,不过这不是半监督学习。
四、结论
我们通过教判别器输出真实样本的类别标签,来探索如何把GAN用于半监督学习。可以看到,经过SGAN训练的分类器从少量训练样本中泛化的能力明显优于全监督分类器。
从GAN创新的角度来看,SGAN的主要特点是在判别器训练中使用标签,你可能想知道标签是否也可以用于生成器训练,条件GAN应用而生。
五、小结
- 半监督生成对抗网络(SGAN)的判别器可用来:区分真实样本与伪样本;给真实样本分配正确的类别标签。
- SGAN的目的是将判别器训练成一个分类器,使之可以从尽可能少的有标签样本中获得更高的分类精度,从而减少分类任务对大量标注数据的依赖性。
- 我们将softmax和多元交叉熵损失用于分配真实标签的有监督任务,将sigmoid和二元交叉熵用于区分真实样本和伪样本。
- 我们证明了SGAN对没见过的测试集数据的分类准确率远远优于在相同数量的有标签样本上训练的全监督分类器。