揭秘HDFS:
=====================================================
HDFS基础模型:

1、分布式存储系统HDFS(Hadoop Distributed File System)分布式存储层
2、资源管理系统YARN(Yet Another Resource Negotiator)集群资源管理层
3、分布式计算框架MapReduce分布式计算层
1):模式分类
1、单机模式(Standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。
在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。
因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
2、伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。
该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
5个进程的介绍http://www.aboutyun.com/thread-7088-1-1.html
3、全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
评论:意思是说 master 上看到 namenode,jobtracer,secondarynamenode 可以安装在master节点,也可以单独安装。
slave节点能看到 datanode 和 nodeManage
HDFS 的起源:
源于Google的GFS论文 发表于2003年10月 HDFS是GFS的克隆版!
什么是GFS? 详细参考地址
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。
它运行于廉价的普通硬件上,并提供容错功能。
它可以给大量的用户提供总体性能较高的服务。
GFS 也就是 google File System,Google公司为了存储海量搜索数据而设计的专用文件系统。
HDFS 简介:
HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统)是一个高度容错性的系统,适合部署在廉价的机器上。
HDFS 能提供高吞吐量的数据访问,适合那些有着超大数据集(largedata set)的应用程序。
核心:
NameNode:主机器上
DataNode:子机器上
SecondaryNameNode:(NameNode的快照)
可以在master机器上也可以是单独一台机器
HDFS是一个主从结构(master/slave),一个HDFS集群由一个名字节点(NameNode)和多个数据节点(DataNode)组成。
这两个文件和 VERSION 存在安装目录下的 hdfs/name/current 文件夹下:
#Mon Feb 06 23:54:55 CST 2017
namespaceID=457699475 #命名空间,hdfs格式化会改变命名空间id,当首次格式化的时候datanode和namenode会产生一个相同的namespaceID,
然后读取数据就可以,如果你重新执行格式化的时候,namenode的namespaceID改变了,
但是datanode的namespaceID没有改变,两边就不一致了,如果重新启动或进行读写hadoop就会挂掉。
解决方案:
1、推荐方式
hdfs namenode -format -force 进行强制的格式化会同时格式化 namenode 和 datanode
2、不推荐但是也可以实现
进入每个子机器,之后删除HDFS和tmp文件! 删除之前旧版本!
HDFS的优点(设计思想):
1、高容错性
HDFS 认为所有计算机都可能会出问题,为了防止某个主机失效读取不到该主机的块文件,它将同一个文件块副本分配到其它某几个主机上,如果其中一台主机失效,可以迅速找另一块副本取文件。
副本存放策略:
数据自动保存多个节点;
备份丢失后,自动恢复。
2、海量数据的存储
非常适合上T B级别的大文件或者一堆大数据文件的存储
3、文件分块存储
HDFS 将一个完整的大文件平均分块(通常每块(block)128M)存储到不同计算机上,这样读取文件可以同时从多个主机取不同区块的文件,多主机读取比单主机读取效率要高得多得多。
block的大小,我们实际可以自己控制!
4、移动计算
在数据存储的地方进行计算,而不是把数据拉取到计算的地方,降低了成本,提高了性能!
5、流式数据访问
一次写入,并行读取。不支持动态改变文件内容,而是要求让文件一次写入就不做变化,要变化也只能在文件末添加内容。
什么是流式数据?
水库中所有的水可以理解成一个批式数据!
水龙头的水,是一股一股留下来的,我们可以理解成流式数据!
如果我们要统计某个文件的数据,会有两种方式:
1、把文件中所有的数据 读取到内存中,之后再进行计算,这样就有个延迟,因为我们需要等待所有数据读取完毕!
2、文件中的数据读取一点,计算一点!这样就没有了延迟,而且还提升了数据的吞吐量!
客户端在写入时,为保证最大吞吐量,客户端会将数据先缓存到本地文件,当客户端缓存的数据超过一个block大小时,会向NN申请创建block,将数据写到block里。
在往block的多个副本写入数据时,HDFS采用流水线复制的方式,比如block的三个副本在A、B、C上,客户端将数据推送给最近的A;
A收到数据后立即推送给B、B推送给C,等所有副本写入成功后,向客户端返回写入成功,当文件所有的block都写入成功后,客户端向NS请求更新文件的元信息。
6、可构建在廉价的机器上
通过多副本提高可靠性,提供了容错和恢复机制。
HDFS 可以应用在普通PC 机上,这种机制能够让一些公司用几十台廉价的计算机就可以撑起一个大数据集群。
小例子:
比如有一个100G的文件 需要存在HDFS中,那么不可能存在一个节点上,因为存储数据的这个节点一旦宕机,数据就会丢失!
那么是不是可以把这个100G的文件分几份进行存储!
比如:A节点存一份 B节点存一份 C节点存一份???
这样每个节点的压力都比较大,因为100G的文件还是比较大的,需要占用很大的带宽!(网络IO)
这时候,HDFS就是采用了分块存储的方法!
把100G的这个文件分成了很多块,每个块是128M,之后把每个块存放在不同的节点上!
在我们的主机上会有两份记录:
01、一个存储文件被分成了几块
02、这几块都在那些节点上
HDFS 的核心元素:
NameNode:
文件的真正存储是在DataNode!子机器中!Master是管理者!
作用:
01、它是一个管理文件的命名空间
02、协调客户端对文件的访问
03、记录每个文件数据在各个DataNode上的位置和副本信息
文件解析:
version :是一个properties文件,保存了HDFS的版本号。
editlog :任何对文件系统数据产生的操作,都会被保存!
fsimage /.md5:文件系统元数据的一个永久性的检查点,包括数据块到文件的映射、文件的属性等。
seen_txid :非常重要,是存放事务相关信息的文件
什么是FSImage和EditsLog:
HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。
问题?
01、一个文件存储在哪些DataNode节点?
02、又存在DataNode节点的哪些位置?
这些描述了文件存储的节点,以及具体位置的信息(元数据信息(metadata))由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。
03、HDFS是如何及时更新这些metadata的呢?
FsImage 和 Editlog是HDFS 的核心数据结构。
这些文件的损坏会导致整个集群的失效。
因此,名字节点可以配置成支持多个 FsImage 和 EditLog 的副本。任何 FsImage 和 EditLog 的更新都会同步到每一份副本中。

FsImage 文件:
01、FsImage文件包含文件系统中所有的目录和文件inode的序列化形式,每个Inode是一个文件或目录的元数据的内部表示,
并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块,对于目录、则存储修改时间、权限和配额元数据
02、FsImage文件没有记录块存储在哪个数据节点,而是由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群中,数据节点会把自己所包含的块列表告知名称节点,此后会定期执行这种告知操作,以确保名称节点的映射是最新的。
EditLog 文件不断变大的问题:
01、在名称节点运行期间,HDFS的所有更新操作都是直接到EditLog,一段时间之后,EditLog文件会变得很大
02、虽然这对名称节点运行时候没有什么明显影响,但是,当名称节点重启时候,名称节点需要先将FsImage里面的所有内容映射到内存,然后一条一条地执行EditLog中的记录,当EditLog文件非常大的时候,
会导致名称节点启动操作会非常的慢
解决方案:使用secondaryNameNode:
节点进程存在于集群的master上,也可以是单独一台机器
作用:
1、NameNode的一个快照
2、周期性备份NameNode
3、记录NameNode中的MateData以及其他数据
4、可以用来恢复NameNode,但是不能替换NameNode
工作原理:

执行流程:
01、SecondaryNameNode节点会定期和NameNode通信,请求其停止使用EditLog,暂时将新的写操作到一个新的文件edit.new上来,这个操作是瞬间完成的。
02、SecondaryNameNode 通过HTTP Get方式从NameNode上获取到FsImage和EditLog文件并下载到本地目录
03、将下载下来的FsImage 和EditLog加载到内存中这个过程就是FsImage和EditLog的合并(checkpoint)
04、合并成功之后,会通过post方式将新的FsImage文件发送NameNode上。
05、Namenode 会将新接收到的FsImage替换掉旧的,同时将edit.new替换EditLog,这样EditLog就会变小。
CheckPoint:
什么时候进行checkpoint由两个参数dfs.namenode.checkpoint.preiod(默认值是3600,即1小时)和dfs.namenode.checkpoint.txns(默认值是1000000)来决定。
period参数表示,经过1小时就进行一次checkpoint,txns参数表示,hdfs经过100万次操作后就要进行checkpoint了。
这两个参数任意一个得到满足,都会触发checkpoint过程。进行checkpoint的节点每隔dfs.namenode.checkpoint.check.period(默认值是60)秒就会去统计一次hdfs的操作次数。
也可以去core-site.xml文件中进行配置:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>
DataNode:
作用:
01、真实数据的存储管理
02、一次写入,并行读取(不修改,仅支持append)
03、文件由数据块组成,Hadoop2.x的块大小默认是128MB,可以自由设置
04、将数据块尽量散布到各个节点
文件解析:
blk_<id>:HDFS的数据块,保存具体的二进制数据
blk_<id>.meta:数据块的属性信息:版本信息、类型信息
可以通过修改 hdfs-site.xml 的 dfs.replication 属性设置产生副本的个数!默认是3!
写入文件的流程:
例如:客户端发送一个请求给NameNode,说它要将“zhou.log”文件写入到HDFS。那么,其执行流程如图1所示。具体为: HDFS写 图1 HDFS写过程示意图

第一步:
客户端发消息给NameNode,说要将“zhou.log”文件写入。(如图1中的①)
第二步:
NameNode发消息给客户端,叫客户端写到DataNode A、B和D,并直接联系DataNode B。(如图1中的②)
第三步:
客户端发消息给DataNode B,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode A和DataNode D。(如图1中的③)
第四步:
DataNode B发消息给DataNode A,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode D。(如图1中的④)
第五步:
DataNode A发消息给DataNode D,叫它保存一份“zhou.log”文件。(如图1中的⑤)
第六步:
DataNode D发确认消息给DataNode A。(如图1中的⑤)
第七步:
DataNode A发确认消息给DataNode B。(如图1中的④)
第八步:
DataNode B发确认消息给客户端,表示写入完成。(如图1中的⑥)
在分布式文件系统的设计中,挑战之一是如何确保数据的一致性。对于HDFS来说,直到所有要保存数据的DataNodes确认它们都有文件的副本时,数据才被认为写入完成。
因此,数据一致性是在写的阶段完成的。一个客户端无论选择从哪个DataNode读取,都将得到相同的数据。
读取文件的流程:
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。
客户端查看之前写入的内容的执行流程如图2所示,具体步骤为:HDFS读写图2 HDFS读过程
示意图:

第一步:
客户端询问NameNode它应该从哪里读取文件。(如图2中的①)
第二步:
NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块ID。) (如图2中的②)
第三步:
客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2中的③)
第四步:
DataNode返回文件内容给客户端,然后关闭连接,完成读操作。(如图2中的④)
客户端并行从不同的DataNode中获取一个文件的数据块,然后联结这些数据块,拼成完整的文件。
HDFS副本存放策略:
副本技术:
副本技术即分布式数据复制技术,是分布式计算的一个重要组成部分。该技术允许数据在多个服务器端共享,一个本地服务器可以存取不同物理地点的远程服务器上的数据,也可以使所有的服务器均持有数据的拷贝。
通过副本技术可以有以下优点:
1、提高系统可靠性:系统不可避免的会产生故障和错误,拥有多个副本的文件系统不会导致无法访问的情况,从而提高了系统的可用性。另外,系统可以通过其他完好的副本对发生错误的副本进行修复,从而提高了系统的容错性。
2、负载均衡:副本可以对系统的负载量进行扩展。多个副本存放在不同的服务器上,可有效的分担工作量,从而将较大的工作量有效的分布在不同的站点上。
3、提高访问效率:将副本创建在访问频度较大的区域,即副本在访问节点的附近,相应减小了其通信开销,从而提高了整体的访问效率。
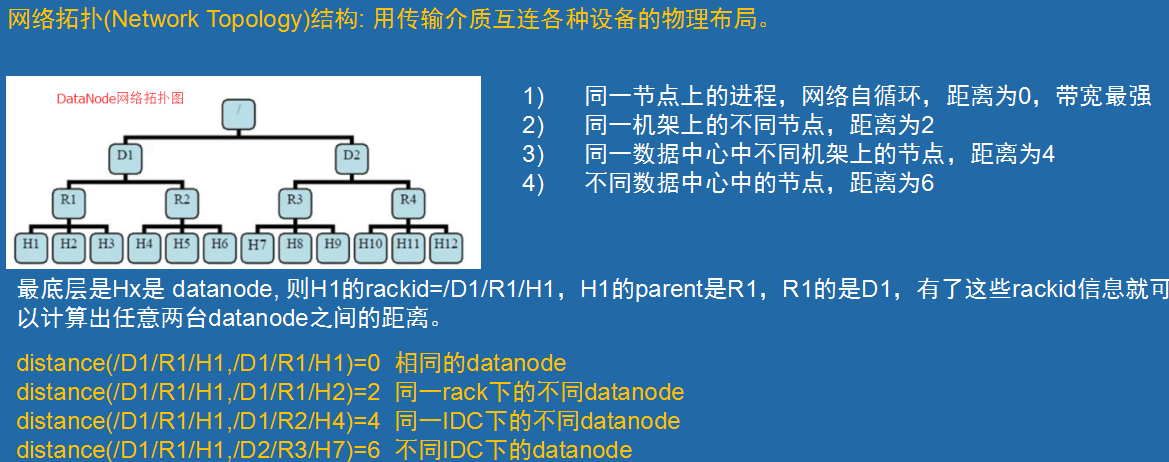
副本存放策略:
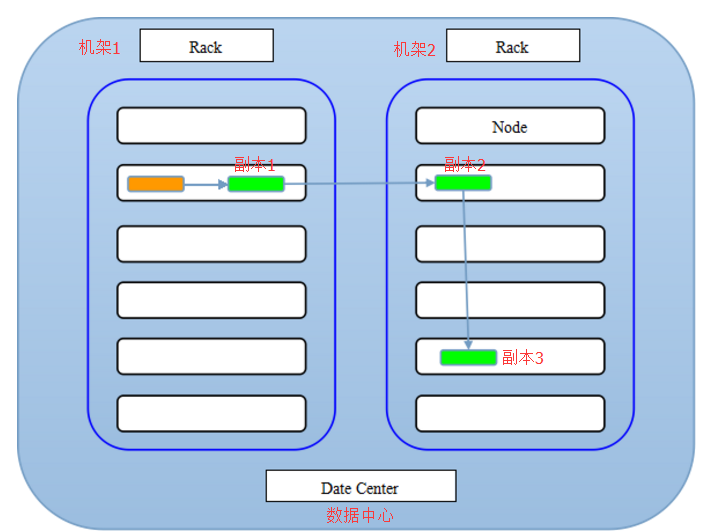
HDFS 的副本放置策略是:
第一个副本放在本地节点,
第二个副本放到不同机架上的一个节点,
第三个副本放到第二个副本同机架上的另外一个节点。
如果还有其他的副本,随机分布在集群中的其他节点!
=====
HDFS 运行在跨越大量机架的集群之上。两个不同机架上的节点是通过交换机实现通信的,在大多数情况下,相同机架上机器间的网络带宽优于在不同机架上的机器。
在开始的时候,每一个数据节点自检它所属的机架 id,然后在向名字节点注册的时候告知它的机架 id。
HDFS 提供接口以便很容易地挂载检测机架标示的模块。
一个简单但不是最优的方式就是将副本放置在不同的机架上,这就防止了机架故障时数据的丢失,并且在读数据的时候可以充分利用不同机架的带宽。
这个方式均匀地将复制分散在集群中,这就简单地实现了组建故障时的负载均衡。然而这种方式增加了写的成本,因为写的时候需要跨越多个机架传输文件块。
一般情况下复制因子(文件的副本数)为 3。
HDFS 的副本放置策略是:
第一个副本放在本地节点,
第二个副本放到不同机架上的一个节点,
第三个副本放到第二个副本同机架上的另外一个节点。
这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的几率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架,而不是三个。
文件的副本不是均匀地分布在机架当中,1/3 副本在同一个节点上,1/3 副本在另一个机架上,另外 1/3 副本均匀地分布在其他机架上。
这种方式提高了写的性能,并且不影响数据的可靠性和读性能。
HDFS 的 Shell 操作:
HDFS 的 API 操作:
Configuration:
Hadoop配置文件的管理类! 我们之前在配置Hadoop集群环境时,可以看到所有xml文件的根节点都是configuration!
FileSystem:
针对于hdfs中文件的一系列操作!比如:创建新文件,删除文件,判断文件是否存在,将本地文件copy到hdfs中等!
FileStatus:
获取文件或者文件夹的元信息!比如:文件路径,文件大小,文件所有者,所在的块大小,文件修改时间,备份数量,权限等!
FSDataInputStream:
输入流对象! 可以将hdfs中的文件或者文件夹读取到本地!
FSDataOutputStream:
输出流对象! 可以将本地的文件或者文件夹上传到hdfs中!
使用API对文件的操作流程:
1、创建项目,引入需要的jar或者pom文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.0</version>
</dependency>
2、获取Configuration==》Hadoop配置文件的管理类!
3、获取FileSystem ==》针对于hdfs中文件的一系列操作!
4、进行文件操作(读写、删除、修改)
5、查询HDFS指定目录下文件
查询HDFS根目录下的所有文件:
public static void main(String[] args) throws IOException {
selectFromPath("/"); //查询HDFS跟目录下 所有文件
}
/**
* @param path 用户需要查询的HDFS中的目录
* @throws IOException
*/
public static void selectFromPath(String path) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//查询 hdfs中根目录下所有的文件
FileStatus[] status = fileSystem.listStatus(new Path(path));
for (FileStatus s:status){
System.out.println("====>"+s);
}
/* 获取单个文件的信息
FileStatus status = fileSystem.getFileStatus(new Path(path));
System.out.println(status);*/
}
输出内容对应的含义:
path=hdfs://master:9000/demo/demo.txt;文件位置
isDirectory=false; 是否是文件夹
length=111; 文件的大小
replication=2; 副本数量
blocksize=134217728; 所在块大小
modification_time=1513047780762; 修改时间1970年到现在的毫秒数
access_time=1513047788225;最后一次访问时间1970年到现在的毫秒数
owner=root; 文件拥有者
group=supergroup; 文件所属组
permission=rw-r--r--; 文件的权限
isSymlink=false是否是连接
在HDFS中创建文件:
public static void main(String[] args) throws IOException {
ceateFile("/demo.txt"); //用户需要创建的文件名称以及路径
}
/**
* @param fileName 用户需要创建的文件名称
* @throws IOException
*/
public static void ceateFile(String fileName) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//创建文件
boolean flag = fileSystem.createNewFile(new Path(fileName));
if (flag){
System.out.println("文件创建成功");
}else {
System.out.println("文件创建失败");
}
}
可能出现的问题:
如果创建文件失败且是权限问题:
Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
解决方案:
01.hadoop fs -chmod 777 /
02.修改hdfs-site.xml 文件中的增加节点
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
在HDFS中创建文件夹:
public static void main(String[] args) throws IOException {
mkdirFile("/demo"); //用户需要创建的文件夹名称以及路径
}
/**
* @param fileName 用户需要创建的文件夹名称
* @throws IOException
*/
public static void mkdirFile(String fileName) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//创建文件夹
boolean flag = fileSystem.mkdirs(new Path(fileName));
if (flag){
System.out.println("文件夹创建成功");
}else {
System.out.println("文件夹创建失败");
}
}
在HDFS中重命名文件或者文件夹:
public static void main(String[] args) throws IOException {
renameFile("/demo","/demo2"); //重命名文件夹
renameFile("/demo.txt","/demo2.txt"); //重命名文件
}
/**
* @param oldName 用户需要重命名的文件夹/文件名称
* @param newName 用户需要重命名的文件夹/文件名称
* @throws IOException
*/
public static void renameFile(String oldName,String newName) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//重命名文件夹
boolean flag = fileSystem.rename(new Path(oldName),new Path(newName));
if (flag){
System.out.println("重命名成功");
}else {
System.out.println("重命名失败");
}
}
在HDFS中删除文件或者文件夹:
public static void main(String[] args) throws IOException {
deleteFile("/demo2"); //删除文件夹
deleteFile("/demo2.txt"); //删除名文件
}
/**
* @param fileName 用户需要删除的文件夹/文件名称
* @throws IOException
*/
public static void deleteFile(String fileName) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//删除文件夹/文件
boolean flag = fileSystem.deleteOnExit(new Path(fileName));
if (flag){
System.out.println("删除成功");
}else {
System.out.println("删除失败");
}
}
本地文件上传到HDFS中:
public static void main(String[] args) throws IOException {
uploadFile("D:/hadoop.txt","/hadoop.txt"); //上传本地文件,也可以改名
uploadFile("D:/hadoop","/hadoop"); //上传本地文件夹,也可以改名
}
/**
* @param localFile 用户需要上传的文件夹/文件名称
* @param desFile 用户需要上传到HDFS中的文件夹/文件名称
* @throws IOException
*/
public static void uploadFile(String localFile,String desFile) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//上传文件夹/文件
fileSystem.copyFromLocalFile(new Path(localFile),new Path(desFile));
//关闭流
fileSystem.close();
}
从HDFS中下载文件或者文件夹到本地:
public static void main(String[] args) throws IOException {
downloadFile("/hadoop.txt","D:/hadoop.txt"); //下载到本地,也可以改名
downloadFile("/hadoop","D:/hadoop"); //下载到本地,也可以改名
}
/**
* @param localFile 用户需要下载到本地的文件夹/文件名称
* @param hdfsFile 用户需要下载的HDFS中的文件夹/文件名称
* @throws IOException
*/
public static void downloadFile(String hdfsFile,String localFile) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//下载文件夹/文件
fileSystem.copyToLocalFile(new Path(hdfsFile),new Path(localFile));
//关闭流
fileSystem.close();
}
下面的这种方式只能下载文件!不能下载文件夹!
public static void main(String[] args) throws IOException {
downloadFile("/hadoop.txt","D:/hadoop.txt"); //下载到本地,也可以改名
}
/**
* @param localFile 用户需要下载到本地的文件名称
* @param hdfsFile 用户需要下载的HDFS中的文件名称
* @throws IOException
*/
public static void downloadFile(String hdfsFile,String localFile) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//创建输入流对象
FSDataInputStream inputStream = fileSystem.open(new Path(hdfsFile));
//创建输出流对象
OutputStream outputStream=new FileOutputStream(localFile);
//下载文件 并且关闭流
IOUtils.copyBytes(inputStream,outputStream,1024,true);
读取文件内容:
public static void main(String[] args) throws IOException {
readFile("/eclipsePut/file1.txt"); //需要读取的文件路径以及名称
}
/**
* @param readFile 需要读取的文件名称
* @throws IOException
*/
public static void readFile(String readFile) throws IOException {
String uri="hdfs://192.168.27.2:9000/";
//实例化配置文件对象
Configuration config=new Configuration();
//创建文件系统对象 实现对文件的操作
FileSystem fileSystem = FileSystem.get(URI.create(uri), config);
//创建输入流对象
FSDataInputStream inputStream = fileSystem.open(new Path(readFile));
//解决中文乱码问题
BufferedReader br=new BufferedReader(new InputStreamReader(inputStream));
String line="";
while ((line=br.readLine())!=null){
System.out.println(line);
}
//关闭流
br.close();
inputStream.close();
fileSystem.close();
}