什么是IK分词器 ?
分词:即把一-段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱中国”会被分为"我"、“爱”、“中”、“国”,这显然是不符合要求的,所以我们需要安装中文分词器 ik 来解决这个问题。
IK提供了两个分词算法: ik_ smart 和 ik_ max_ word ,其中ik_ smart为最少切分, ik_ max_ _word为最细粒度划分!
ik 下载
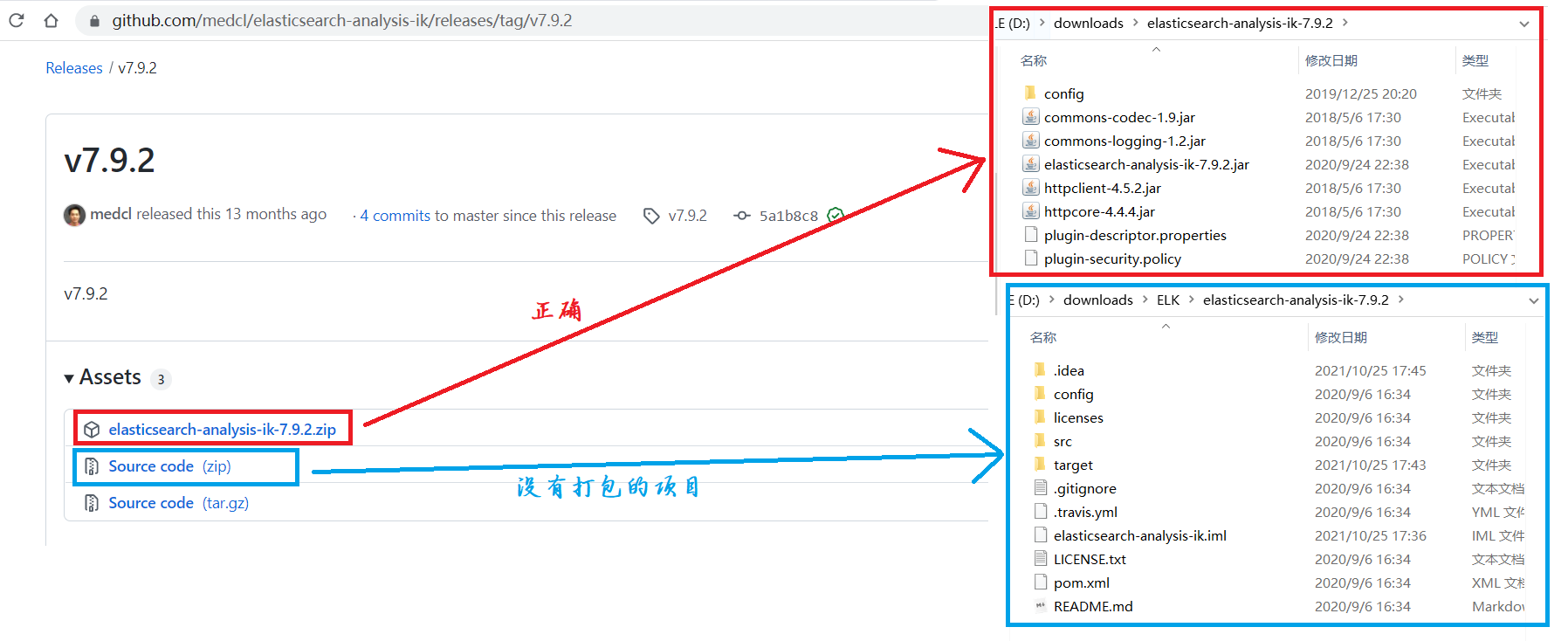
ik分词器下载:https://github.com/medcl/elasticsearch-analysis-ik
注意:版本和Elasticsearch一致不要下载错了(我测试的时候下载错了>_<,路径:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.9.2)
{下载没有打包的项目,需要你打包, 通过命令行进入ik分词pom所在目录下,依次输入 mvn clean、mvn compile、mvn package 命令,(可能会出现一些环境依赖的问题,具体看个人电脑)}
ik 使用
解压放置 Elasticsearch 的插件中

重启 elasticsearch ,可以看到 ik 分词器被加载了。
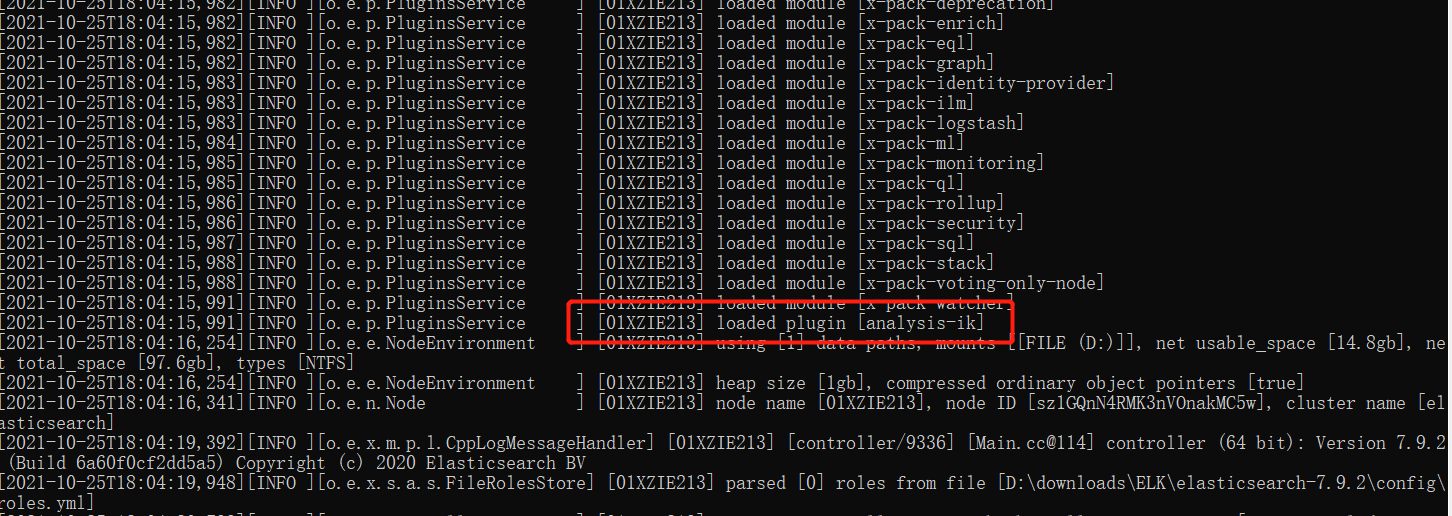
可以通过
elasticsearch-plugin list这个命令来加载进来的插件

ik 测试
IK 提供了两个分词算法:ik_ smart 和 ik_ max_ word ,其中ik_ smart为最少切分,ik_ max_ _word为最细粒度划分!
如果使用中文:推荐IK分词器
两个分词算法:ik_smart(最少切分),ik_max_word(最细粒度划分)
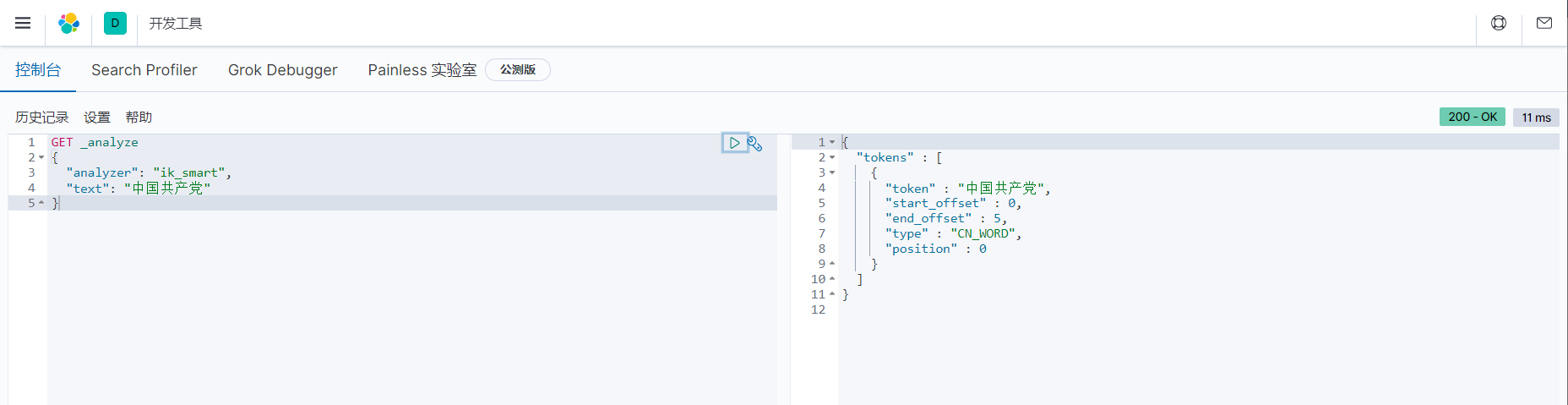
ik_smart 最少切分(博客中不允许出现那几个字,所以处理了一下)
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国¥¥¥"
}
ik_max_word 最细粒度划分(博客中不允许出现那几个字,所以处理了一下)
GET _analyze
{
"analyzer": "ik_max_word ",
"text": "中国¥¥¥"
}
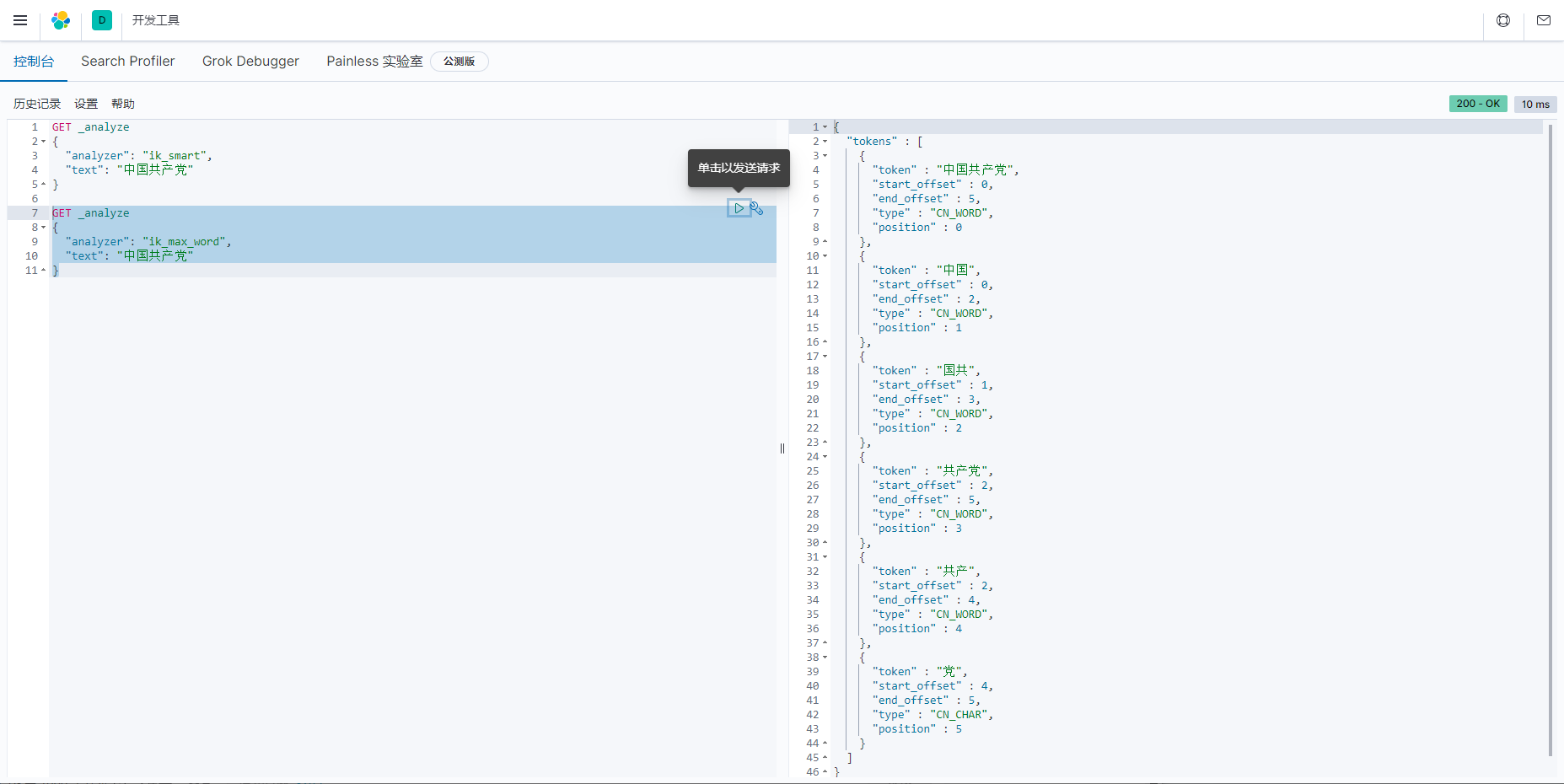
总结:ik_max_word 最细粒度划分!穷尽词库的可能!字典!
ik 词典自定义配置
为什么需要修改 ik 词典配置?
举例:业务需要将 ”我要洗澡皮肤好好“ 这个词必须分为 {”我要洗澡“、”皮肤好好“} 的结果
默认的分词:并不是我们需要的结果,所以
需要创建自己的词典

发现的问题:当这种自己(或者业务)需要的词,需要自己加到我们的分词器的字典中!(my.dic 文件需要自己创建)
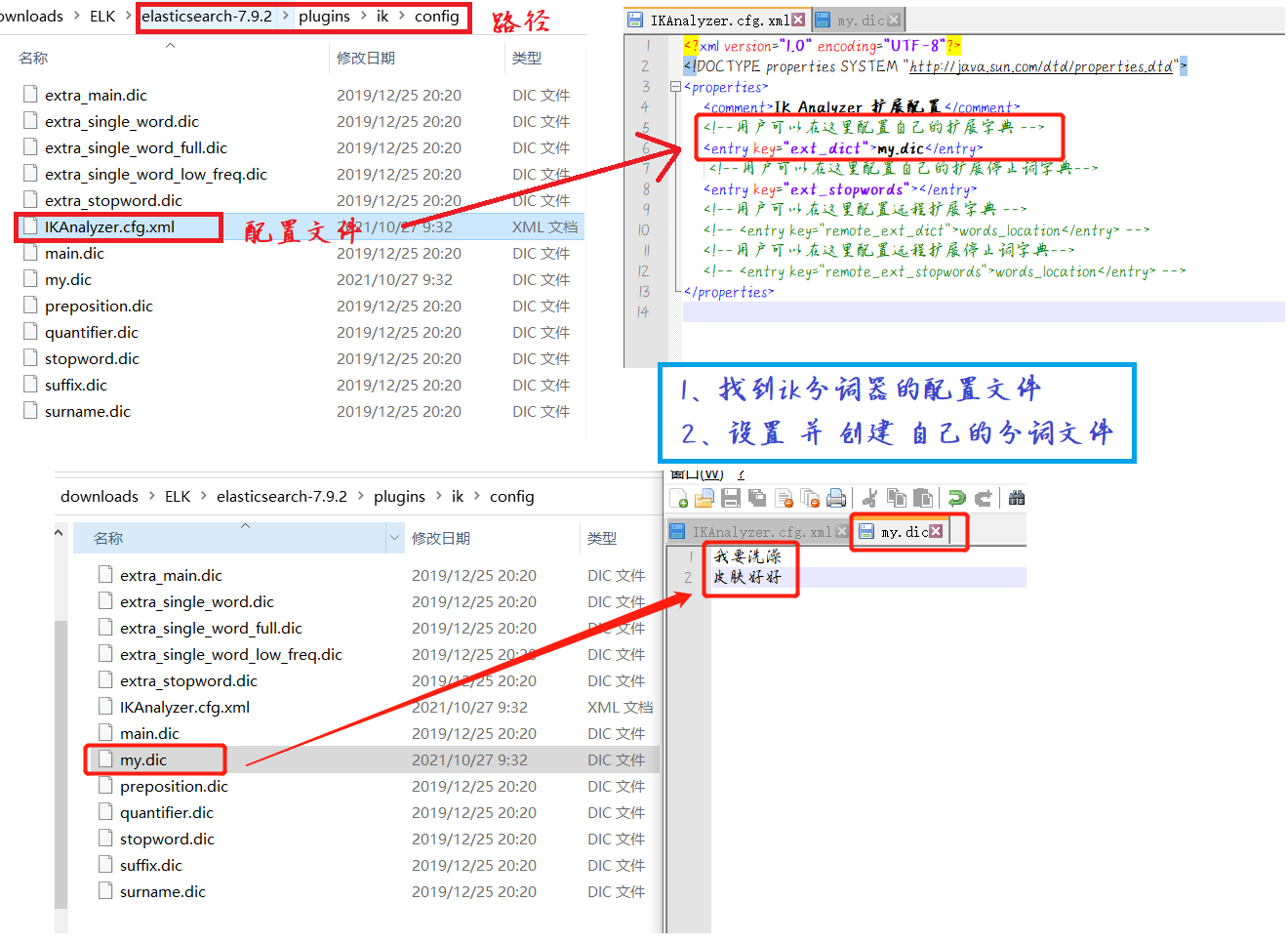
重启 elasticsearch,再次分词

总结:需要自己配置的分词,就在自己定义的dic文件中进行配置即可!