一、函数的递归
# 递归的前提是函数的回溯条件同等条件有规律的
# 递归函数的定义:直接或者之间接的调用自身
# 回溯(分解):就是函数一次次重复的过程,但必须是遵循每一次重复的重复问题的复杂度难度会下降
# 最终会有一个终止条件(分界的出口)
# 递推(合并):就是一次次往回推导的过程
1.1例如:
# 求年纪 # 第一个比第二个的年龄小2岁 第二个比第三个小2 岁 第三个比第四个小2岁 第5个25岁 # 结束条件 n == 1 25 岁 # n=5的时候是几岁 也就是他是第四的小两岁age(4)-2 第四是第三个age(3)-2 第三是第二的age(2)-2 第一25 # 表达式 age(n-1)-2
def age(n): if n == 1: return 25 return age(n-1)-2 res = age(5) print(res)
1.2 求阶乘:
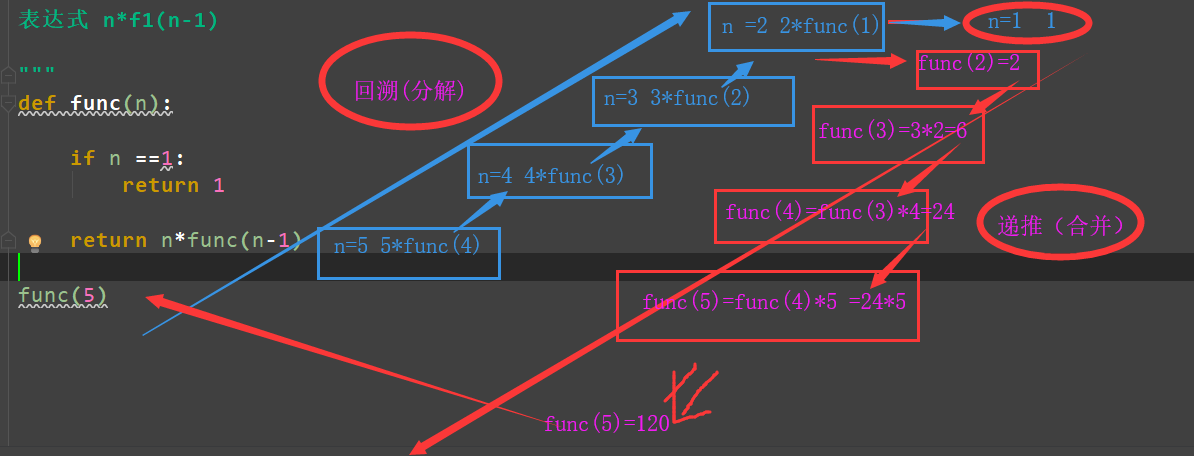
二、算数之二分法(前提必须是一个从小到大排列的迭代对象容器):帮助我们快速的拿到列表中我们想要的值,如果列中的数量少可以使用列表
但是列表中如果数量量很大,再使用fo 循环那就相当的费时。此时我们就可以使用算数二元分法,可以节省时间。
思路:1.将一个列表的长度除//2 整除 middle_index 拿到中间的数的索引
2.我们判断左右两边的值然后进行切分
3.再次调用递归函数 传入一个切分后的列表 再进行切分
# 算数二分法: target_num = 777 l = [1,2,3,4,55,66,77,88,99,777,888,999] def get_num(l, target_num): # 获取中间数的索引 if l is []: print('空值没有办法取值') return middle_index = len(l)//2 # 然后进行比较 左右两边的值 # 1,如果大于get_num>l[middle_num] 》》》切分右列表 if target_num > l[middle_index]: right_num = l[middle_index+1:] # 在调用递归get_num() get_num(right_num,target_num) # 2,如果小于get_num<l[middle_num] 》》》切分左列表 elif target_num < l[middle_index]: left_num = l[0:middle_index] # 调用递归函数循环 get_num(left_num, target_num) # else:最终拿到我们的目标值 else: print('we find it', target_num) get_num(l,target_num)
三、表达式
1.三元表达式
# 1.三元表达式 # 作用是一眼能看出来的可以使用,意思是最对一个if else # 固定语法 值1 if 条件 else 值2 # 如条件满足返回值1 如果条件不成立返回值2 x = 10 y = 20 res =x if x>y else y print(res) is_free = input('请输入是否免费<y/n>:').strip() is_free = '免费'if is_free == 'y' else '收费' print(is_free)
3.2 列表推导式:
# 列表生成式 k = ['tank','nick','oscar','sean'] l = ['tank_sb', 'nick_sb', 'oscar_sb', 'sean_sb','jason_NB'] # 需求一将列表k 元素后面+上_sb res = ["%s_sb"%name for name in k ] print(res) # 里面进行for循环 # 需求2 将列表l中 打印出有_sb的名字 res1 = [name for name in l if name.endswith('_sb')] print(res1) # ['tank_sb', 'nick_sb', 'oscar_sb', 'sean_sb'] # 内部本质也是for循环取出每一个值在交给后面的if 判断 条件成立满做添加到新列表 # 条件不成立 的元素做直接剔除
3.3 字典生成式:
l1 = ['name','password','hobby'] l2 = ['jason','123','DBJ','egon'] # 需求将 l1 行成k:v 健值对 my_dict = {} for k,v in enumerate(l1,1): print(k,v) my_dict[k] = l2[k] print(my_dict) # {1: 'name', 2: 'password', 3: 'hobby'} # 用字典生成式将l2 行成k,v健值对 my_dic = {k:v for k,v in enumerate(l2)} print(my_dic) # {0: 'jason', 1: '123', 2: 'DBJ', 3: 'egon'}
四、匿名函数
# 匿名函数 固定语法: # lambda 参数:返回值(表达式) # 匿名函数通常不会单独使用一般是配合和内置函数一起用 def sum(x,y): return x+y print(sum(10,20)) res = lambda x,y : x+y print(res(10,29))
五、常用的函数内置函数
1.max() 和min()
my_dic = { 'koko':13000, 'tank':30000, 'jason':888888, 'yye':18000} # 需求拿到薪资最高的人名,很显然for 循环拿到的是key 比较的是字母 # 需要用到max()内置函数 res = max(my_dic,key=lambda name:my_dic[name]) print(res) # jason # 求最低min() res1 = min(my_dic,key=lambda x:my_dic[x]) print(res1) # koko
2.map() zip() fiter() reduce() sorted()
2.1 map() 映射
# map()映射 # l = [1,2,3,4,5] # res = list(map(lambda x,:x+1,l)) # print(res) # [2, 3, 4, 5, 6] # 本质基于for 循环
2.2 zip()
# 2.zip() 拉链 # l = [1,2,3] # l2 = ['a','b','c'] # res1 = list(zip(l,l2)) # print(res1) # [(1, 'a'), (2, 'b'), (3, 'c')]
2.3 filter()
# 3.filter() 过滤 l3 = [11,22,33,44,55,66,77] print(list(filter(lambda x:x !=66,l3))) # 基于for循环 # [11, 22, 33, 44, 55, 77]
2.4 reduce()
from functools import reduce l = [1,2,3,4,5,6] print(reduce(lambda x,y:x+y,l,19)) # 19初始值 第一个参数 # 当初始值不存在的情况下 按照下面的规律 # 第一次先获取两个元素 相加 # 之后每次获取一个与上一次相加的结果再相加
2.5 sorted()
# sorted() # 有三个参数(parameter) # 1:iterable 就是可可迭代对象 # 2: key:为重新规定排序的规则 一般为lambda 匿名函数 # 3: reverse False默认升序 将序为True li = [22,-33,11,44,5] print(sorted(li, key=lambda x:abs(x)),) # 按照绝对值来排序 print(sorted(li,reverse=True)) # 降序
# 随机生6位验证码
# 随机生成验证码 import random def s_code(): code = '' # 字符串的形式展示 先定义一个空字符串 for i in range(1,7): num = random.randint(0,9) # 数字 字符串拼接必须是字符串 alf = chr(random.randint(65,90)) # 字母 add = random.choice([num,alf]) # 随机选择其中一个 code = ''.join([code,str(add)]) # 需要转成字符串 return code print(s_code())
# 产生一个随机验证码6位数
def get_num(n):
# 循环六次 打印留个数
code = ''
for i in range(n):
# 第一个为数字
num = str(random.randint(0,9))
# 第二个为大写
alp_lower = chr(random.randint(65,90))
# 第三为小写
alp_upper = chr(random.randint(97,122))
code += random.choice([num,alp_lower,alp_upper])
# print(code)
return code
res = get_num(7)
print(res)