打通实时数据处理
1).流程图
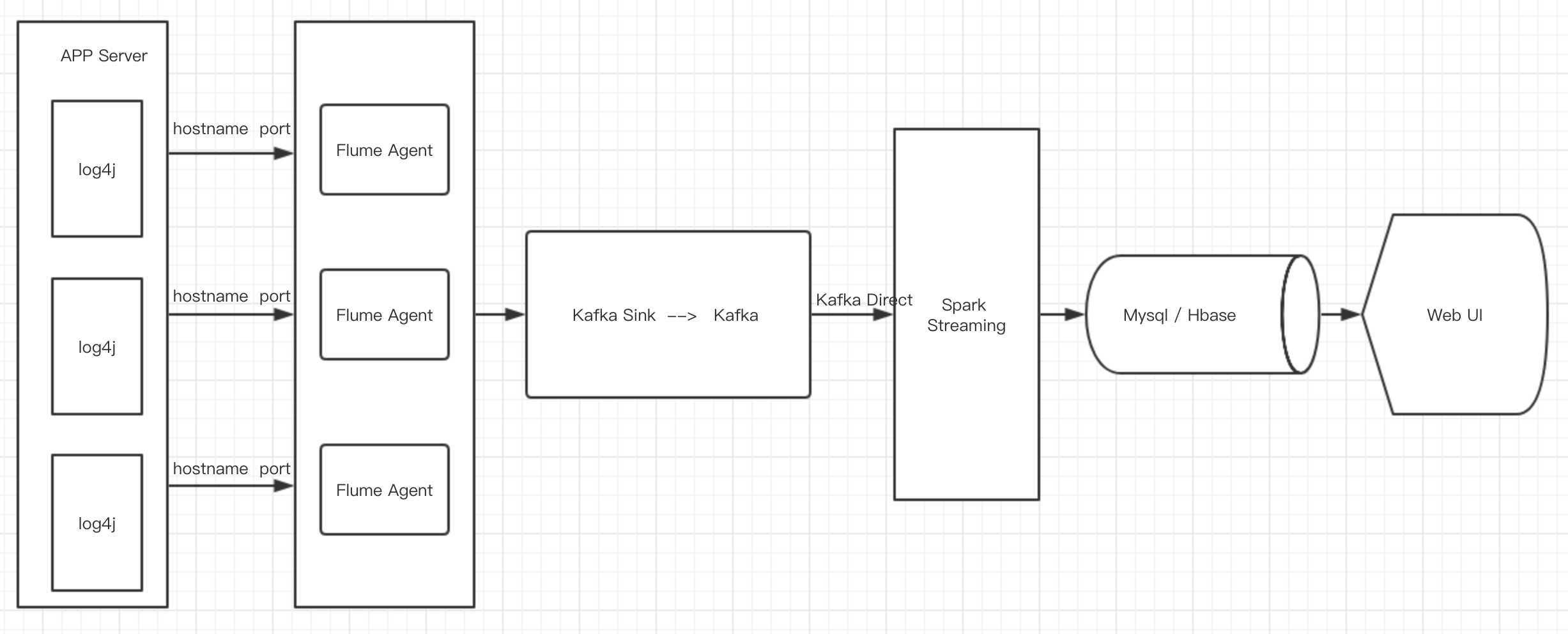
LoggerGenerator
package Scala
import java.time
import org.apache.log4j.Logger
object LoggerGenerator {
def main(args: Array[String]): Unit = {
val logger:Logger = Logger.getLogger(LoggerGenerator.getClass.getName)
// 人物列表
val nameList = List("Wade", "Marry", "Paul", "James", "Mike", "Tomas")
while (true) {
Thread.sleep(100)
val timeStamp_value = time.LocalDate.now()
val index = new util.Random().nextInt(5)
val value = new util.Random().nextInt(100)
logger.info(timeStamp_value + " " + nameList(index) + " " + value)
}
}
}
log4j.properties
log4j.rootLogger=INFO,stdout,flume
log4j.appender.stdout= org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout= org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%p %d{yyyy-MM-dd HH:mm:ss} %c [%t] %m%n
#...
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = localhost
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
flume.conf
#TODO flumeConf for log4j to Flume # Name the components on this agent log4jtoflume.sources = avro-source log4jtoflume.channels = memory-channel log4jtoflume.sinks = kafka-sink # configure for sources log4jtoflume.sources.avro-source.type = avro log4jtoflume.sources.avro-source.bind = localhost log4jtoflume.sources.avro-source.port = 41414 # configure for channels log4jtoflume.channels.memory-channel.type = memory log4jtoflume.channels.memory-channel.capacity = 1000 log4jtoflume.channels.memory-channel.transactionCapacity = 100 # configure for sinks log4jtoflume.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink log4jtoflume.sinks.kafka-sink.topic = streamingTopic log4jtoflume.sinks.kafka-sink.brokerList = bigdata:9092 log4jtoflume.sinks.kafka-sink.batchSize = 20 # connect log4jtoflume.sinks.kafka-sink.channel = memory-channel log4jtoflume.sources.avro-source.channels = memory-channel
Kafka
kafka-topics.sh --create --zookeeper bigdata:2181 --partitions 2 --replication-factor 1 --topic streamingTopic
streaming code
package Scala
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{StreamingContext,Seconds}
import org.apache.spark.streaming.kafka010._
object streamingCode {
def main(args: Array[String]): Unit = {
if (args.length != 2){
System.err.print("Usage: streamingCode <brokerList> <topics>")
}
val Array(brokerList, topics) = args
val conf = new SparkConf().setMaster("local[2]").setAppName("realTimeStreaming")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map [String ,Object](
"bootstrap.servers" -> brokerList,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group_id_1",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topic = Array(topics)
val streamLog4j = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topic, kafkaParams))
streamLog4j.map(x => x.value()).count().print()
ssc.start()
ssc.awaitTermination()
}
}