作业来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2696
1.列表,元组,字典,集合分别如何增删改查及遍历。
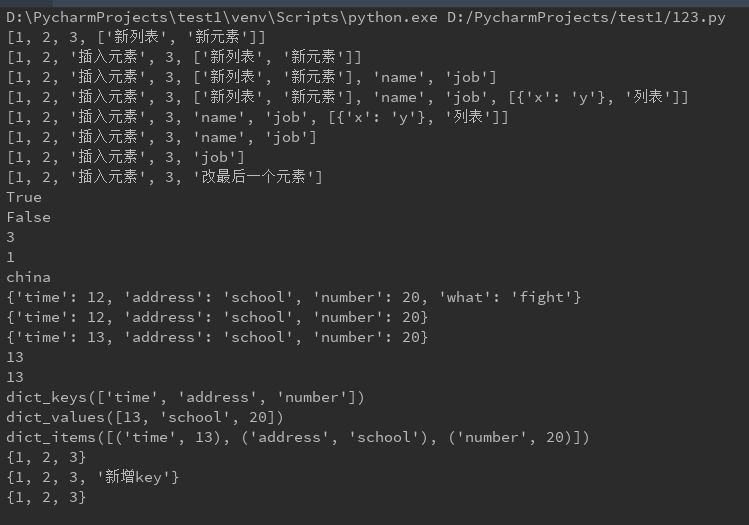
''' 列表的增删改查 ''' List = [1, 2, 3] # 增 append / insert / extend List.append(['新列表', '新元素']) # 将新元素追加到列表末尾 print(List) # --> [1, 2, 3, ['新列表', '新元素']] List.insert(2, '插入元素') # 将新元素插入到列表的指定位置处 print(List) # --> [1, 2, '插入元素', 3, ['新列表', '新元素']] List.extend({'name': 'Tom', 'job': 'CTO'}) # 将集合中的元素拆开放入列表(若该集合为字典则只放入key) print(List) # --> [1, 2, '插入元素', 3, ['新列表', '新元素'], 'name', 'job'] List.extend([[{'x': 'y'}, '列表']]) # 将集合中所有元素拆开放入列表 print(List) # --> [1, 2, '插入元素', 3, ['新列表', '新元素'], 'name', 'job', [{'x': 'y'}, '列表']] # 删 del / pop / remove del List[4] # 删除对应下标的值 print(List) # --> [1, 2, '插入元素', 3, 'name', 'job', [{'x': 'y'}, '列表']] List.pop() # 默认删除最后一个元素 # List.pop(index) # 删除下标index处的元素 print(List) # [1, 2, '插入元素', 3, 'name', 'job'] List.remove('name') # 删除列表中value为 'name' 的值 print(List) # del List #删除整个列表,并且列表变量List也被删除. 打印会报错 # print(List.clear()) # 清空列表中的元素,但是列表的变量还在. --> [] # 改 直接对指定下标的元素赋值即可 List[-1] = '改最后一个元素' # 对倒数第一个元素赋值 print(List) # [1, 2, '插入元素', 3, '改最后一个元素'] # 查 in / not in / index / count print(2 in List) # 查询某元素是否在列表中. --> True print(2 not in List) # 查询某元素是否不再列表中. --> False print(List.index(3, 0, len(List))) # 查询3是否在该列表中(二、三参可略),若在,返回该元素下标,否则报错. --> 3 print(List.count(1)) # 统计1在列表中出现的次数. --> 1 ''' 元组的查询, 因元组无法修改而没有增、删、改 ''' Tuple = ('china', 'beijing') # 查 index 与 count方法与列表相同,本处不举例说明 print(Tuple[0]) # 通过元组的下标访问元素. --> china ''' 字典的增删改查与遍历 ''' Dict = {'time': 12, 'address': 'school', 'number': 20} # 增 直接通过键值对赋值即可添加 Dict['what'] = 'fight' print(Dict) # --> {'time': 12, 'address': 'school', 'number': 20, 'what': 'fight'} # 删 del / clear del Dict['what'] # 删除'what'对应的键值对 # Dict.pop('what') # 功能同上 print(Dict) # -->{'time': 12, 'address': 'school', 'number': 20} # del Dict # 删除整个字典,包括变量 # Dict.clear() # 清空字典,但是字典的变量还在 # 改 直接对已有的键进行赋值 Dict['time'] = 13 # 直接赋值为13 print(Dict) # 查 dict['key'] / dict.get('key') print(Dict['time']) # 直接查询'time'对应的值,此种方式若该key不存在,则报错 print(Dict.get('time')) # 功能同上,但若该key不存在会返回None,而不是报错 # 遍历 print(Dict.keys()) # 遍历key. --> dict_keys(['time', 'address', 'number']) print(Dict.values()) # 遍历value. --> dict_values([13, 'school', 20]) print(Dict.items()) # 遍历键值对. --> dict_items([('time', 13), ('address', 'school'), ('number', 20)]) ''' set的一些性质: 是一组key的集合,但是不会存储value,这一点要和字典作区别 set内的元素无序且不可重复 ''' # 创建一个set,需要提供一个list作为输入 s = set([1, 2, 3]) print(s) # --> {1, 2, 3} # 增 add(key) s.add('新增key') print(s) # --> {1, 2, 3, '新增key'} 新增的元素也许会在集合内的任何位置,每次执行结果也不尽相同! # 删 remove(key) s.remove('新增key') # s.pop() # 删除首个元素 谁在最前面删除谁 print(s) # --> {1, 2, 3}
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
列表:[],有序,可变,可重复,按值存储,序列中的每个元素都分配一个索引,按索引号查找,元素可以是任意类型,可切片
元组:(),有序,与列表类似,但不可变,添加元素时用逗号隔开,按索引号查找,可切片
字典:{},有序,可变容器模型,可存储任意类型对象,按key:value形式存储,但key不可重复,不可切片
3.词频统计
- 下载一长篇小说,存成utf-8编码的文本文件 file
- 通过文件读取字符串 str
- 对文本进行预处理
- 分解提取单词 list
- 单词计数字典 set , dict
- 按词频排序 list.sort(key=lambda),turple
- 排除语法型词汇,代词、冠词、连词等无语义词
-
- 自定义停用词表
- 或用stops.txt
- 输出TOP(20)
- 可视化:词云
# import nltk # nltk.download("stopwords") from nltk.corpus import stopwords stops=set(stopwords.words('english')) #通过文件读取字符串 str,对文本进行预处理 def gettxt(): sep=".,:;?!-_'" txt=open('Crimes and Punishments.txt','r', encoding='UTF-8').read().lower() for ch in sep: txt=txt.replace(ch,' ') return txt #分解提取单词 list txtList=gettxt().split() print(txtList) print('crimes:',txtList.count('crimes')) txtSet=set(txtList) #排除语法型词汇,单词计数字典 set , dict txtSet=txtSet-stops print(txtSet) txtDict={} for word in txtSet: txtDict[word]=txtList.count(word) print(txtDict) print(txtDict.items()) word=list(txtDict.items()) #按词频排序 list.sort(key=lambda),turple word.sort(key=lambda x:x[1],reverse=True) print(word) #输出频率较高的词语top20# for i in range(20): print(word[i]) #排序好的单词列表word保存成csv文件 import pandas as pd pd.DataFrame(data=word).to_csv('Crimes and Punishments.csv',encoding='utf-8')
