引言
【比较官方的简介】数理统计学是一门以概率论为基础,应用性很强的学科。它研究怎样以有效的方式收集、 整理和分析带有随机性的数据,以便对所考察的问题作出正确的推断和预测,为采取正确的决策和行动提供依据和建议。数理统计不同于一般的资料统计,它更侧重于应用随机现象本身的规律性进行资料的收集、整理和分析。
【简单的讲】,就是通过样本分析来推断整体。
【意义或者重要性】在这个大数据时代,数据是非常重要的。怎样挖掘数据内部的规律或者隐含的信息,变得尤为重要。当时我们是不可能获得整体的数据的,所以我们只能通过抽取样本,进而通过样本来推断整体的规律。
目录
一、引言:
二、总体与样本:
三、统计量——随机变量的数字特征:
1、均值、方差
2、矩、协方差、相关性与协方差矩阵
3、距离与相似系数
4、抽样分布定理
四、常用分布:
一、引言:
二、点估计——矩估计法:
三、点估计——极大似然估计:
四、估计量的优良性准则
五、区间估计——正态分布
1、引入
2、单个正态总体参数的区间估计
3、两个正态总体的区间估计
六、区间估计——非正态分布:
1、大样本正态近似法
2、二项分布
3、泊松分布
一、引言:
二、正态总体均值的假设检验
1、单正态总体 N(μ, σ2)均值 μ 的检验
(1) 双边检验 H0: μ = μ0;H1: μ≠μ0
(2) 单边检验 H0: μ = μ0;H1: μ>μ0
2、两个正态总体 N(μ1, σ12) 和 N(μ2, σ22)均值的比较
(1) 双边检验 H0: μ1 = μ2;H1: μ1≠μ2
(2) 单边检验 H0: μ1 >= μ2;H1: μ1<μ2
(3) 单边检验 H0: μ1 <= μ2;H1: μ1>μ2
三、正态总体方差的检验
1、单个正态总体方差的 χ2 检验
(1) H0: σ2 =σ02;H1: σ2 ≠σ02
(2) H0: σ2 =σ02;H1: σ2 >σ02
(3) H0: σ2 ≤σ02;H1: σ2 > σ02 (同2.)
2、两正态总体方差比的 F 检验
(1). H0: σ12 = σ22;H1: σ12 ≠ σ22.
(2) H0: σ12 = σ22;H1: σ12> σ22
(3) H0: σ12 ≤ σ22;H1: σ12> σ22
一、引言
4、估计与预测
(1) E(y0)的估计
(2) y0的预测区间
三、广义线性回归模型
四、非线性回归模型
一、引言
第一章、样本与统计量
本讲首先介绍了样本与统计量的基本概念,包括:总体、个体、样本、总体分布与样本分布;然后介绍了统计量的概念和几个常见的统计量:样本均值、方差、标准差、 k 阶原点矩和k 阶中心矩;最后介绍了抽样分布的概念与抽样分布定理。
一、引言:
由于大量随机现象必然呈现出其规律性,因而从理论上讲,只要对随机现象进行足够多次的观察,随机现象的规律性就一定能够清楚地呈现出来。但是,客观上只允许我们对随机现象进行次数不多的观察或试验,也就是说:我们获得的只能是局部的或有限的观察资料(即样本)。
数理统计的任务就是研究怎样有效地收集、整理和分析所获得的有限资料,并对所研究的问题尽可能地给出精确而可靠的推断。现实世界中存在着形形色色的数据,分析这些数据需要多种多样的方法。
因此,数理统计中的方法和支持这些方法的相应理论是相当丰富的。概括起来可以归纳成两大类。
参数估计: 根据数据,对分布中的未知参数 进行估计;
假设检验: 根据数据,对分布的未知参数的某种假设进行检验。
参数估计与假设检验构成了统计推断的两种基本形式,这两种推断渗透到了数理统计的每个分支。
【简单的讲】我们希望通过(有限的)样本及其统计量等信息去分析样本(的分布等),进而(通过参数估计和假设检验)去推断和检证整体的规律。
二、总体与样本:
1、总体、个体与样本:
在数理统计中,称研究问题所涉及对象的全体为总体,总体中的每个成员为个体。 例如: 研究某工厂生产的某种产品的废品率,则这种产品的全体就是总体,而每件产品都是一个个体。
实际上,我们真正关心的并不一定是总体或个体本身,而真正关心的是总体或个体的某项数量指标。 如:某电子产品的使用寿命,某天的最高气温,加工出来的某零件的长度等数量指标。因此,有时也将总体理解为那些研究对象的某项数量指标的全体。
为评价某种产品质量的好坏,通常的做法是:从全部产品中随机(任意)地抽取一些样品进行观测(检测),统计学上称这些样品为一个样本。 同样,我们也将样本的数量指标称为样本。因此,今后当我们说到总体及样本时,既指研究对象又指它们的某项数量指标。
【例1】研究某地区 N 个农户的年收人。 在这里,总体既指这 N 个农户,又指我们所关心的 N个农户的数量指标──他们的年收入( N 个数字)。 如果从这 N 个农户中随机地抽出 n 个农户作为调查对象,那么,这 n 个农户以及他们的数量指标──年收入( n个数字)就是样本。
【注意】上例中的总体是直观的,看得见、摸得着的。但是,客观情况并非总是这样。如【例2】
【例2】用一把尺子测量一件物体的长度。 假定 n 次测量值分别为X1,X2 ,…,Xn。显然,在该问题中,我们把测量值X1,X2 ,…,Xn看成样本。但总体是什么呢?
事实上,这里没有一个现实存在的个体的集合可以作为上述问题的总体。可是,我们可以这样考虑,既然 n 个测量值 X1,X2 ,…,Xn 是样本,那么,总体就应该理解为一切所有可能的测量值的全体。
又如:为研究某种安眠药的药效,让 n 个病人同时服用这种药,记录服药者各自服药后的睡眠时间比未服药时增加睡眠的小时数 X1,X2,…,Xn, 则这些数字就是样本。 那么,什么是总体呢?
设想让某个地区(或某国家,甚至全世界)所有患失眠症的病人都服用此药,则他们所增加睡眠的小时数之全体就是研究问题的总体。
2、总体分布
对一个总体,如果用X表示其数量指标,那么,X的值对不同的个体就取不同的值。因此,如果我们随机地抽取个体,则X的值也就随着抽取个体的不同而不同。 所以,X是一个随机变量! 既然总体是随机变量X,自然就有其概率分布。我们把X的分布称为总体分布。 总体的特性是由总体分布来刻画的。因此,常把总体和总体分布视为同义语。
【例 3 (例 l 续)】在例 l中,若农户年收入以万元计,假定 N户的收入X只取以下各值: 0.5, 0.8, l.0, 1.2和1.5。取上述值的户数分别n1, n2, n3, n4和n5 (n1+n2+n3+n4+n5=N)。则X为离散型分布,分布律为:
|
X |
0.5 |
0.8 |
1 |
1.2 |
1.5 |
|
p k |
n1/N |
n2/N |
n3/N |
n4/N |
n5/N |
【例4 ( 例2续 )】在例2中,假定物体真实长度为μ(未知)。一般说来,测量值X就是总体,取μ 附近值的概率要大一些,而离μ 越远的值被取到的概率就越小。 如果测量过程没有系统性误差,则X取大于μ 和小于μ 的概率也会相等。
在这种情况下,人们往往认为X 服从均值为μ,方差为σ2 的正态分布。σ2反映了测量的精度。于是,总体X的分布为 N(μ ,σ2)。
【说明】这里有一个问题,即物体长度的测量值总是在其真值 μ的附近,它不可能取负值。 而正态分布取值在(-∞,∞)上。那么,怎么可以认为测量值X服从正态分布呢? 回答这个问题,有如下两方面的理由。
(1)对于X∼N(μ,σ2), P{μ-3σ<X<μ+3σ}=0.9974. 即 X 落在区间(μ-3σ,μ+3σ)之外的概率不超过 0.003, 这个概率非常小。X 落在(μ-4σ,μ+4σ)之外的概率就更小了。
例如:假定物体长度μ =10厘米,测量误差为0.01厘米,则σ2=0.012。 这时((μ-3σ,μ+3σ)=(9.97,10.03)。于是,测量值落在这个区间之外的概率最多只有0.003,可忽略不计。 可见,用正态分布 N(10,0.012)去描述测量值X是适当的。完全可认为:X 根本就不可能取到负值;
(2)另外,正态分布取值范围是(-∞,∞),这样还可以解决规定测量值取值范围上的困难。
如若不然, 就需要用一个定义在有限区间(a,b)取值的随机变量来描述测量值X。那么, a和b到底取什么值呢?测量者事先很难确定。 再退一步,即使能够确定出a和b,却仍很难找出一个定义在 (a,b) 上的非均匀分布用来恰当地描述测量值。与其这样,还不如干脆就把取值区间放大到(-∞,∞),并用正态分布来描述测量值。这样,既简化了问题,又不致引起较大的误差。
【离散分布和连续分布的说明】
● 如果总体所包含的个体数量是有限的, 则 称该总体为有限总体。有限总体的分布显然是离散型的,如【例3】。
● 如果总体所包含的个体数量是无限的,则 称该总体为无限总体。限总体的分布可以 是连续型的,如【例4】;也可是离散型的。
但是,在数理统计中,研究有限总体比较困难。因为其分布是离散型的,且分布律与总体中所含个体数量有关系。通常在总体所含个体数量比较大时,将其近似地视为无限总体,并用连续型分布逼近总体的分布,这样便于进一步地做统计分析。如【例5】
【例5】研究某大城市年龄在1岁到10岁之间儿童的身高。
显然,不管城市规模多大,这个年龄段的儿童数量总是有限的。因此,该总体X只能是有限总体。总体分布只能是离散型分布。然而,为便于处理问题,我们将有限总体近似地看成一个无限总体,并用正态分布来逼近这个总体的分布。 当城市比较大,儿童数量比较多时,这种逼近所带来的误差,从应用观点来看,可以忽略不计。
【样本的二重性】样本X1,X2,…,Xn既被看成数值,又被看成随机变量
● 假设 X1, X2, …, Xn 是总体X中的样本,在一 次具体的观测或试验中,它们是一批测量值, 是已经取到的一组数。这就是说,样本具有数的属性。
● 由于在具体试验或观测中,受各种随机因素 的影响,在不同试验或观测中,样本取值可 能不同。因此,当脱离特定的具体试验或观 测时,我们并不知道样本 X1,X2,…,Xn 的具 体取值到底是多少。因此,可将样本看成随机变量。故样本又具有随机变量的属性。
【例 6 (例2续)】在前面测量物体长度的例子中,如果我们在完全相同的条件下,独立地测量了n 次,把这 n 次测量结果,即样本记为 X1,X2,…,Xn .
那么,我们就认为:这些样本相互独立,且有相同的分布;其分布与总体分布 N(μ ,σ2)相同。
【将上述结论推广到一般的分布】如果在相同条件下对总体 X 进行 n 次重复、独立观测,就可以认为所获得的样本X1,X2,…,Xn是 n 个独立且与总体 X 有同样分布的随机变量。在统计文献中,通常称相互独立且有相同分布的样本为随机样本或简单样本, n 为样本大小或样本容量。
3、样本分布
既然样本 X1,X2,…,Xn 被看作随机向量,自然需要研究其联合分布。
假设总体 X 具有概率密度函数 f (x),因样本 X1,X2,…,Xn独立同分布于 X,于是,样本的联合概率密度函数(也叫似然函数(likehood))为:

【例7】 假设某大城市居民的收入 X 服从正态分布N(μ ,σ2), 概率密度为

现从总体 X 中随机抽取样本 X1,X2,…,Xn ,因其独立同分布于总体 X,即: Xi ∼ N(μ ,σ2), i=1,2,…,n. 于是,样本X1,X2,…,Xn 的联合概率密度为

三、统计量——随机变量的数字特征:
由样本推断总体的某些情况时,需要对样本进行“加工”,构造出若干个样本的已知 (确定)的函数,其作用是把样本中所含的某一方面的信息集中起来。这种不含任何未知参数的样本的函数称为统计量。它是完全由样本所决定的量。
1、均值、方差:
(1)数学期望:


(2)方差:
【总体】

式(1.65)证明如下:方差等于平方均值减去均值的平方
Var(x)= E[ (x-Ex)²]
= E[x²-2xEx+(Ex)²]
= E(x²)-2ExEx+E(Ex)²
=E(x²)-2(Ex)²+(Ex)²
= E(x²)-[E(x)]²
【样本】注意方差不是除n,而是(n-1)

(3)几种常用随机变量分布的期望和方差:

2、矩、协方差、相关性与协方差矩阵
(1)矩与中心化、标准化数据:
【总体】

![]()
【样本】
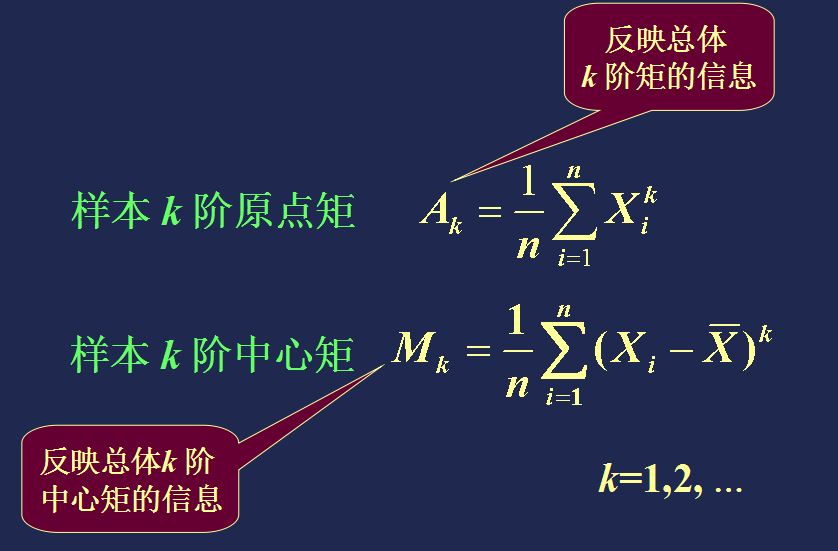



(2)协方差与相关系数:



(3)协方差矩阵与相关矩阵:


【协方差矩阵和相关系数矩阵的关系】由二者的定义公式可知,经标准化的样本数据的协方差矩阵就是原始样本数据的相关矩阵。 这里所说的标准化指正态化,即将原始数据处理成均值为0,方差为1的标准数据。
3、距离与相似系数


【证明第(3)和(4)条之间的关系】
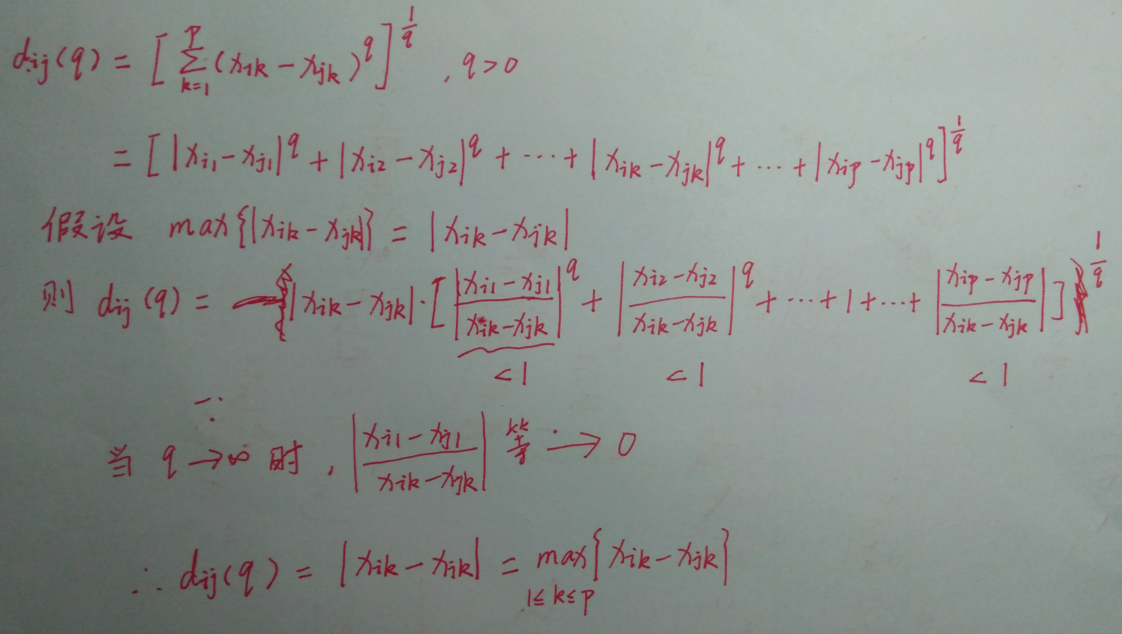


4、抽样分布
统计量既然依赖于样本,而后者又是随机变量,故统计量也是随机变量,有一定的分布,这个分布称为统计量的抽样分布。
【抽样分布定理】设 X1,X2,...,Xn是来自均值为μ ,方差为 σ2 的总体的样本,则当 n 充分大时, 近似地有:

证明如下:

【正态分布标准化定理】若X~N(μ,σ2),则 Z = (X-μ)/σ ~ N(0,1)
【中心极限定理】设 X1,X2,...,Xn是来自均值为μ ,方差为 σ2 的总体的样本,则当 n 充分大时, 近似地有:

【应用1】可轻易的计算随机样本均值的概率分布值

【应用2】

【例1】用机器向瓶子里灌装液体洗涤剂,规定每瓶装 μ 毫升。但实际灌装量总有一定波动。假定灌装量的方差 σ2=1,如果每箱装这样的洗涤剂 25 瓶。求这 25 瓶洗净剂的平均灌装量与标定值 μ 相差不超过0.3毫升的概率;又如果每箱装50瓶时呢?
解:记一箱中 25 瓶洗净剂灌装量为 X1,X2,..., X25 是来自均值为μ , 方差为1的总体的随机样本。根据抽样分布定理1,近似地有
![]()

四、常用分布:
1、χ2 分布:它是由正态分布派生出来的一种分布。
【定义】 设 X1, X2, …, Xn 相互独立,且均服从正态分布 N(0, 1), 则称随机变量
![]() 服从自由度为 n 的卡方分布,记成χn2 。
服从自由度为 n 的卡方分布,记成χn2 。
其实卡方分布是一种伽玛分布(α=n/2,Β=1/2时),详见【附伽玛分布和函数内容】

【附伽玛分布和函数内容】具体详见文章【LDA-math-神奇的Gamma函数】
其实伽玛函数可以看成阶乘在实数上的扩展。

【性质】如下
对于性质(1),可由正态分布的标准化公式推出,即Zi = (Xi-μ)/σ ~ N(0,1),则Σ(Zi2)符合卡方分布。
对于性质(3),由于卡方分布是伽玛分布的特殊情况,则可直接由伽玛分布的均值和方差算出。

![]()
【分布密度函数】
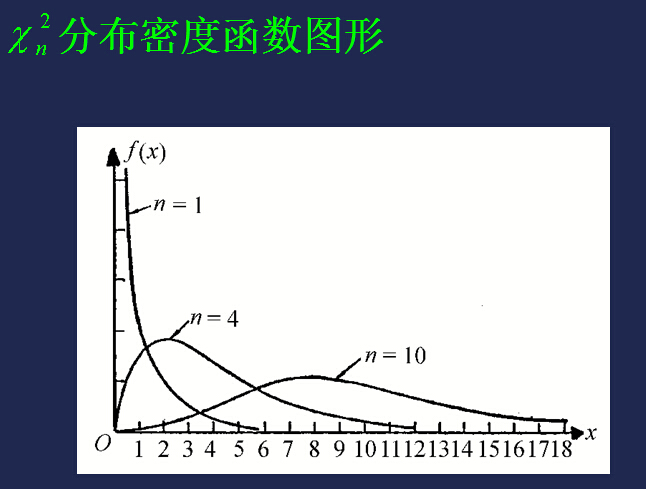
【分布分位点】具体数值可以查表

2、t 分布:
【定义】 设 X ~N(0, 1) , Y ~χn2 , 且 X与Y 相互独立,则称随机变量
![]() 为服从自由度 n 的 t 分布,记为 T ~ tn。
为服从自由度 n 的 t 分布,记为 T ~ tn。

可以看出t分布的概率密度函数是偶函数,即 f(t) = f(-t)


t1-α(n) = -tα(n)

3、F分布:
【性质1】若 X ~ Fm,n,则 Y = X -1 ~ Fn,m



【性质2】


在通常 F 分布表中,只对α 比较小的值,如α = 0.01, 0.05, 0.025及0.1等列出了分位点。但有时我们也需要知道α 比较大的分位点,它们在 F 分布表中查不到。这时我们就可利用分位点的关系式(1)把它们计算出来。
【例】对m=12, n=9, α=0.95, 我们在 F 分布表中查不到 F12,9(0.95),但由(1)式,知

【性质3】若X ~ tn , 则X2 ~ F1,n。
4、正态总体样本均值与样本方差的分布
性质(4)是由性质(1)和(2)共同推出的。定理(1)(2)(4)基本上就是后面参数估计和假设检验的核心。

【例】在设计导弹发射装置时,重要内容之一是研究弹着点偏离目标中心的距离的方差。 对于某类导弹发射装置,弹着点偏离目标中心的距离服从 N(μ,σ2),这里σ2 = 100米2。 现在进行了25次发射试验,用 S2 记这25次试验中弹着点偏离目标中心的距离的样本方差。 求: S2 超过50米2的概率。
